Clear Sky Science · zh
一种可解释的 AI 驱动混合特征选择方法用于冠状动脉疾病诊断
这为何与您的心脏息息相关
冠状动脉疾病是许多心肌梗死背后的病因,但它常常在严重损伤发生前悄然存在。医生有许多检查手段,但很多检查昂贵、侵入性强或难以获得,尤其在中低收入国家更是如此。本文探讨一种新型的可解释人工智能,如何在常规医疗信息中筛选出高风险人群,使用更少的测量项,同时仍向医生揭示哪些体征确实重要。
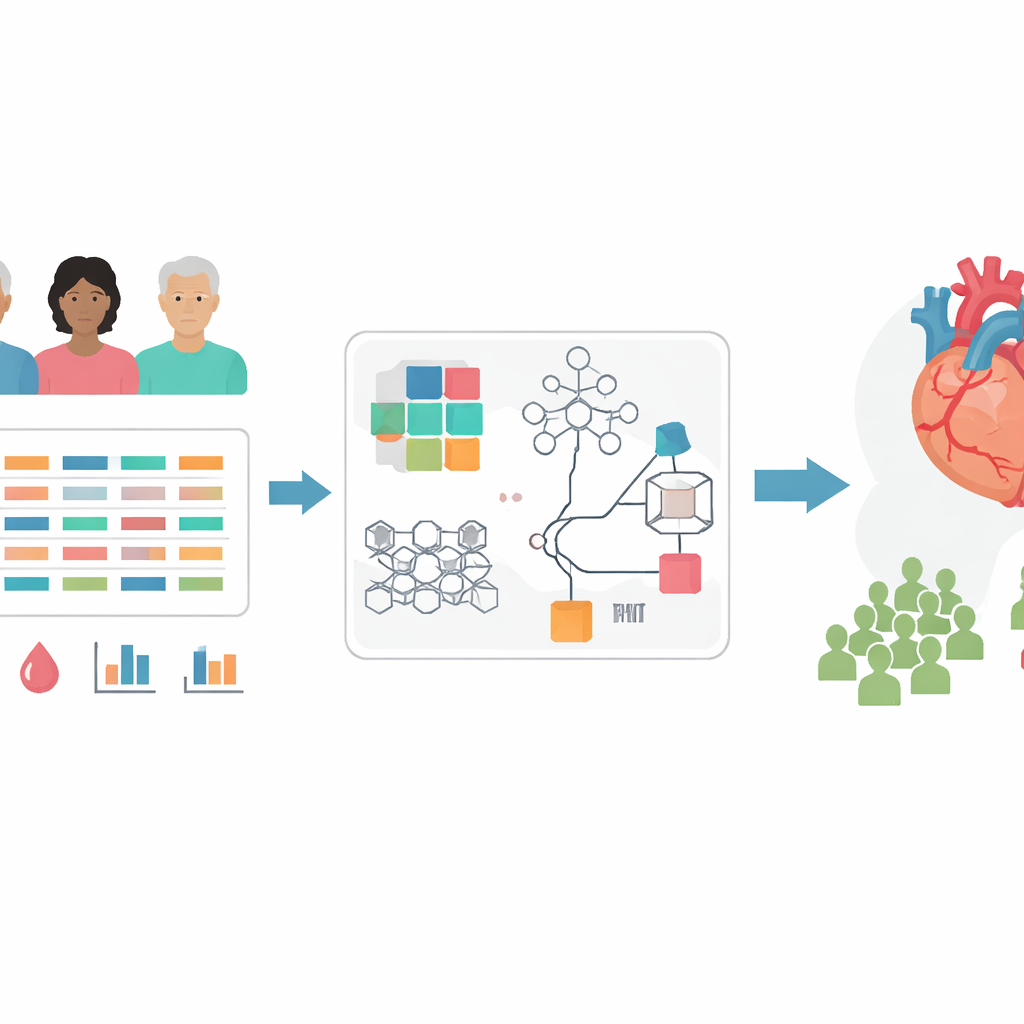
信息过多的问题
现代医学可以为每位心脏患者测量数十项特征:年龄、血压、化验值、症状以及影像或心电等检查结果。但并非所有线索同样有用。使用太多弱或冗余的测量项反而可能混淆计算模型、降低运行速度并使预测不够可靠。早期研究尝试过多种精简方法,但没有单一方法始终表现最佳,而且多数方法像黑盒一样,几乎无法解释为何保留或丢弃某个特征。
一种更聪明的线索挑选方式
作者提出了一种名为 SHOW(SHAP Optimized Wrapper,SHAP 优化包装器)的两步法来应对这一问题。首先,他们使用一种可解释的 AI 技术——SHAP,评估每个医学特征对预测冠状动脉疾病的贡献程度。他们针对三种从不同角度处理问题的强分类器分别进行评估。然后将这三种视角融合为一个稳定的特征排名,避免依赖单一模型的特性,从而得到从最有信息量到最无用的有序临床线索清单。
构建精简且准确的预测模型
在第二步中,SHOW 按排名逐步构建每个分类器的特征集。它从排名最高的特征开始训练模型,然后按序加入下一个特征。如果加入新特征提升了准确性,则保留;否则就剔除。该过程持续进行,直到不再有改进为止。与此同时,数据经过谨慎处理:删除缺失条目,使用常见的过采样方法平衡少见的疾病样本,并对数值变量进行缩放,以免某一测量仅因取值范围较大而主导结果。
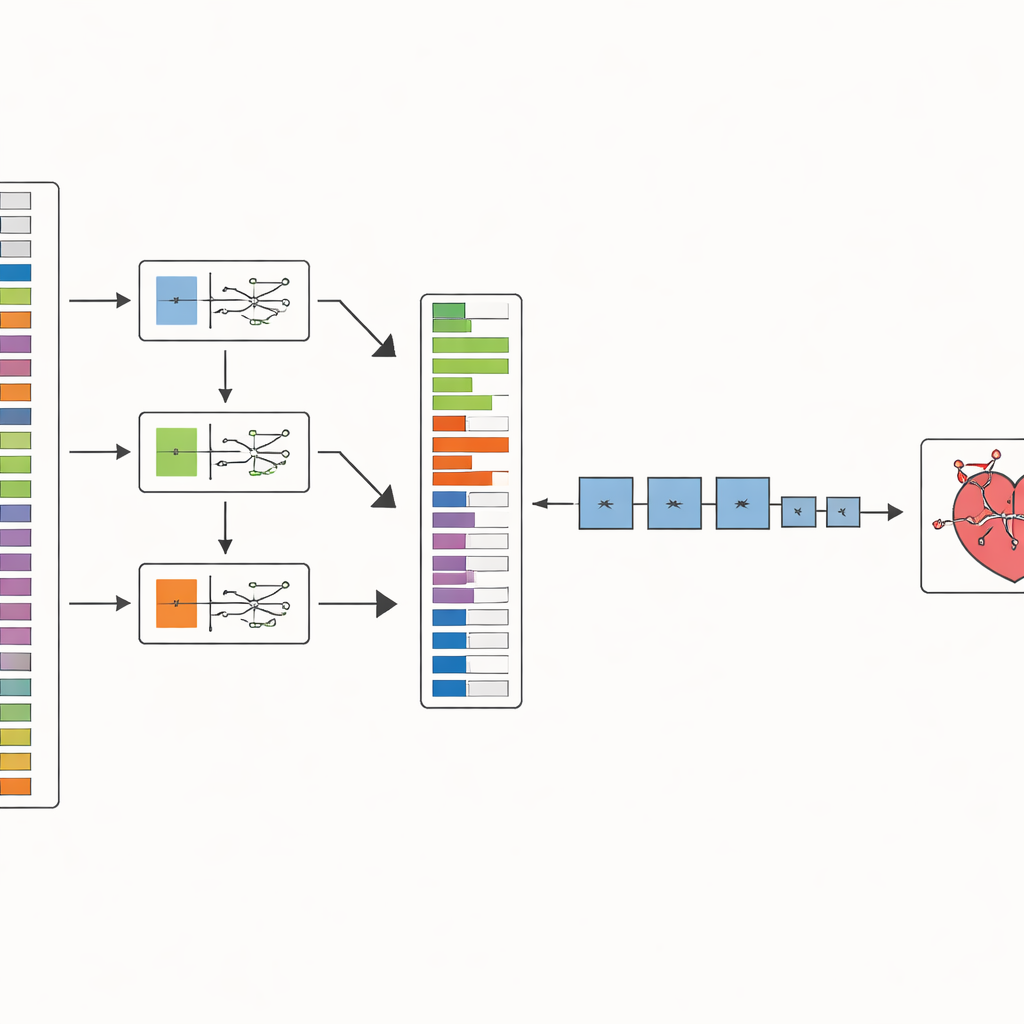
将方法付诸检验
