Clear Sky Science · pl
Ramy rzeczywiste dla zautomatyzowanego rozpoznawania produktów i tworzenia katalogów: zbiór danych, model i analiza
Inteligentniejsze półki sklepowe dla zajętych klientów
Każdy, kto szukał konkretnego pudełka płatków lub próbował obsługi przy kasie samoobsługowej, wie, że półki sklepowe bywają zatłoczone i mylące. W artykule badacze opisują, jak komputery mogą analizować codzienne półki spożywcze i automatycznie rozpoznawać znajdujące się na nich produkty, używając zwykłych zdjęć zamiast kodów kreskowych. Celem jest przyspieszenie i obniżenie kosztów czynności takich jak liczenie zapasów, tworzenie katalogów czy wyszukiwanie produktów przez telefon oraz ograniczenie pracy manualnej. 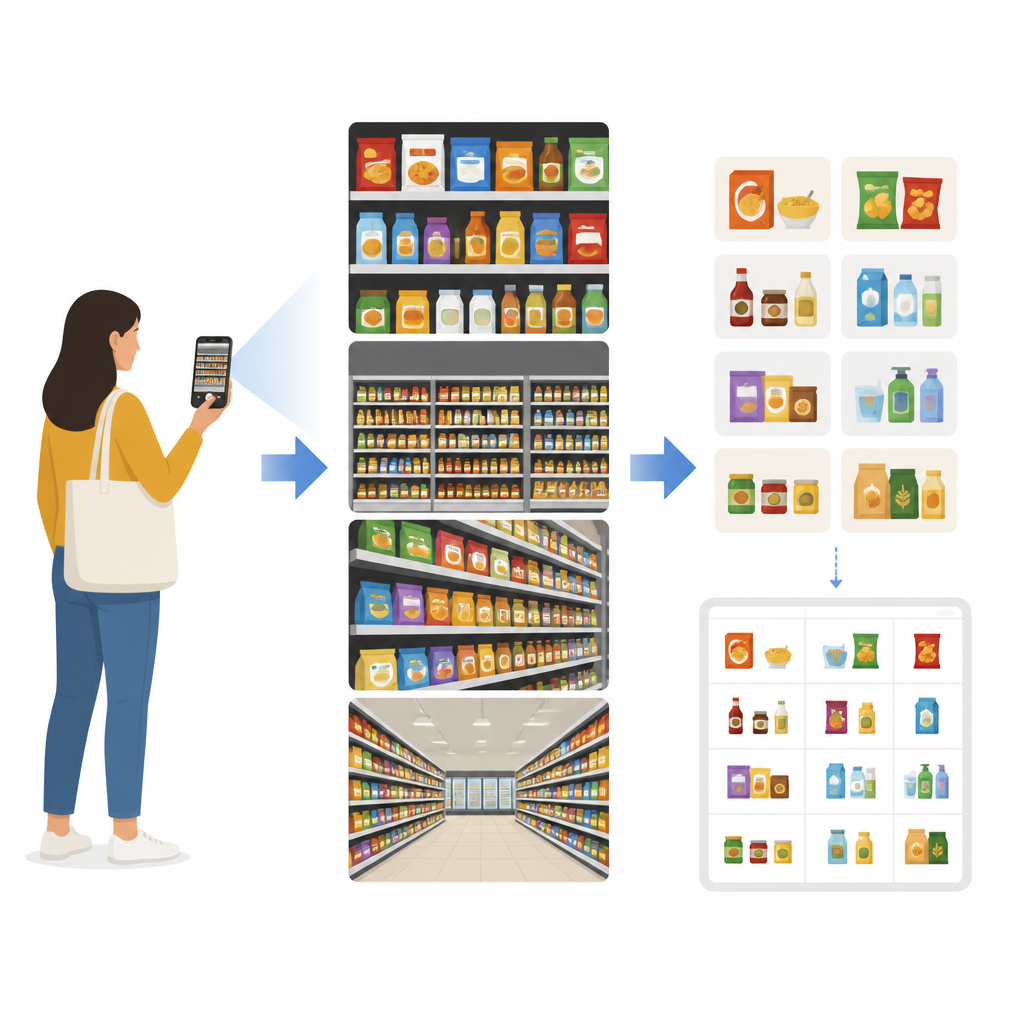
Dlaczego półki są trudne dla komputerów
Początkowo nauczanie komputera rozpoznawania produktów może wydawać się proste: wystarczy pokazać mu dużo zdjęć każdego przedmiotu. W praktyce sceny w supermarketach są jednak chaotyczne. Produkty występują w wielu rozmiarach, od zdjęć z bliska w dłoni klienta po dalekie ujęcia z kamer. Opakowania bywają podobne, różnią się jedynie drobnymi detalami i mogą być częściowo zasłonięte przez inne. Zmienność oświetlenia, przemeblowania półek i różnice między markami w różnych regionach dodatkowo utrudniają zadanie. Istniejące zbiory obrazów do badań często pomijają te problemy, zawierając niewiele produktów, kontrolowane warunki oświetleniowe lub tylko zbliżenia. To utrudnia rozwój systemów działających w prawdziwych sklepach.
