Clear Sky Science · zh
低功耗可重新编程的DNA译码器,配备高效HMM加速器以实现实时纳米孔测序
为什么袖珍DNA测序仪需要更聪明的芯片
掌上型DNA测序仪如今能够在数小时而非数年内读取人体基因组,这为床旁诊断、疫情追踪和远离大型实验室的野外生物学研究打开了可能性。但虽然传感硬件变得更小更快,将原始电信号“波形”转换为A、C、G和T字母所需的计算仍然消耗大量能量。本文介绍了一款定制的低功耗芯片,能更高效地执行这一称为碱基译码的转换步骤,使实时、依靠电池供电的DNA分析更加可行。
从电学波形到遗传密码
现代纳米孔测序仪将DNA链拉过一个微小孔洞,并测量碱基通过时离子流的变化。设备产生的不是四个清晰的电平,而是噪声很大的时间序列,每次读数反映了若干相邻碱基的综合影响。这使得解码变成了在强噪声下的模式识别问题。碱基译码算法必须从这些波动信号中筛选并推断出最可能产生它们的DNA片段,因为后续的所有步骤——如基因组组装或突变检测——都依赖于这第一步的准确性。
应对噪声信号的概率路线图
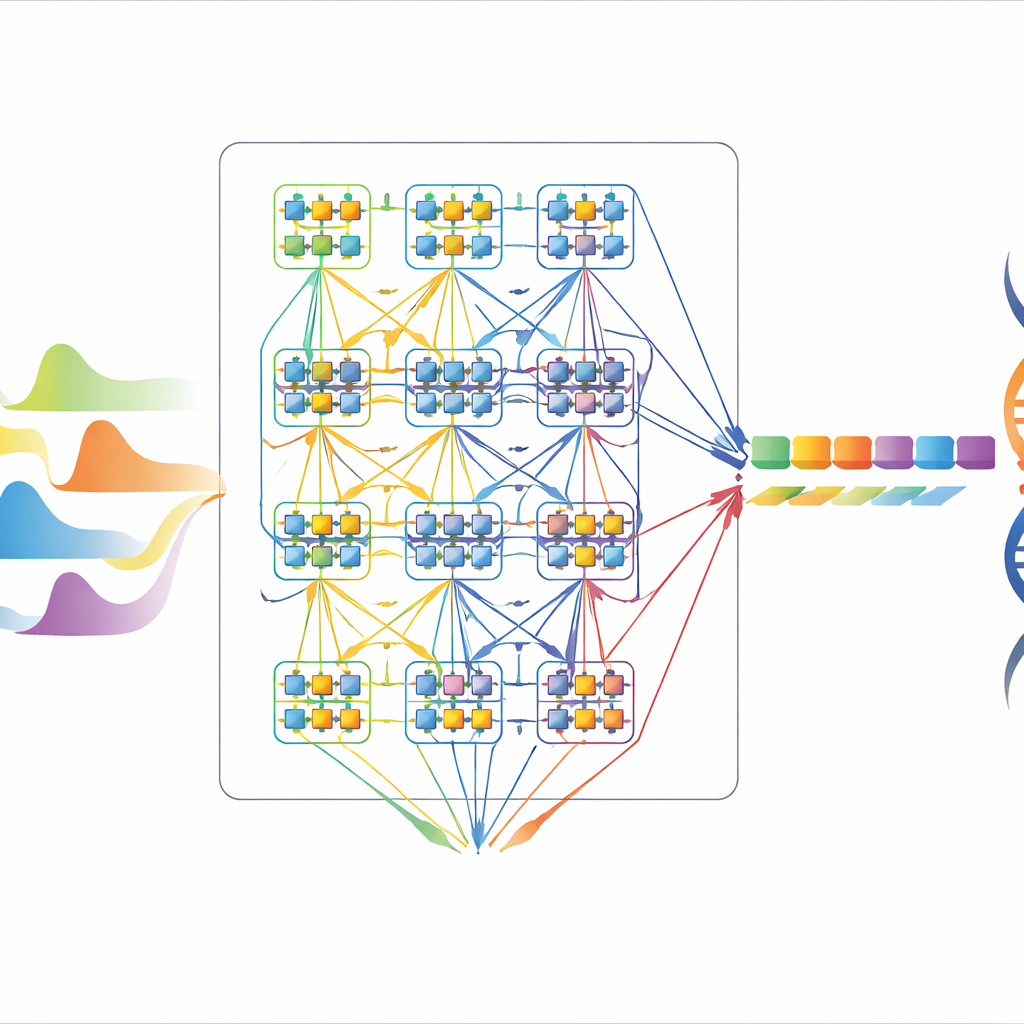
作者基于一种称为隐马尔可夫模型(HMM)的技术,将DNA解码视为在一张可能的短碱基模式网络中移动,同时观察输入信号。网络中的每个状态对应一小段碱基,状态之间的转移表示DNA链如何在纳米孔中滑动。借助维特比算法,系统搜索最可能产生观测到信号的状态路径。该方法对硬件实现很有吸引力:它在数学上严谨、天然能处理噪声,并且可以通过增加状态数进行扩展,而其核心操作——相加、比较和存储数值得分——足够简单,可在芯片上用硬连线实现。
设计精简且可重用的碱基译码引擎
直接的硬件实现会为每个可能的状态和转移分配独立电路,虽然速度很高但会导致芯片体积大且功耗高。作者提出了一种时序并行(serial-parallel)架构,通过在时间上复用较小的构建模块来避免这一问题。他们先设计了高效的16状态处理单元,然后通过巧妙的调度和共享,使该模块能够处理完整的64状态模型,必要时甚至反复复用以支持多达4096个状态。关键技巧包括将状态转移组织为多个状态共享同一算术硬件、将大型比较拆分为四输入的小阶段以及将昂贵的函数(如对数)预先在芯片外计算。综合这些选择,以较小的处理周期增加换取电路量的显著减少。
在速度、准确性与电池寿命之间取得平衡
该译码器采用标准的130纳米工艺制造,处理速度约为每秒800万碱基——足以跟上实时测序——功耗仅约200毫瓦。其译码准确率(94.3%)超过了若干采用相同建模方法的软件工具,并略优于先前的一款硬件加速器,而功耗比许多竞争设计低四到六倍。与深度学习碱基译码器相比,后者虽然在准确性上高出几个百分点,但需瓦级功耗和复杂硬件,这款芯片以牺牲部分峰值性能为代价,换来更简单、更可预测且更节能的运行。测量与仿真表明,采用合适位宽配置的定点算术足以匹配浮点参考结果的精度。
迈向口袋大小的基因组学
对非专业读者而言,主要结论是这项工作让DNA解码更接近能够在手机大小的设备或适用于野外的分析仪中运行,而无需依赖笨重的计算机或高耗能的图形处理器。通过将一种成熟的统计方法巧妙地重塑为紧凑且可重用的硬件引擎,作者展示了快速、准确且节能地读取基因组的可行性。未来,他们设想将此方法与更轻量的深度学习技术结合,但即使在当前形式下,该芯片也为下一代移动与嵌入式DNA测序系统提供了坚实基础。
引用: Shahraki, A.S., Magierowski, S., Abbasi, M. et al. Low power reprogrammable DNA basecaller with an efficient HMM accelerator for real time nanopore sequencing. Sci Rep 16, 11425 (2026). https://doi.org/10.1038/s41598-026-41649-2
关键词: 纳米孔测序, DNA碱基译码, 低功耗硬件, 隐马尔可夫模型, ASIC加速器