Clear Sky Science · de
Ein praxisnaher Rahmen für automatisierte Produkterkennung und Katalogerstellung: Datensatz, Modell und Analyse
Intelligentere Ladenregale für vielbeschäftigte Kundinnen
Wer schon einmal nach einer bestimmten Müslischachtel gesucht oder die Selbstbedienungskasse genutzt hat, weiß: Regale sind überfüllt und verwirrend. Dieses Paper untersucht, wie Computer alltägliche Lebensmittelregale betrachten und automatisch erkennen können, was dort steht — anhand normaler Fotos statt Barcodes. Ziel ist es, Aufgaben wie Inventurzählungen, Katalogerstellung und sogar die Produktsuche per Telefon schneller, kostengünstiger und weniger von manueller Arbeit abhängig zu machen. 
Warum Regale für Computer schwierig sind
Auf den ersten Blick klingt es vielleicht einfach, einem Computer Produkte beizubringen: man zeigt ihm viele Bilder jedes Artikels. In Wirklichkeit sind Supermarktszenen unordentlich. Produkte erscheinen in vielen Größen, von Nahaufnahmen in der Hand einer Kundin bis zu Fernaufnahmen von Überwachungskameras. Verpackungen ähneln sich, unterscheiden sich oft nur durch kleine Details und können teilweise hinter anderen versteckt sein. Lichtverhältnisse ändern sich, Regale werden umgeräumt, und Marken variieren je nach Region. Bestehende Bildsammlungen für die Forschung umgehen viele dieser Probleme oft, indem sie nur wenige Produkte, kontrollierte Beleuchtung oder ausschließlich Nahaufnahmen verwenden. Das erschwert die Entwicklung von Systemen, die wirklich in echten Läden funktionieren.
Eine neue, realistische Sammlung von Lebensmittelbildern
Um diese Lücke zu schließen, haben die Autorinnen und Autoren eine neue Bildsammlung namens Grocer-Help erstellt. Sie enthält 13.771 Bilder mit etwa 4.000 verschiedenen Lebensmittelprodukten, gruppiert in 349 markenbasierten Klassen. Die Bilder stammen aus acht Läden in fünf indischen Bundesstaaten und wurden mit sechs Kameratypen von Mobilgeräten aufgenommen. Die Szenen reichen von Nahaufnahmen einiger weniger Artikel bis zu Fernaufnahmen ganzer Gänge und beinhalten alltägliche Eigenheiten wie Reflexionen, Bewegungsunschärfe, unruhige Hintergründe und teilweise verdeckte Etiketten. Jedes Produkt in einem Bild ist sorgfältig mit einer Begrenzungsbox versehen, was zu mehr als 166.000 annotierten Objekten führt. Der Datensatz ist in drei Hauptbildtypen aufgeteilt: Nahaufnahmen, Fernaufnahmen und saubere Online-Katalogbilder, die zusammen erlauben, zu untersuchen, wie Betrachtungsdistanz und Aufnahmeart die Erkennung beeinflussen.
Ein schlankes Modell, das in vielen Maßstäben sieht