Nowy, realistyczny zbiór zdjęć spożywczych
Aby zmniejszyć tę rozbieżność, autorzy zbudowali nowy zbiór zdjęć o nazwie Grocer-Help. Zawiera on 13 771 fotografii przedstawiających około 4 000 różnych produktów spożywczych pogrupowanych w 349 klas opartych na markach. Zdjęcia pochodzą z ośmiu sklepów w pięciu różnych stanach Indii i zostały wykonane sześcioma typami kamer mobilnych. Sceny obejmują ujęcia z bliska kilku produktów oraz dalekie perspektywy całych alejek, i zawierają codzienne niedoskonałości, takie jak odblaski, poruszenie, zagracone tła i częściowe zasłonięcia etykiet. Każdy produkt na zdjęciu jest dokładnie oznaczony ramką, co dało ponad 166 000 opisanych elementów. Zbiór podzielono na trzy główne typy obrazów: ujęcia z bliska, ujęcia z daleka oraz czyste zdjęcia katalogowe z sieci — razem pozwalają one badać, jak odległość i sposób wykonania zdjęcia wpływają na rozpoznawanie.
Szczupły model widzący w wielu skalach
Równolegle do zbioru danych autorzy wprowadzają kompaktowy model detekcji zaprojektowany do radzenia sobie z produktami o różnych rozmiarach w tej samej scenie. Zamiast traktować małe i duże przedmioty oddzielnie, model wykorzystuje specjalny blok konstrukcyjny, który zbiera wskazówki wizualne na kilku skalach jednocześnie. Następnie składa te informacje w piramidę map cech, gdzie każda warstwa koncentruje się na innych poziomach szczegółu. Pomaga to systemowi śledzić produkty od dalekich widoków półek aż po drobne różnice między podobnymi opakowaniami. Model został też zaprojektowany z myślą o efektywności: używa lżejszych operacji, dzięki czemu może działać na urządzeniach o ograniczonej mocy obliczeniowej, co czyni go bardziej odpowiednim do zastosowań w sklepach lub na sprzęcie konsumenckim. 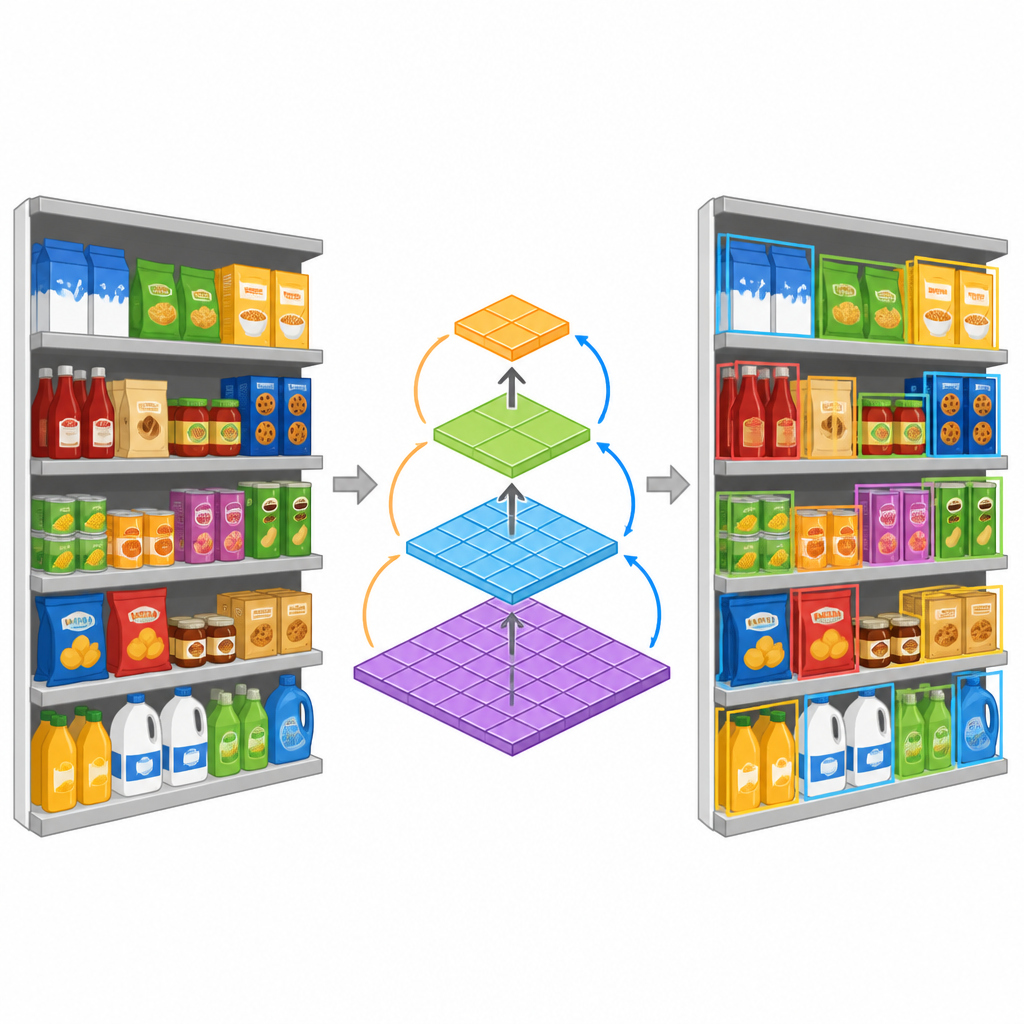
Testy na różnych zbiorach, w sklepach i na różnych odległościach
