Clear Sky Science · it
Basecaller di DNA riprogrammabile a bassa potenza con un acceleratore HMM efficiente per il sequenziamento nanopore in tempo reale
Perché i sequenziatori di DNA tascabili hanno bisogno di chip più intelligenti
I sequenziatori di DNA grandi come il palmo della mano possono ormai leggere un genoma umano in ore anziché in anni, aprendo possibilità per diagnostica a letto del paziente, tracciamento di focolai e biologia sul campo lontano dai grandi laboratori. Ma mentre la parte sensoriale è diventata piccola e veloce, il calcolo necessario per trasformare gli “scarabocchi” elettrici grezzi nelle lettere A, C, G e T continua a consumare molta energia. Questo articolo descrive un chip personalizzato a basso consumo che esegue questo passaggio—chiamato basecalling—con molta più efficienza, rendendo l’analisi del DNA in tempo reale e su batteria più pratica.
Dagli scarabocchi elettrici al codice genetico
I moderni sequenziatori nanopore trascinano filamenti di DNA attraverso un foro minuscolo e misurano come cambia il flusso di ioni mentre le basi passano. Invece di quattro livelli di segnale netti, il dispositivo produce una serie temporale rumorosa in cui ogni lettura riflette più basi adiacenti contemporaneamente. Questo rende la decodifica della sequenza un problema di riconoscimento di pattern in presenza di forte rumore. Gli algoritmi di basecalling devono setacciare questi segnali fluttuanti e inferire quali porzioni di DNA hanno più probabilmente prodotto le osservazioni, perché tutti i passaggi successivi—come l’assemblaggio dei genomi o la ricerca di mutazioni—dipendono dall’accuratezza di questo primo stadio.
Una road map probabilistica per segnali rumorosi
Gli autori si basano su una tecnica chiamata Modello di Markov Nascosto, che tratta la decodifica del DNA come uno spostamento attraverso una rete di possibili brevi pattern di basi osservando il segnale in ingresso. Ogni stato di questa rete corrisponde a un piccolo blocco di basi, e le transizioni tra stati rappresentano come il filamento di DNA può scorrere attraverso il nanoporo. Usando l’algoritmo di Viterbi, il sistema cerca il percorso più probabile attraverso questi stati che potrebbe aver prodotto il segnale osservato. Questo approccio è interessante per l’hardware: è matematicamente rigoroso, gestisce naturalmente il rumore e può essere scalato aggiungendo più stati, mentre le sue operazioni principali—somme, confronti e memorizzazione di punteggi numerici—sono abbastanza semplici da implementare direttamente su chip.
Progettare un motore di basecalling snello e riutilizzabile
Una implementazione hardware diretta dedicherebbe circuiti separati a ogni possibile stato e a ogni possibile transizione, ottenendo alta velocità ma un chip molto grande e con elevato consumo. Gli autori introducono invece un’architettura seriale-parallela che riusa blocchi più piccoli nel tempo. Prima progettano un’unità di elaborazione efficiente a 16 stati e poi applicano una schedulazione e una condivisione intelligenti in modo che questo blocco possa gestire un modello completo a 64 stati, e persino essere riutilizzato ripetutamente per supportare fino a 4096 stati quando necessario. Trucchi chiave includono l’organizzazione delle transizioni in modo che molti stati condividano la stessa logica aritmetica, la scomposizione di grandi confronti in stadi a quattro ingressi, e il precomputare funzioni costose come i logaritmi fuori dal chip. Insieme, queste scelte scambiano un modesto aumento dei cicli di elaborazione per una drastica riduzione dei circuiti.
Bilanciare velocità, accuratezza e durata della batteria
Realizzato con un processo standard a 130 nanometri, il basecaller proposto elabora circa 8 milioni di basi di DNA al secondo—sufficientemente veloce per stare al passo con il sequenziamento in tempo reale—consumando solo 200 milliwatt di potenza. La sua accuratezza di decodifica (94,3%) supera diversi strumenti software che usano lo stesso approccio modellistico e marginalmente migliora rispetto a un acceleratore hardware precedente, pur consumando da quattro a sei volte meno energia rispetto a molti progetti concorrenti. Rispetto ai basecaller basati su deep learning, che raggiungono qualche punto percentuale in più di accuratezza ma richiedono watt di potenza e hardware complesso, questo chip sacrifica parte delle massime prestazioni in cambio di un funzionamento più semplice, prevedibile e molto più efficiente dal punto di vista energetico. Misure e simulazioni confermano che l’aritmetica a virgola fissa è sufficientemente precisa da eguagliare i risultati di riferimento in virgola mobile se configurata con larghezze di bit adeguate.
