Clear Sky Science · fr
Une approche hybride de sélection de caractéristiques pilotée par une IA explicable pour le diagnostic de la maladie coronaire
Pourquoi cela importe pour votre cœur
La maladie coronarienne est à l’origine de nombreux infarctus, et pourtant elle reste souvent invisible jusqu’à l’apparition de lésions graves. Les médecins disposent de nombreux tests, mais beaucoup sont coûteux, invasifs ou difficiles d’accès, en particulier dans les pays à revenu faible ou intermédiaire. Cet article explore comment une nouvelle forme d’intelligence artificielle explicable peut trier les informations médicales de routine pour repérer les personnes à risque, en utilisant moins de mesures tout en donnant aux cliniciens un aperçu des signes qui comptent réellement.
Le problème de l’excès d’informations
La médecine moderne peut mesurer des dizaines de caractéristiques pour chaque patient cardiaque : âge, tension artérielle, résultats de laboratoire, symptômes et conclusions d’imageries ou d’enregistrements cardiaques. Mais toutes ces indications ne se révèlent pas également utiles. Utiliser trop de mesures faibles ou redondantes peut en réalité embrouiller les modèles informatiques, les ralentir et rendre leurs prédictions moins fiables. Des études antérieures ont testé de nombreuses manières de réduire cette liste, mais aucune méthode unique n’a fait ses preuves systématiquement, et la plupart fonctionnaient comme des boîtes noires, offrant peu d’explication sur les raisons pour lesquelles une caractéristique était conservée ou écartée.
Une manière plus intelligente de choisir les bons indices
Les auteurs proposent une méthode en deux étapes appelée SHOW (SHAP Optimized Wrapper) pour affronter ce problème. D’abord, ils utilisent une technique d’IA explicable connue sous le nom de SHAP pour estimer la contribution de chaque caractéristique médicale à la prédiction de la maladie coronarienne. Ils effectuent cette estimation séparément pour trois modèles d’apprentissage automatique performants qui abordent le problème de façons différentes. Ils fusionnent ensuite ces trois points de vue en un classement stable des caractéristiques, afin de ne pas dépendre des particularités d’un seul modèle. Cela produit une liste ordonnée, des indices cliniques les plus informatifs aux moins utiles.
Construire des modèles prédictifs sobres et précis
Dans la seconde étape, SHOW parcourt cette liste classée et construit progressivement un jeu de caractéristiques pour chaque classificateur. On commence par la caractéristique la mieux classée, on entraîne un modèle, puis on ajoute la suivante. Si l’ajout d’une nouvelle caractéristique améliore la précision, elle est conservée ; sinon, elle est rejetée. Le processus se poursuit jusqu’à ce qu’aucun gain supplémentaire ne soit observé. En parallèle, les données sont préparées avec soin : les entrées manquantes sont supprimées, les cas rares de la maladie sont équilibrés à l’aide d’une technique standard de suréchantillonnage, et les valeurs numériques sont mises à l’échelle pour qu’aucune mesure ne domine simplement à cause de son amplitude brute.
