Clear Sky Science · es
Marco de predicción mejorado por aprendizaje profundo para el rendimiento de bio‑aceite a partir de residuos orgánicos sólidos con características químicamente informadas
Convertir los residuos cotidianos en combustible útil
La basura doméstica, los restos de comida, los desechos agrícolas y los lodos de depuradora suelen convertirse en un problema por el que pagamos para eliminarlos. Sin embargo, todos estos residuos orgánicos están cargados de energía que podría transformarse en combustible líquido, conocido como bio‑aceite. El problema es que los distintos residuos se comportan de forma muy diferente al calentarse, lo que dificulta a los ingenieros saber de antemano cuánto aceite útil obtendrán. Este artículo muestra cómo un modelo de aprendizaje profundo, diseñado con una comprensión química cuidadosa, puede predecir con precisión los rendimientos de bio‑aceite a partir de una amplia mezcla de residuos, ayudando a convertir la basura en un recurso de energía limpia más fiable.
Por qué es tan difícil predecir el bio‑aceite
El bio‑aceite se produce comúnmente mediante un proceso llamado pirólisis, en el que el material orgánico se calienta rápidamente en ausencia de oxígeno. En teoría, esto puede convertir desde pajas de cultivo hasta algas en un líquido que puede transformarse en combustibles y productos químicos. En la práctica, los resultados varían enormemente. La mezcla de carbono, hidrógeno, oxígeno, cenizas (minerales inorgánicos) y humedad difiere entre corrientes de residuos, y los laboratorios emplean reactores y condiciones de calentamiento distintas. Estudios previos de aprendizaje automático intentaron predecir rendimientos, pero a menudo se basaron en conjuntos de datos pequeños y limitados y usaron modelos relativamente simples que luchaban con la química desordenada y no lineal implicada.
Construir un panorama de datos rico y armonizado
Para abordar estos obstáculos, los autores reunieron un conjunto de datos armonizado de 245 casos experimentales extraídos de la literatura, todos centrados en residuos orgánicos sólidos. Cada registro incluye información detallada sobre la composición del material (carbono, hidrógeno, nitrógeno, oxígeno, cenizas, carbono fijo y contenido volátil), la temperatura de pirólisis y otras condiciones de operación, y el rendimiento de bio‑aceite resultante. Un cribado cuidadoso eliminó registros con valores faltantes o poco claros, y todos los rendimientos se convirtieron a una base común para que los números de distintos estudios pudieran compararse de forma justa. Se realizaron comprobaciones estadísticas para entender cómo se relacionaban estas variables y detectar redundancias ocultas que podrían confundir a un algoritmo de aprendizaje.
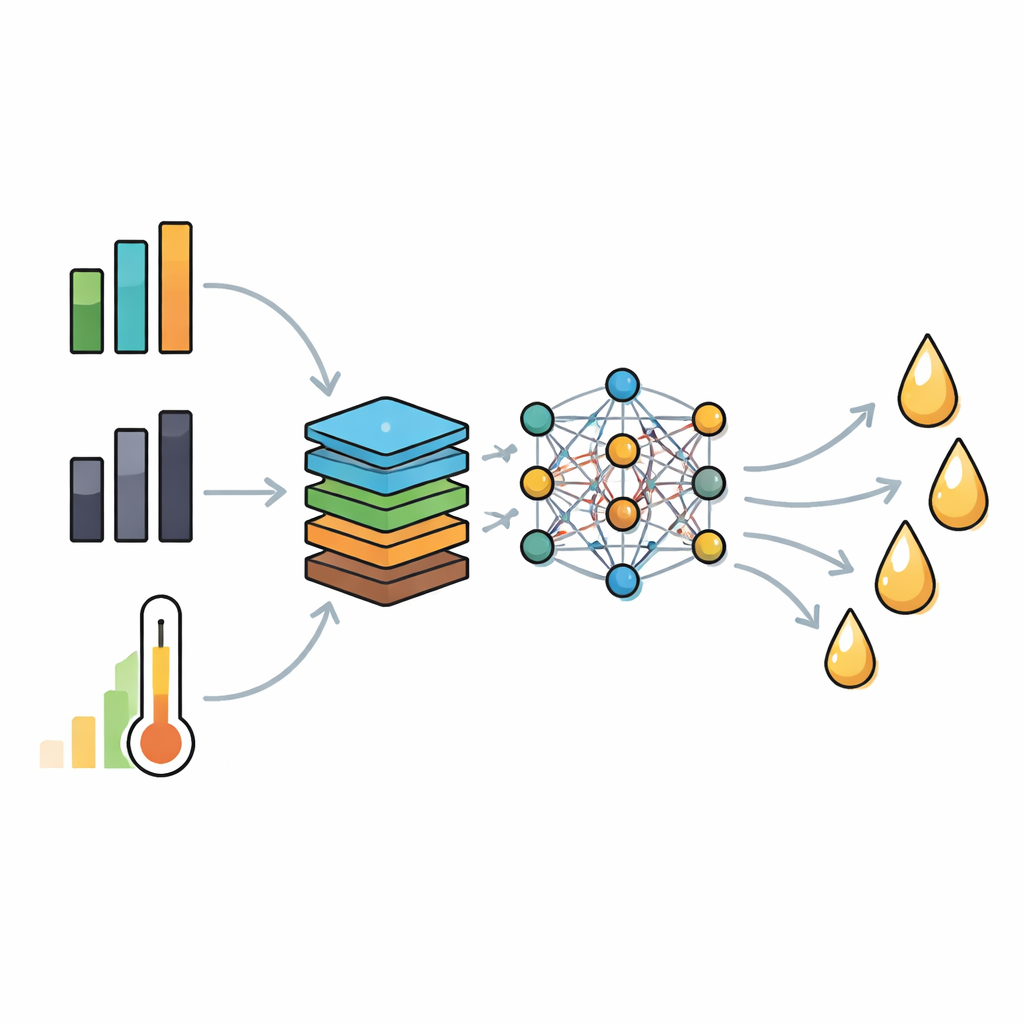
Añadir visión química a los números
En lugar de introducir solo medidas crudas en un modelo, los investigadores diseñaron nuevas características con sentido químico. Crearon razones como hidrógeno‑a‑carbono y oxígeno‑a‑carbono, una medida de cuánto del material se convierte en vapores frente a carbón sólido, una fracción volátil corregida por cenizas que tiene en cuenta los minerales que dificultan la formación de aceite y un índice de densidad energética que resume la riqueza en combustible. Luego aplicaron una técnica llamada análisis de inflación de la varianza para eliminar información superpuesta y mantener un conjunto compacto de nueve entradas clave. Este conjunto reducido de características preserva el significado físico de la química al tiempo que evita los escollos estadísticos que pueden volver inestables a los modelos.
