Clear Sky Science · nl
Een uitlegbare, door AI aangedreven hybride methode voor kenmerkselectie bij de diagnose van coronaire hartziekte
Waarom dit belangrijk is voor uw hart
Coronaire hartziekte is de oorzaak van veel hartaanvallen, maar blijft vaak onopgemerkt totdat er ernstige schade is. Artsen hebben veel tests tot hun beschikking, maar veel daarvan zijn duur, invasief of moeilijk toegankelijk, vooral in lage- en middeninkomenslanden. Dit artikel onderzoekt hoe een nieuw soort uitlegbare kunstmatige intelligentie routine medische gegevens kan doorzoeken om te ontdekken wie risico loopt, met minder metingen terwijl artsen toch inzicht krijgen in welke signalen echt van belang zijn.
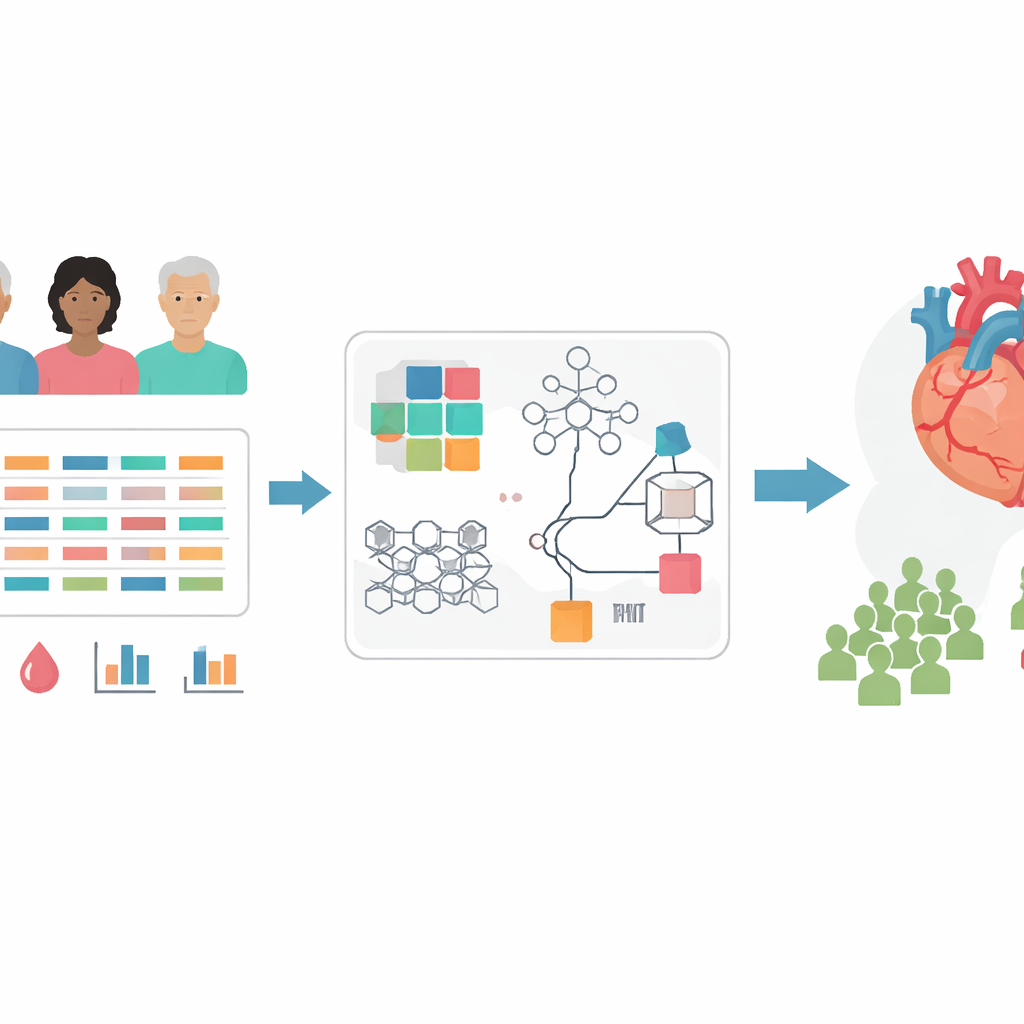
Het probleem van te veel informatie
De moderne geneeskunde kan tientallen kenmerken meten van elke hartpatiënt: leeftijd, bloeddruk, laboratoriumwaarden, symptomen en bevindingen uit scans en hartfilmpjes. Maar niet al deze aanwijzingen zijn even nuttig. Het gebruik van te veel zwakke of redundante metingen kan computersystemen juist verwarren, vertragen en hun voorspellingen minder betrouwbaar maken. Eerdere studies probeerden vele manieren om deze lijst in te korten, maar geen enkele methode werkte consequent het beste, en de meeste fungeerden als black boxes die weinig uitleg gaven waarom een bepaald kenmerk wel of niet werd behouden.