Begleitend zum Datensatz stellen die Autorinnen und Autoren ein kompaktes Detektionsmodell vor, das darauf ausgelegt ist, Produkte in vielen Größen innerhalb derselben Szene zu erfassen. Anstatt kleine und große Objekte getrennt zu behandeln, nutzt das Modell einen speziellen Baustein, der visuelle Hinweise gleichzeitig über mehrere Skalen sammelt. Diese Hinweise werden dann zu einer Pyramide von Merkmalfeldern gestapelt, wobei jede Ebene unterschiedliche Detailstufen fokussiert. Das hilft dem System, Produkte von weit entfernten Regalansichten bis hin zu feinen Unterschieden zwischen ähnlichen Verpackungen zu verfolgen. Das Modell ist zudem effizient konstruiert: Es verwendet leichtere Operationen, sodass es auf Geräten mit begrenzter Rechenleistung laufen kann — was es besser geeignet macht für den Einsatz in Läden oder auf Consumer-Hardware. 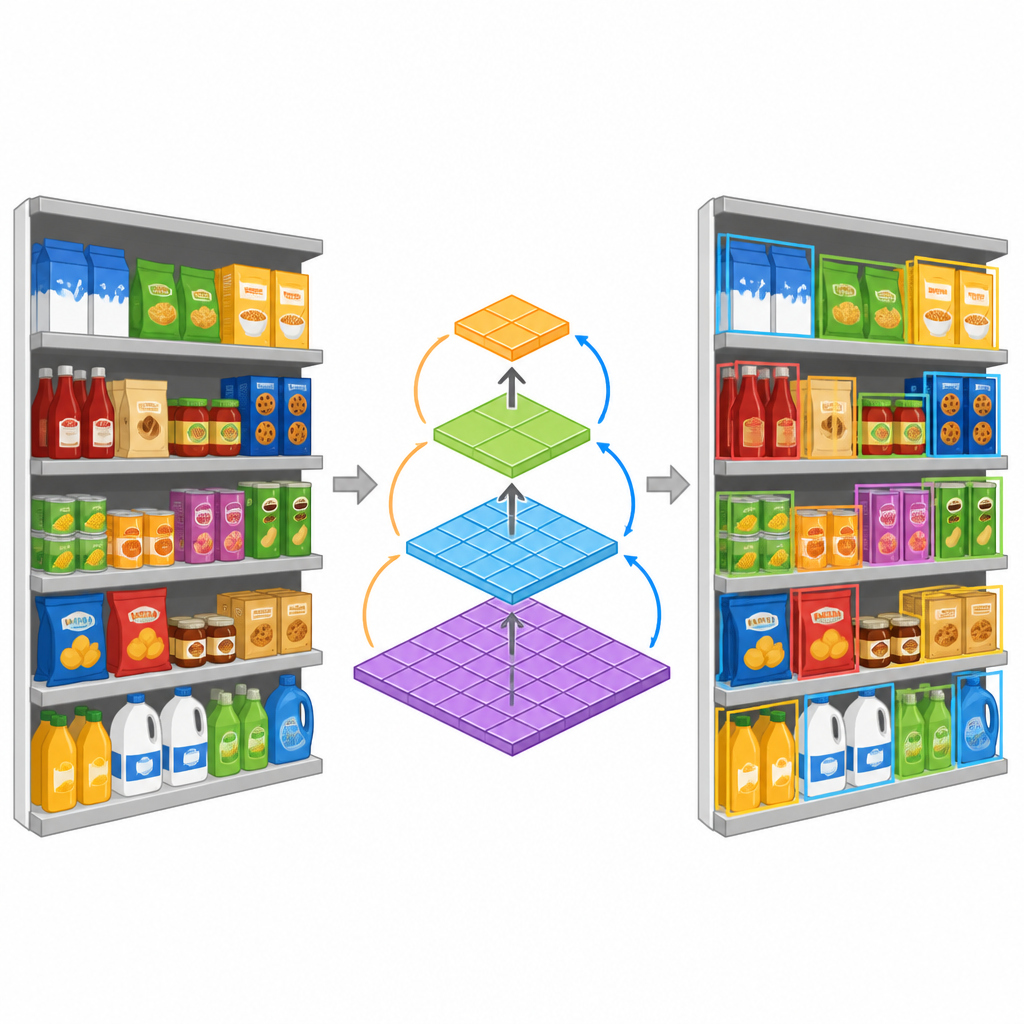
Tests über Datensätze, Läden und Entfernungen hinweg
Die Forschenden vergleichen ihr Modell mit gängigen Objekterkennungssystemen wie verschiedenen Versionen von YOLO und RetinaNet auf mehreren existierenden Lebensmitteldatensätzen und auf Grocer-Help. Auf dem neuen Datensatz erreicht ihr Modell eine solide Leistung beim korrekten Auffinden von Produkten, während es weniger Parameter verwendet als viele Konkurrenzmethoden. Es erzielt besonders starke Präzision und Trefferquote, das heißt, es vermeidet Fehlalarme und verpasst wenige Artikel, obwohl seine Begrenzungsboxen bei sehr strengen Überlappungsregeln manchmal weniger eng sind. Detaillierte Tests zeigen, dass die Leistung davon abhängt, wie die Bilder aufgenommen wurden: Nahaufnahmen sind am einfachsten, Fernaufnahmen von Regalen sind schwieriger, und das Mischen von Online-Katalogbildern ins Training kann die Ergebnisse verschlechtern, weil diese deutlich anders aussehen als echte Ladenszenen. Laden-zu-Laden-Vergleiche zeigen außerdem, dass ordentliche Regale und schachtelartige Verpackungen dem Detektor tendenziell helfen.
Was das für den Alltag im Einzelhandel bedeutet
Einfach gesagt zeigt diese Arbeit, wie man über einfache Barcodescanner hinauskommt hin zu kamerabasierten Systemen, die volle Ladenregale „sehen“ können. Indem sie einen großen, realistischen Datensatz und ein effizientes Modell bereitstellen, das Produkte in unterschiedlichen Größen und Blickwinkeln verarbeitet, legt die Studie die Grundlage für praktische Werkzeuge wie automatische Bestandsprüfungen, regalseitige Katalogerstellung und intelligentere Shopping-Apps auf dem Mobiltelefon. Zwar gibt es weiterhin Herausforderungen, besonders bei dicht gepackten Szenen und bei Produkten, die im Training nur selten vorkommen, doch bringen Grocer-Help und das Omni-Scale-Modell die automatisierte Produkterkennung näher an den praktischen Einsatz im Einzelhandel.
Zitation: Sah, M., Mathew, J. & Dayananda, P. A real-world framework for automated product recognition and catalog generation: dataset, model, and analysis. Sci Rep 16, 14834 (2026). https://doi.org/10.1038/s41598-026-42266-9
Schlüsselwörter: Erkennung von Lebensmittelprodukten, Objekterkennung, Computer Vision im Einzelhandel, Datensatz-Benchmark, Automatisierung von Beständen