Enseñar a una red neuronal a leer los residuos
Con esta entrada refinada, el equipo entrenó dos tipos de modelos predictivos: una red neuronal profunda y un método popular basado en árboles llamado Light Gradient Boosting. Ambos se ajustaron usando algoritmos de búsqueda avanzados que exploran muchas combinaciones de hiperparámetros, como la tasa de aprendizaje y la profundidad de la red, para encontrar las que mejor se ajustan a los datos. El modelo profundo utilizó finalmente tres capas ocultas y trucos de regularización como dropout y normalización por lotes para evitar el sobreajuste. A lo largo de ciclos repetidos de entrenamiento y prueba, la red profunda optimizada superó consistentemente a los enfoques competidores, alcanzando un coeficiente de determinación (R²) de 0,98 y un error cuadrático medio en torno a poco más de un punto porcentual al predecir nuevos rendimientos de bio‑aceite no vistos.
Qué importa más para producir aceite
Más allá de la precisión bruta, los autores quisieron saber qué aspectos del residuo y del proceso influyen con mayor fuerza en el rendimiento. Un estudio de sensibilidad global mostró que el contenido de carbono, el carbono fijo, las cenizas y la temperatura desempeñan los papeles más importantes, tanto de forma individual como a través de sus interacciones. Un alto contenido volátil y niveles favorables de hidrógeno ayudan, pero sus efectos suelen estar ligados a estas variables principales. Esta clasificación coincide con el entendimiento establecido de la química de la pirólisis: mayor carbono y fracciones volátiles tienden a favorecer la formación de aceite, mientras que altas cenizas y exceso de carbono fijo orientan el material hacia carbón y gas. El acuerdo entre las “opiniones” del modelo y la intuición química aumenta la confianza de que no solo está ajustando ruido.
De predicciones inteligentes a un diseño más inteligente de conversión de residuos a combustible
En términos sencillos, el estudio demuestra que un sistema de aprendizaje profundo bien diseñado, fundamentado en la química real en lugar de la búsqueda ciega de patrones, puede decirnos de antemano cuánto combustible líquido es probable obtener de un residuo orgánico y un conjunto de condiciones de calentamiento dados. Esto facilita la selección de materias primas prometedoras, la elección de ventanas de operación eficientes y la planificación de proyectos de conversión de residuos en energía más ecológicos sin realizar experimentos interminables de ensayo y error. Aunque los autores señalan que conjuntos de datos más grandes y diversos mejorarán aún más la fiabilidad, su marco ya establece un nuevo punto de referencia en rendimiento y apunta el camino hacia el diseño basado en datos de sistemas de producción de bio‑aceite más limpios y predecibles.
Cita: Almansour, S., Alkwai, L.M., Yadav, K. et al. Deep learning enhanced prediction framework for bio oil yield from organic solid waste with chemically informed features. Sci Rep 16, 13667 (2026). https://doi.org/10.1038/s41598-026-43604-7
Palabras clave: predicción de bio‑aceite, residuos orgánicos sólidos, aprendizaje profundo, pirólisis, energía de biomasa