Clear Sky Science · pt
Uma abordagem híbrida explicável orientada por IA para seleção de características no diagnóstico de doença arterial coronariana
Por que isso é importante para o seu coração
A doença arterial coronariana é a causa por trás de muitos ataques cardíacos, mas frequentemente permanece oculta até que danos sérios ocorram. Os médicos dispõem de muitos exames, porém muitos são caros, invasivos ou de difícil acesso, especialmente em países de baixa e média renda. Este artigo investiga como um novo tipo de inteligência artificial explicável pode vasculhar informações médicas rotineiras para identificar quem está em risco, usando menos medições e ainda oferecendo aos médicos clareza sobre quais sinais realmente importam.
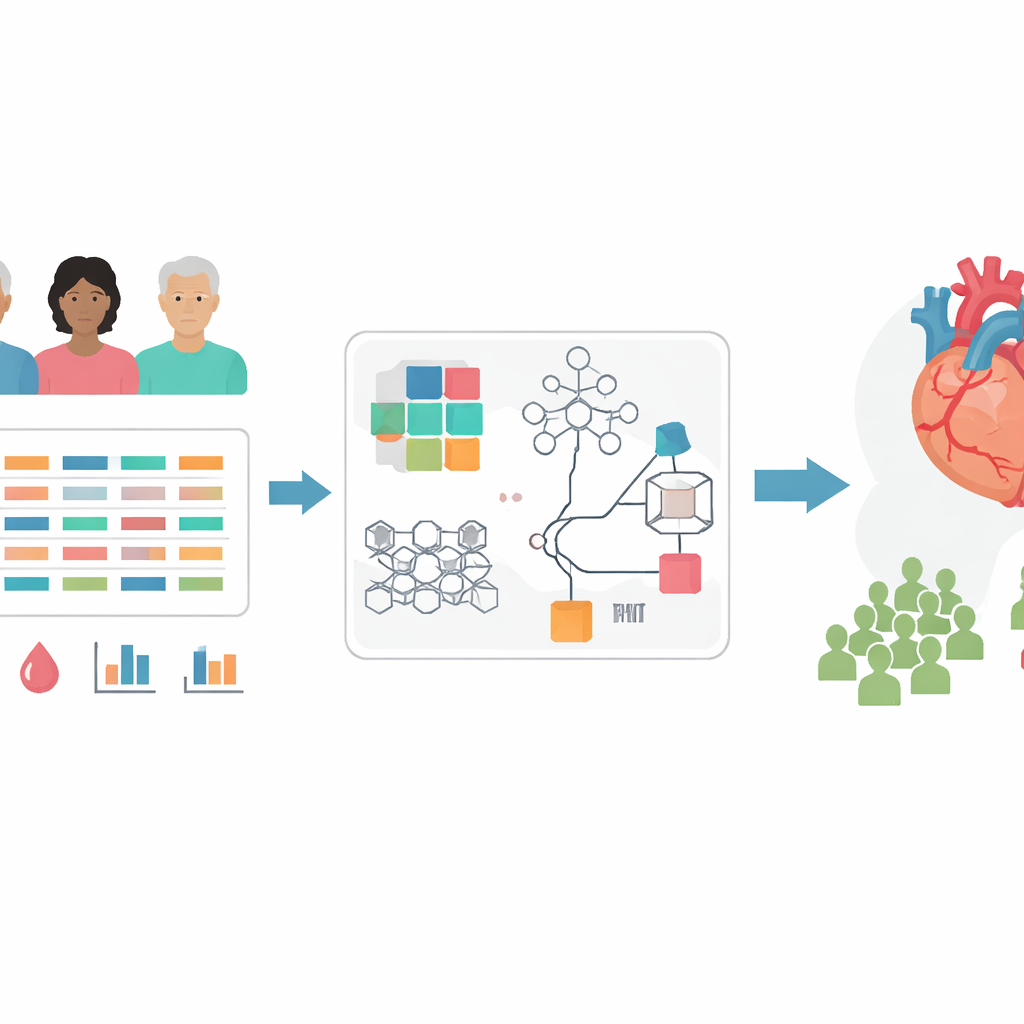
O problema do excesso de informação
A medicina moderna pode medir dezenas de características para cada paciente cardíaco: idade, pressão arterial, valores laboratoriais, sintomas e achados de exames de imagem e traçados cardíacos. Mas nem todas essas pistas são igualmente úteis. Usar muitas medições fracas ou redundantes pode confundir modelos computacionais, torná-los mais lentos e diminuir a confiabilidade das previsões. Estudos anteriores testaram várias formas de reduzir essa lista, mas nenhum método isolado funcionou de forma consistente como o melhor, e a maioria atuava como caixas-pretas, oferecendo pouca explicação sobre por que uma determinada característica era mantida ou descartada.