Een slimmer manier om de juiste aanwijzingen te kiezen
De auteurs stellen een tweestapsmethode voor genaamd SHOW (SHAP Optimized Wrapper) om dit probleem aan te pakken. Eerst gebruiken ze een uitlegbare AI-techniek bekend als SHAP om te schatten hoeveel elk medisch kenmerk bijdraagt aan het voorspellen van coronaire hartziekte. Ze doen dit apart voor drie sterke machine learning-modellen die het probleem op verschillende manieren benaderen. Vervolgens combineren ze deze drie gezichtspunten tot één stabiele rangorde van kenmerken, zodat ze niet afhankelijk zijn van de eigenaardigheden van één enkel model. Dat levert een geordende lijst op van de meest informatieve klinische aanwijzingen tot de minst nuttige.
Zuinig en nauwkeurig voorspellingsmodellen bouwen
In de tweede stap loopt SHOW deze gerangschikte lijst af en bouwt geleidelijk een set kenmerken voor elke classifier. Het begint met het bovenste kenmerk, traint een model en voegt vervolgens het volgende kenmerk toe. Als het toevoegen van een nieuw kenmerk de nauwkeurigheid verbetert, blijft het; zo niet, dan wordt het verworpen. Dit gaat door totdat geen verdere verbeteringen meer worden waargenomen. Ondertussen worden de gegevens zorgvuldig voorbereid: ontbrekende waarden worden verwijderd, zeldzame ziektegevallen worden in balans gebracht met een gebruikelijke oversampling-techniek en numerieke waarden worden geschaald zodat geen enkele meting domineert alleen vanwege zijn ruwe bereik.
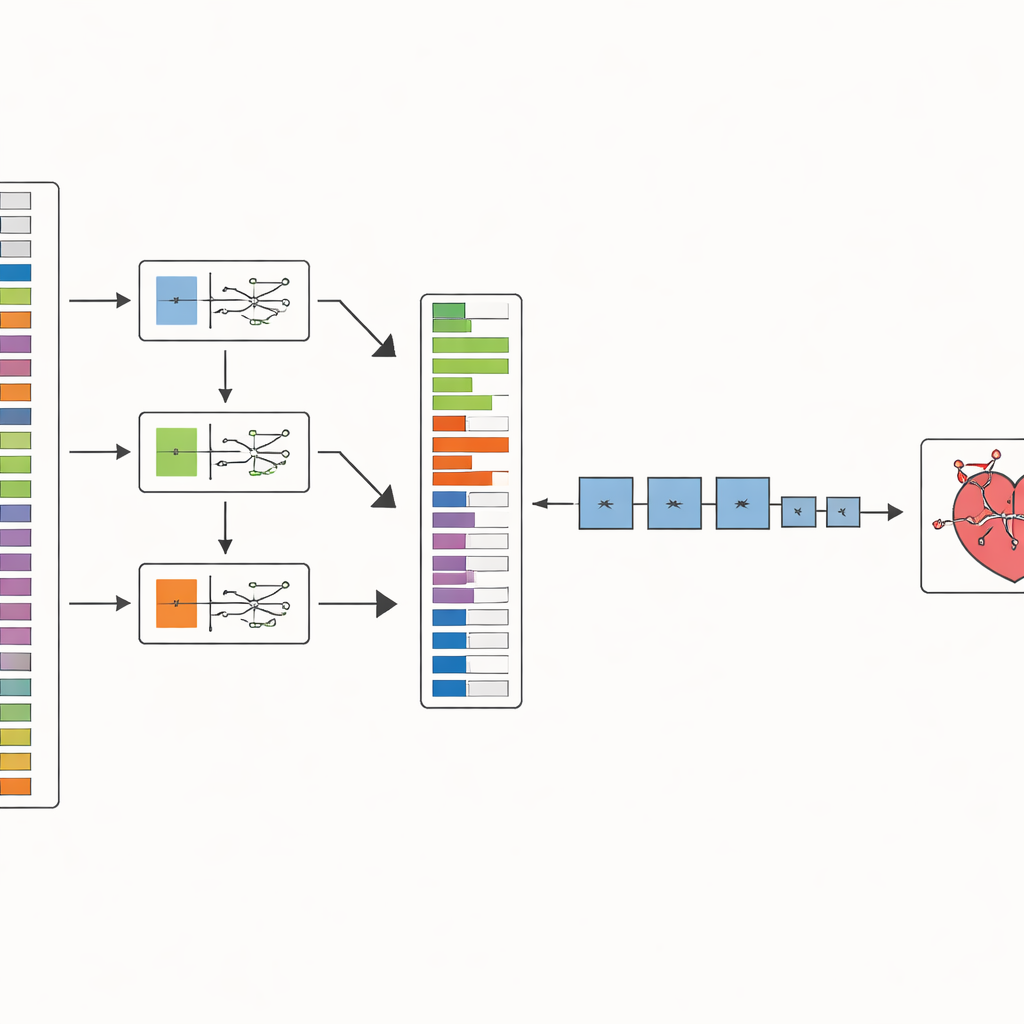
De methode testen
Om te onderzoeken of SHOW echt helpt, testte het team het op drie bekende datasets voor coronaire hartziekte die verschillen in grootte, complexiteit en in welk aandeel patiënten daadwerkelijk de ziekte hebben. Ze probeerden zeven populaire machine learning-modellen, van eenvoudige logistische regressie tot meer geavanceerde technieken zoals random forests en XGBoost. Voor elke dataset vergeleken ze de prestaties met alle beschikbare kenmerken versus alleen die gekozen door SHOW, en herhaalden de tests vele malen in een kruisvalidatieschema om toevallige uitschieters te vermijden. Ze volgden niet alleen de algehele correctheid, maar ook hoe goed de modellen voorkomen dat zieke patiënten gemist worden en hoe duidelijk ze gezonde van zieke gevallen scheiden.