为验证 SHOW 是否真有帮助,团队在三组知名的冠状动脉疾病数据集上进行了测试,这些数据集在规模、复杂性以及患病比例上各不相同。他们尝试了七种流行的机器学习模型,从简单的逻辑回归到更先进的随机森林和 XGBoost 等技术。对于每个数据集,他们比较了使用全部可用特征与仅使用 SHOW 选出的特征的表现,并在交叉验证框架中多次重复测试以避免侥幸结果。他们不仅记录总体正确率,还评估模型漏诊病人的情况以及在健康与患病案例之间的区分度。
真实患者数据中的发现
在所有三组数据集中,SHOW 持续让 XGBoost 模型在使用更少输入的情况下达到或超过文献中报告的最好结果。例如,在一个包含 55 个临床特征的数据集中,SHOW 将特征缩减到 14 项,但仍实现约 94% 的准确率和同样很高的敏感性,意味着大多数患病患者被正确识别。在另外两个各含 13 项特征的数据集中,该方法仅选出 5 项特征,同时将准确率保持在约 86–88% 左右。实践上,这表明经过明智选择的一小部分测量项——例如特定类型的胸痛、关键化验结果和某些影像学征象——就能承担大部分诊断信息量。
展望更简洁、更清晰的心脏筛查
该研究表明,可解释人工智能不仅能做出预测,还能澄清哪些日常临床体征对冠状动脉疾病诊断确实重要。通过识别一小组高价值的测量项,SHOW 有望支持更便宜、更快速且仍高度可靠的筛查工具,同时对临床医生更透明。尽管该方法计算量大,需要在非常大规模数据集上进一步优化,但它为开发更智能、更易理解的 AI 助手提供了有前景的路径,帮助医生在不被海量数据淹没的情况下更早发现心脏疾病。
引用: Elemam, T., Refaat, H. & Makhlouf, M. An explainable AI-driven hybrid feature selection approach for coronary artery disease diagnosis. Sci Rep 16, 10411 (2026). https://doi.org/10.1038/s41598-026-41712-y
关键词: 冠状动脉疾病, 可解释人工智能, 特征选择, 医学诊断, 机器学习