Uma maneira mais inteligente de escolher as pistas certas
Os autores propõem um método em duas etapas chamado SHOW (SHAP Optimized Wrapper) para enfrentar essa questão. Primeiro, eles usam uma técnica de IA explicável conhecida como SHAP para estimar quanto cada característica clínica contribui para prever a doença arterial coronariana. Fazem isso separadamente para três modelos fortes de aprendizado de máquina que abordam o problema de maneiras diferentes. Em seguida, combinam essas três visões em um único ranking estável de características, de modo a não depender das peculiaridades de um único modelo. Isso gera uma lista ordenada das pistas clínicas mais informativas até as menos úteis.
Construindo modelos preditivos enxutos e precisos
Na segunda etapa, o SHOW percorre essa lista ordenada e constrói gradualmente um conjunto de características para cada classificador. Começa-se pela característica mais importante, treina-se um modelo e então adiciona-se a seguinte na lista. Se a inclusão de uma nova característica melhora a acurácia, ela permanece; caso contrário, é descartada. O processo continua até que não se observe mais ganho. No decorrer, os dados são cuidadosamente preparados: entradas ausentes são removidas, casos raros da doença são equilibrados usando uma técnica padrão de oversampling e os valores numéricos são escalados para que nenhuma medição domine apenas por sua escala bruta.
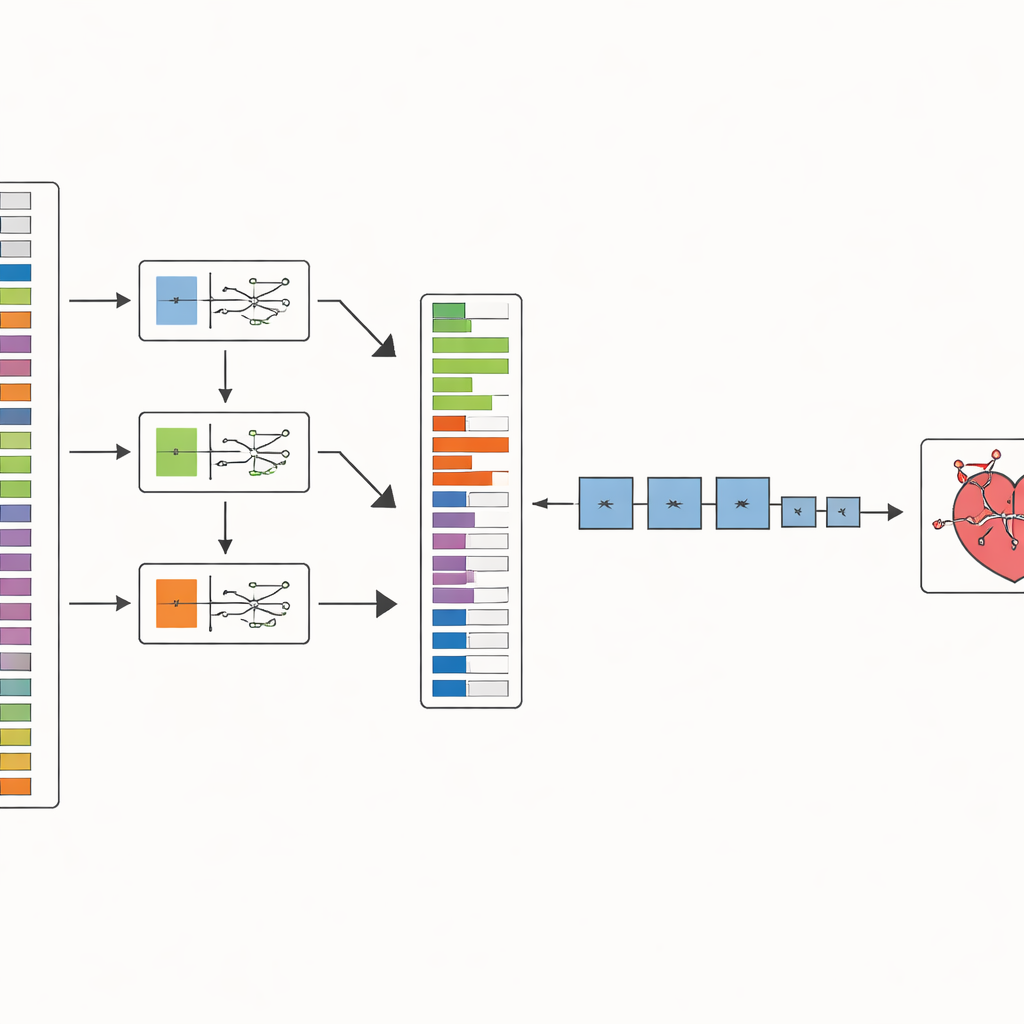
Testando o método
Para verificar se o SHOW realmente ajuda, a equipe o testou em três conjuntos de dados bem conhecidos sobre doença arterial coronariana que diferem em tamanho, complexidade e na proporção de pacientes com a doença. Eles experimentaram sete modelos populares de aprendizado de máquina, desde regressão logística simples até técnicas mais avançadas, como florestas aleatórias e XGBoost. Para cada conjunto, compararam o desempenho usando todas as características disponíveis versus apenas aquelas escolhidas pelo SHOW, repetindo os testes muitas vezes em um esquema de validação cruzada para evitar resultados por sorte. Também acompanharam não só a correção geral, mas como os modelos evitavam deixar de identificar pacientes doentes e o quão bem separavam casos saudáveis dos doentes.
