Clear Sky Science · zh
用于自动化产品识别和目录生成的真实世界框架:数据集、模型与分析
为忙碌的购物者打造更智能的货架
任何寻找特定麦片包装或尝试自助结账的人都知道,商店货架往往既拥挤又让人困惑。本文探讨了计算机如何通过普通照片(而非条形码)查看日常杂货货架并自动识别其中的商品。目标是让库存盘点、目录创建甚至手机端商品查询等任务更加快速、低成本,并减少对人工操作的依赖。 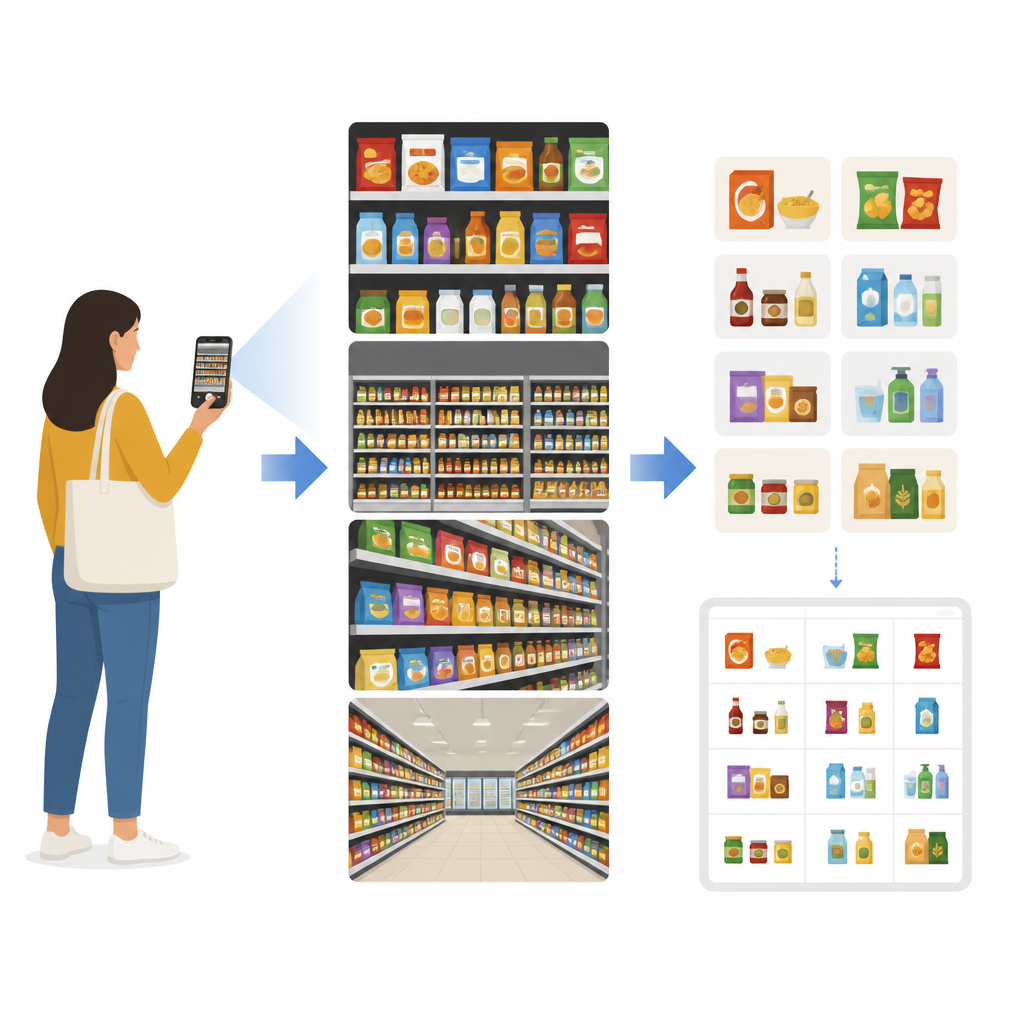
为什么货架对计算机如此困难
乍看之下,教计算机识别商品似乎很简单:只需展示大量每种商品的图片即可。实际上,超市场景很混乱。商品出现在多种尺寸上,从顾客手中的特写到监控摄像头的远景。包装相似、差异体现在细小细节上,且常被部分遮挡。光照变化、货架重排以及不同地区的品牌差异也会造成问题。现有的研究图像集合常常回避这些麻烦,使用数量少的商品、受控光照或仅有特写图像,这使得开发真正能在实际商店中工作的系统变得困难。
一个新的、真实的杂货图像集合
为弥补这一差距,作者构建了名为 Grocer-Help 的新图像集合。它包含 13,771 张照片,展示了约 4,000 种不同的杂货产品,按品牌划分为 349 个类别。图像来自印度五个邦的八家商店,使用六类移动相机拍摄。场景从少量商品的特写到完整过道的远景不等,并包含眩光、运动模糊、杂乱背景和标签部分遮挡等日常情况。每张图像中的每个商品都被精确地用边框标注,总计超过 166,000 件注释项。数据集分为三类主要图像:特写、远景以及干净的在线目录图片,这些组合使研究者能够研究视距和拍摄风格如何影响识别。
一种在多尺度上观察的精简模型
除了数据集外,作者还提出了一种紧凑的检测模型,旨在处理同一场景中各种尺寸的商品。该模型不是分别处理小物体和大物体,而是使用一种特殊模块同时汇集多种尺度的视觉线索。随后把这些线索堆叠成一个特征金字塔,各层关注不同层次的细节。这有助于系统从远处的货架视角一路跟踪到相似包装之间的细微差异。该模型还注重效率:采用更轻量的运算,使其能在计算资源有限的设备上运行,更适合在商店或消费级硬件上部署。 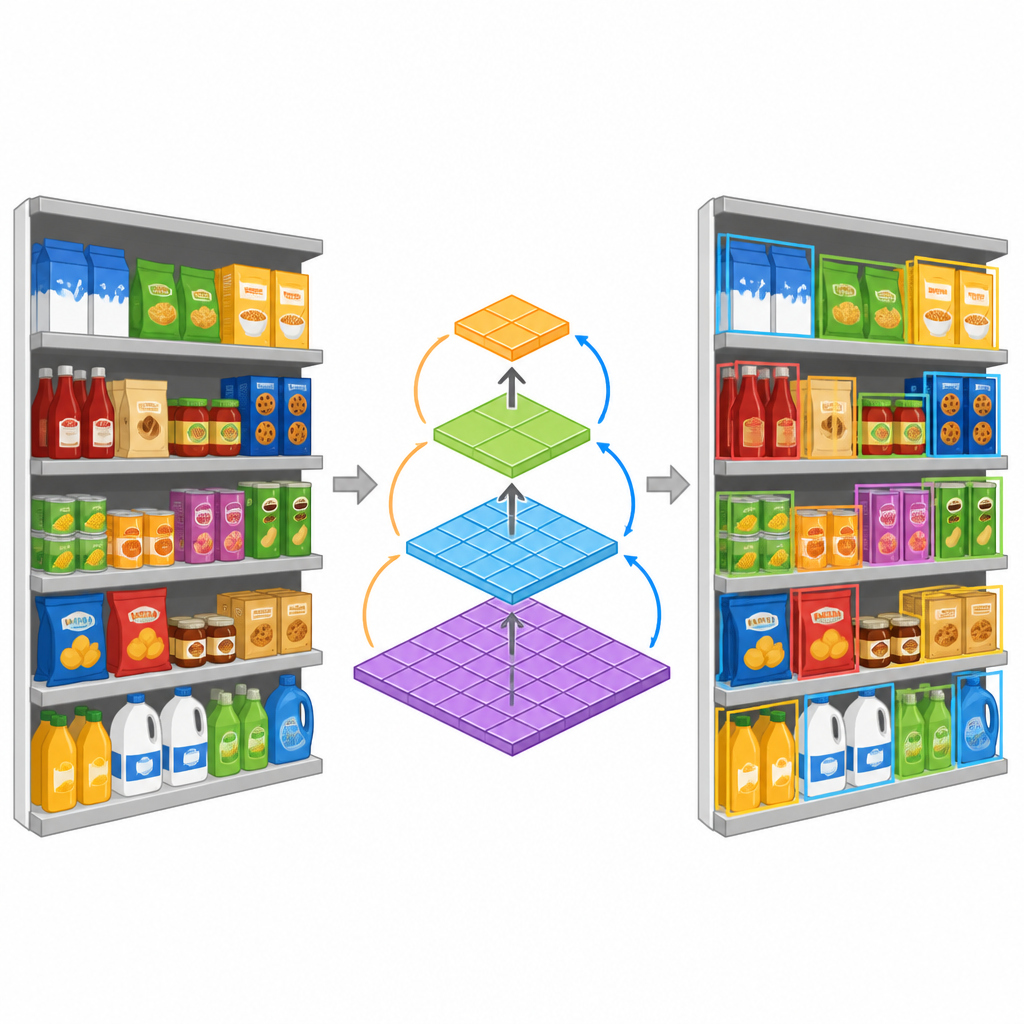