Wat ze vonden in echte patiëntgegevens
In alle drie de datasets stelde SHOW XGBoost consequent in staat om de beste gerapporteerde resultaten in de literatuur te evenaren of te overtreffen, terwijl veel minder invoer werd gebruikt. Bijvoorbeeld: in een dataset met 55 klinische kenmerken sneden ze de lijst terug tot 14 en bereikten ongeveer 94% nauwkeurigheid en vergelijkbaar hoge sensitiviteit, wat betekent dat de meeste zieke patiënten correct werden geïdentificeerd. In twee andere datasets met elk 13 kenmerken selecteerde de methode slechts 5 kenmerken terwijl de nauwkeurigheid rond de 86–88% bleef. Praktisch gezien suggereert dit dat een gerichte handvol metingen — zoals specifieke vormen van pijn op de borst, belangrijke laboratoriumuitslagen en bepaalde beeldvormingssignalen — het grootste deel van het diagnostische gewicht kan dragen wanneer ze wijs worden gekozen.
Vooruitkijken naar eenvoudigere, duidelijkere hartonderzoeken
De studie toont aan dat uitlegbare AI meer kan doen dan alleen voorspellingen leveren; het kan helpen verduidelijken welke alledaagse klinische tekenen werkelijk van belang zijn voor de diagnose van coronaire hartziekte. Door een kleine, waardevolle set metingen te identificeren, zou SHOW goedkopere en snellere screeningsinstrumenten kunnen ondersteunen die toch zeer betrouwbaar en transparanter voor clinici zijn. Hoewel de benadering rekenkundig intensief is en gestroomlijnd moet worden voor zeer grote datasets, biedt het een veelbelovende weg naar slimmerere, beter begrijpelijke AI-assistenten die artsen helpen hartziekte eerder te signaleren zonder te verdrinken in data.
Bronvermelding: Elemam, T., Refaat, H. & Makhlouf, M. An explainable AI-driven hybrid feature selection approach for coronary artery disease diagnosis. Sci Rep 16, 10411 (2026). https://doi.org/10.1038/s41598-026-41712-y
Trefwoorden: coronaire hartziekte, uitlegbare AI, kenmerkselectie, medische diagnostiek, machine learning