Clear Sky Science · de
Ein erklärbarer, KI-gestützter hybrider Merkmalsauswahl-Ansatz zur Diagnostik der koronaren Herzkrankheit
Warum das für Ihr Herz wichtig ist
Die koronare Herzkrankheit ist die Ursache vieler Herzinfarkte, verbirgt sich aber oft bis zu dem Zeitpunkt, an dem ernster Schaden entsteht. Ärztinnen und Ärzte haben zwar viele Tests zur Verfügung, doch viele sind teuer, invasiv oder schwer zugänglich, insbesondere in Ländern mit niedrigem und mittlerem Einkommen. Diese Arbeit untersucht, wie eine neue Form erklärbarer künstlicher Intelligenz routinemäßige medizinische Informationen durchsuchen kann, um Risikopersonen zu identifizieren, dabei weniger Messungen zu verwenden und Ärzten gleichzeitig Einblick zu geben, welche Hinweise wirklich wichtig sind.
Das Problem zu vieler Informationen
Die moderne Medizin kann für jeden Herzpatienten Dutzende Merkmale messen: Alter, Blutdruck, Laborwerte, Symptome sowie Befunde aus Bildgebung und Herzkurven. Doch nicht alle diese Hinweise sind gleichermaßen nützlich. Zu viele schwache oder überflüssige Messungen können Modelle verwirren, verlangsamen und ihre Vorhersagen weniger zuverlässig machen. Frühere Studien versuchten zahlreiche Methoden zur Reduktion dieser Listen, doch keine einzelne Methode funktionierte stets am besten, und die meisten agierten wie Black Boxes, die kaum erklären, warum ein bestimmtes Merkmal beibehalten oder verworfen wurde.
Eine klügere Methode, die richtigen Hinweise zu wählen
Die Autorinnen und Autoren schlagen eine zweistufige Methode namens SHOW (SHAP Optimized Wrapper) vor, um dieses Problem anzugehen. Zuerst nutzen sie eine erklärbare KI-Technik namens SHAP, um abzuschätzen, wie stark jedes medizinische Merkmal zur Vorhersage der koronaren Herzkrankheit beiträgt. Das erfolgt getrennt für drei starke Modelle des maschinellen Lernens, die das Problem auf unterschiedliche Weise angehen. Anschließend verbinden sie diese drei Sichtweisen zu einer stabilen Rangfolge der Merkmale, sodass sie sich nicht auf die Eigenheiten eines einzelnen Modells verlassen. So entsteht eine geordnete Liste von den informativsten klinischen Hinweisen bis zu den am wenigsten nützlichen.
Schlanke und genaue Vorhersagemodelle aufbauen
Im zweiten Schritt geht SHOW diese Rangliste durch und baut schrittweise für jeden Klassifikator einen Merkmalsatz auf. Es beginnt mit dem obersten Merkmal, trainiert ein Modell und fügt dann nacheinander das nächste Merkmal hinzu. Verbessert ein neues Merkmal die Genauigkeit, bleibt es; tut es das nicht, wird es verworfen. Dieser Vorgang läuft so lange, bis keine weiteren Verbesserungen erzielt werden. Dabei werden die Daten sorgfältig vorbereitet: fehlende Einträge werden entfernt, seltene Krankheitsfälle mit einer gängigen Oversampling-Methode ausgeglichen und numerische Werte skaliert, damit keine einzelne Messung allein wegen ihres Zahlenbereichs dominiert.