Badacze porównali swój model z popularnymi systemami detekcji obiektów, takimi jak różne wersje YOLO i RetinaNet, na kilku istniejących zbiorach danych spożywczych oraz na Grocer-Help. Na nowym zbiorze ich model osiąga solidne wyniki w wykrywaniu produktów przy użyciu mniejszej liczby parametrów niż wiele konkurencyjnych rozwiązań. Osiąga szczególnie dobre wartości precyzji i czułości, co oznacza, że skutecznie unika fałszywych alarmów i rzadziej pomija produkty, choć jego ramki bywają czasem mniej ciasne przy bardzo surowych kryteriach nakładania. Szczegółowe testy pokazują, że wydajność zależy od sposobu wykonania zdjęć: ujęcia z bliska są najłatwiejsze, dalekie widoki półek trudniejsze, a włączenie zdjęć katalogowych z internetu do treningu może pogorszyć wyniki, ponieważ wyglądają one inaczej niż rzeczywiste sceny sklepowe. Porównania między sklepami wykazują też, że schludne półki i opakowania w stylu pudełkowym sprzyjają wykrywaczowi.
Co to oznacza dla codziennego handlu detalicznego
Mówiąc prościej, praca ta pokazuje, jak wyjść poza proste skanowanie kodów kreskowych w kierunku systemów opartych na kamerze, które potrafią „zobaczyć” zatłoczone półki sklepowe. Dzięki udostępnieniu dużego, realistycznego zbioru danych i efektywnego modelu radzącego sobie z produktami w różnych rozmiarach i perspektywach, badanie daje podstawy dla praktycznych narzędzi, takich jak automatyczne kontrole zapasów, tworzenie katalogów na podstawie półek czy inteligentniejsze aplikacje mobilne dla zakupów. Mimo że nadal istnieją wyzwania, zwłaszcza na ściśle upchanych półkach i dla produktów widzianych w treningu tylko kilka razy, Grocer-Help i model omni-scale przybliżają zautomatyzowane rozpoznawanie produktów do codziennego użytku w rzeczywistym handlu detalicznym.
Cytowanie: Sah, M., Mathew, J. & Dayananda, P. A real-world framework for automated product recognition and catalog generation: dataset, model, and analysis. Sci Rep 16, 14834 (2026). https://doi.org/10.1038/s41598-026-42266-9
Słowa kluczowe: rozpoznawanie produktów spożywczych, detekcja obiektów, widzenie komputerowe w handlu detalicznym, benchmark zbioru danych, automatyzacja inwentaryzacji