O que encontraram em dados reais de pacientes
Ao longo dos três conjuntos de dados, o SHOW permitiu consistentemente que o modelo XGBoost atingisse ou superasse os melhores resultados relatados na literatura usando muito menos entradas. Por exemplo, em um conjunto com 55 características clínicas, o SHOW reduziu a lista para 14 e ainda alcançou cerca de 94% de acurácia e sensibilidade igualmente alta, o que significa que a maioria dos pacientes com a doença foi corretamente assinalada. Em outros dois conjuntos com 13 características cada, o método selecionou apenas 5 características mantendo a acurácia em torno de 86–88%. Em termos práticos, isso sugere que um pequeno conjunto focado de medições — como tipos específicos de dor torácica, resultados laboratoriais chave e sinais de imagem particulares — pode carregar a maior parte do peso diagnóstico quando escolhidos com critério.
Olhando adiante para avaliações cardíacas mais simples e claras
O estudo mostra que a IA explicável pode fazer mais do que apenas gerar previsões; ela pode ajudar a esclarecer quais sinais clínicos cotidianos realmente importam para o diagnóstico de doença arterial coronariana. Ao apontar um pequeno conjunto de medições de alto valor, o SHOW pode apoiar ferramentas de triagem mais baratas e rápidas que continuam sendo altamente confiáveis e mais transparentes para os clínicos. Embora a abordagem seja computacionalmente exigente e precise ser otimizada para conjuntos de dados muito grandes, oferece um caminho promissor para assistentes de IA mais inteligentes e compreensíveis que ajudam os médicos a detectar a doença cardíaca mais cedo sem se afogarem em dados.
Citação: Elemam, T., Refaat, H. & Makhlouf, M. An explainable AI-driven hybrid feature selection approach for coronary artery disease diagnosis. Sci Rep 16, 10411 (2026). https://doi.org/10.1038/s41598-026-41712-y
Palavras-chave: doença arterial coronariana, IA explicável, seleção de características, diagnóstico médico, aprendizado de máquina