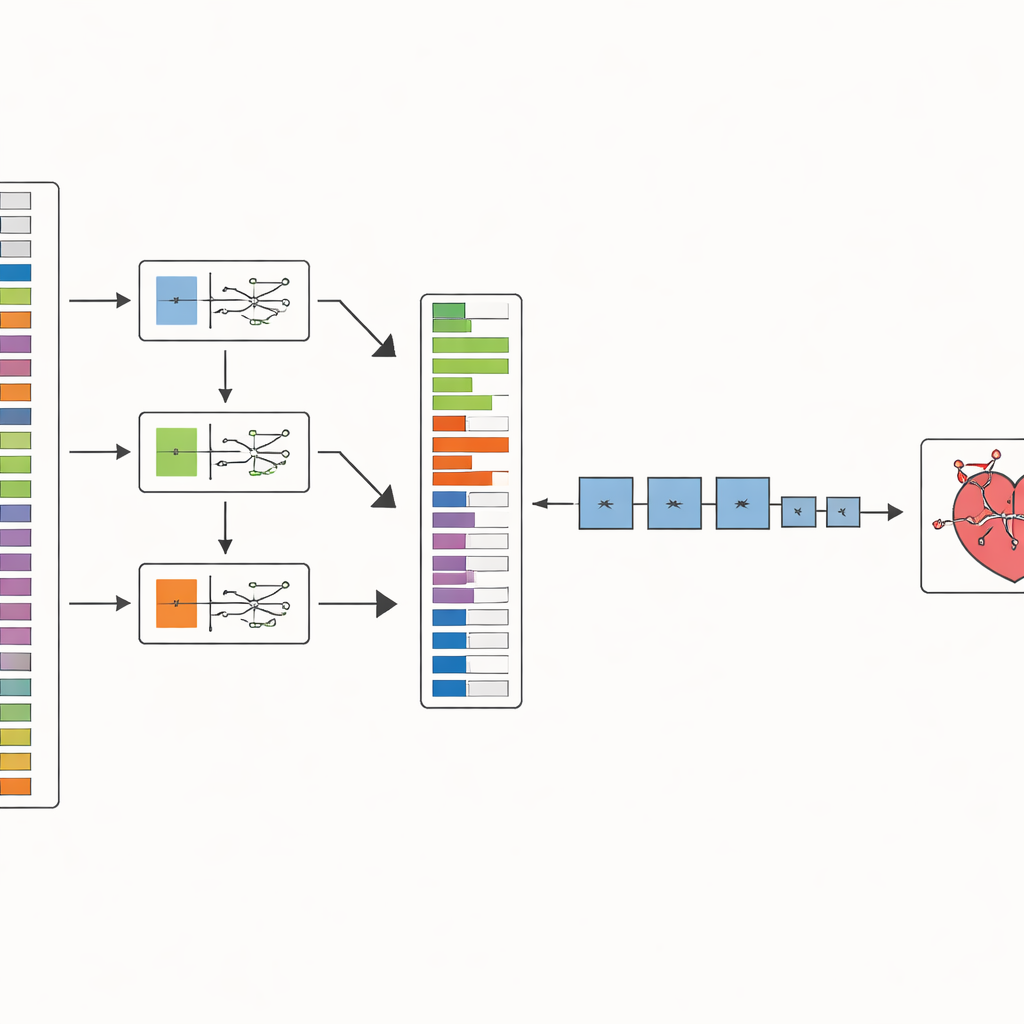
Die Methode auf die Probe stellen
Um zu prüfen, ob SHOW tatsächlich hilft, testete das Team die Methode an drei bekannten Datensätzen zur koronaren Herzkrankheit, die sich in Größe, Komplexität und Anteil erkrankter Patienten unterscheiden. Sie erprobten sieben gängige Modelle des maschinellen Lernens, von einfacher logistischer Regression bis zu fortgeschritteneren Verfahren wie Random Forests und XGBoost. Für jeden Datensatz verglichen sie die Leistung mit allen verfügbaren Merkmalen gegenüber nur den von SHOW ausgewählten, wobei die Tests mehrfach in einem Kreuzvalidierungsschema wiederholt wurden, um Zufallstreffer zu vermeiden. Sie verfolgten nicht nur die Gesamtgenauigkeit, sondern auch, wie gut die Modelle kranke Patienten nicht übersehen und wie klar sie gesunde von erkrankten Fällen trennen.
Was sie in realen Patientendaten fanden
Über alle drei Datensätze hinweg ermöglichte SHOW dem XGBoost-Modell durchweg, die besten in der Literatur berichteten Ergebnisse zu erreichen oder zu übertreffen, während deutlich weniger Eingaben verwendet wurden. Beispielsweise reduzierte SHOW in einem Datensatz mit 55 klinischen Merkmalen die Liste auf 14 und erzielte dabei etwa 94 % Genauigkeit und ähnlich hohe Sensitivität, was bedeutet, dass die meisten erkrankten Patienten korrekt erkannt wurden. In zwei anderen Datensätzen mit jeweils 13 Merkmalen wählte die Methode nur 5 Merkmale aus und hielt die Genauigkeit bei etwa 86–88 %. Praktisch zeigt das, dass eine gezielte Handvoll Messungen — etwa bestimmte Arten von Brustschmerzen, zentrale Laborwerte und bestimmte Bildgebungsbefunde — den größten Teil des diagnostischen Gewichts tragen kann, wenn sie klug ausgewählt sind.
Ausblick: Einfachere, klarere Herzchecks
Die Studie zeigt, dass erklärbare KI mehr leisten kann als reine Vorhersagen: Sie kann helfen zu klären, welche alltäglichen klinischen Zeichen tatsächlich für die Diagnose der koronaren Herzkrankheit relevant sind. Indem sie eine kleine, besonders aussagekräftige Menge an Messungen identifiziert, könnte SHOW günstigere und schnellere Screening-Instrumente unterstützen, die dennoch sehr zuverlässig sind und für Kliniker transparenter bleiben. Zwar ist der Ansatz rechnerisch aufwendig und muss für sehr große Datensätze optimiert werden, doch er bietet einen vielversprechenden Weg zu intelligenteren, besser nachvollziehbaren KI-Assistenten, die Ärztinnen und Ärzten helfen, Herzkrankheiten früher zu erkennen, ohne in Daten zu ertrinken.
Zitation: Elemam, T., Refaat, H. & Makhlouf, M. An explainable AI-driven hybrid feature selection approach for coronary artery disease diagnosis. Sci Rep 16, 10411 (2026). https://doi.org/10.1038/s41598-026-41712-y
Schlüsselwörter: koronare Herzkrankheit, erklärbare KI, Merkmalsauswahl, medizinische Diagnostik, maschinelles Lernen