跨数据集、商店与距离的测试
研究者将他们的模型与多种流行的目标检测系统(如不同版本的 YOLO 和 RetinaNet)在若干现有杂货数据集以及 Grocer-Help 上进行了比较。在新数据集上,他们的模型以比许多竞争方法更少的参数达到了稳健的产品检测得分。模型在精确率和召回率上表现尤其强劲,这意味着它既能较好地避免误报,也不易漏检;不过在非常严格的重叠评判下,其边框有时不够紧密。详细测试表明,性能受图像拍摄方式影响:特写图像最容易识别,远距离货架视角更困难,将在线目录图片混入训练可能会损害结果,因为它们与真实店铺场景差异很大。逐店比较还显示,整齐的货架和盒装风格的包装往往有利于检测器的表现。
这对日常零售意味着什么
简单来说,这项工作展示了如何超越传统的条码扫描,转向可以“看见”拥挤货架的基于相机的系统。通过提供一个大规模、真实的数据集和一个能处理不同尺寸与视角商品的高效模型,研究为自动库存检查、基于货架的目录构建以及更智能的移动购物应用等实用工具奠定了基础。尽管在拥挤场景和训练中出现次数很少的产品上仍存在挑战,但 Grocer-Help 与该全尺度模型将自动化产品识别更进一步地推进到了现实零售的日常应用中。
引用: Sah, M., Mathew, J. & Dayananda, P. A real-world framework for automated product recognition and catalog generation: dataset, model, and analysis. Sci Rep 16, 14834 (2026). https://doi.org/10.1038/s41598-026-42266-9
关键词: 杂货产品识别, 目标检测, 计算机视觉零售, 数据集基准, 库存自动化