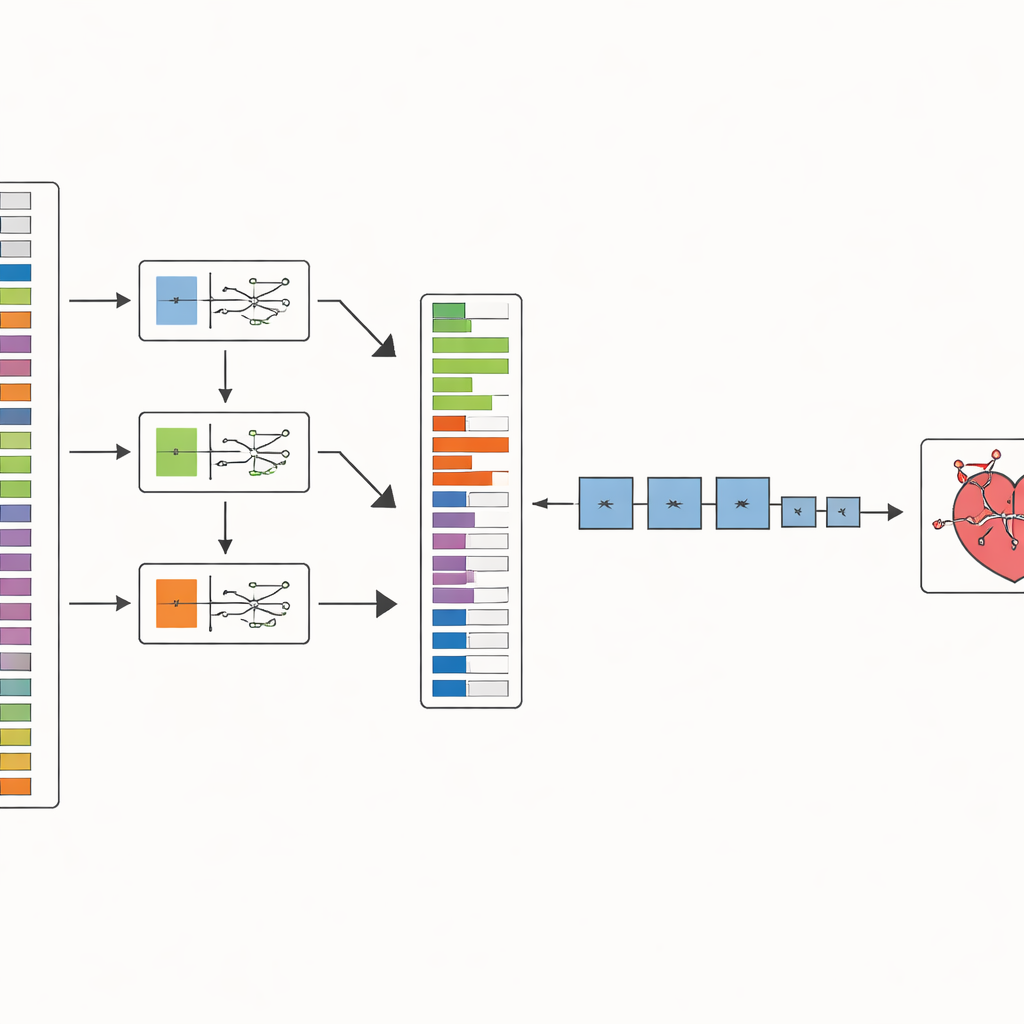
Mettre la méthode à l’épreuve
Pour vérifier si SHOW apporte réellement un bénéfice, l’équipe l’a testée sur trois jeux de données bien connus sur la maladie coronarienne, qui diffèrent par leur taille, leur complexité et la prévalence de la maladie. Ils ont évalué sept modèles d’apprentissage automatique populaires, de la simple régression logistique à des techniques plus avancées comme les forêts aléatoires et XGBoost. Pour chaque jeu de données, ils ont comparé les performances en utilisant toutes les caractéristiques disponibles versus uniquement celles choisies par SHOW, répétant les tests de nombreuses fois dans un schéma de validation croisée pour éviter les résultats dus au hasard. Ils ont suivi non seulement la justesse globale, mais aussi la capacité des modèles à ne pas manquer les patients malades et à séparer clairement les cas sains des cas malades.
Ce qu’ils ont trouvé dans des données réelles de patients
Sur les trois jeux de données, SHOW a systématiquement permis au modèle XGBoost d’atteindre ou de dépasser les meilleurs résultats rapportés dans la littérature tout en utilisant beaucoup moins d’entrées. Par exemple, dans un jeu de données comportant 55 caractéristiques cliniques, SHOW a réduit la liste à 14 et obtenu environ 94 % de précision et une sensibilité également élevée, ce qui signifie que la plupart des patients atteints ont été correctement identifiés. Dans deux autres jeux de données de 13 caractéristiques chacun, la méthode n’a retenu que 5 caractéristiques tout en maintenant une précision d’environ 86–88 %. En termes pratiques, cela suggère qu’un petit nombre de mesures ciblées — comme certains types de douleur thoracique, des résultats de laboratoire clés et des signes d’imagerie particuliers — peuvent porter l’essentiel du poids diagnostique lorsqu’elles sont bien choisies.
Vers des bilans cardiaques plus simples et plus clairs
L’étude montre que l’IA explicable peut faire plus que produire des prédictions : elle peut aider à clarifier quels signes cliniques courants sont réellement importants pour le diagnostic de la maladie coronarienne. En identifiant un petit ensemble de mesures à forte valeur ajoutée, SHOW pourrait soutenir des outils de dépistage moins coûteux et plus rapides, tout en restant très fiables et plus transparents pour les cliniciens. Bien que l’approche soit gourmande en calcul et doive être optimisée pour des jeux de données très volumineux, elle ouvre une voie prometteuse vers des assistants IA plus intelligents et compréhensibles, qui aident les médecins à détecter plus tôt les maladies cardiaques sans se noyer dans les données.
Citation: Elemam, T., Refaat, H. & Makhlouf, M. An explainable AI-driven hybrid feature selection approach for coronary artery disease diagnosis. Sci Rep 16, 10411 (2026). https://doi.org/10.1038/s41598-026-41712-y
Mots-clés: maladie coronarienne, IA explicable, sélection de caractéristiques, diagnostic médical, apprentissage automatique