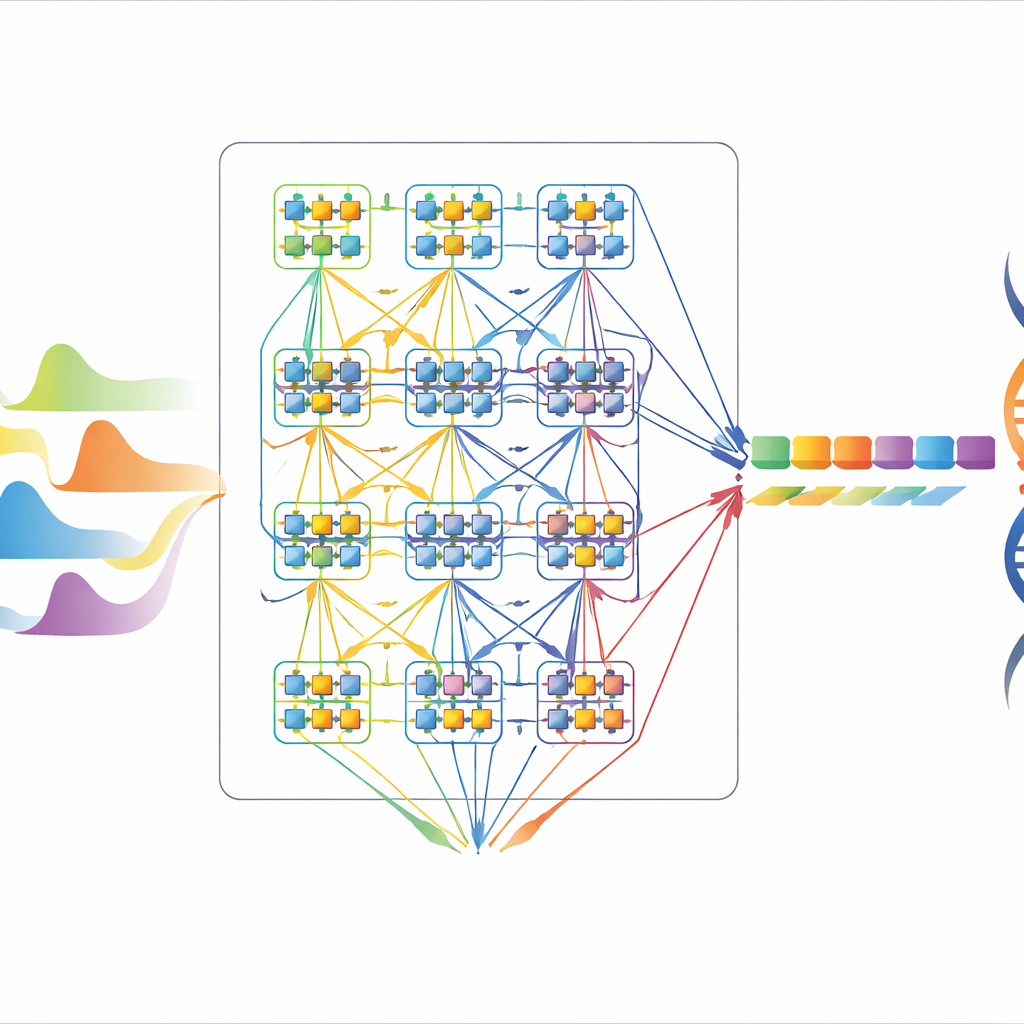
Verso la genomica tascabile
Per i non specialisti, la conclusione principale è che questo lavoro avvicina la decodifica del DNA a qualcosa che può funzionare all’interno di un dispositivo delle dimensioni di un telefono o di un analizzatore pronto per il campo senza fare affidamento su computer ingombranti o processori grafici energivori. Rimodellando con cura un metodo statistico ben conosciuto in un motore hardware compatto e riutilizzabile, gli autori dimostrano che è possibile leggere i genomi in modo rapido, accurato e con consumo energetico contenuto. In futuro immaginano di combinare questo approccio con tecniche di deep learning più leggere, ma anche nella sua forma attuale il chip offre una solida base per i sistemi di sequenziamento del DNA mobili e embedded di prossima generazione.
Citazione: Shahraki, A.S., Magierowski, S., Abbasi, M. et al. Low power reprogrammable DNA basecaller with an efficient HMM accelerator for real time nanopore sequencing. Sci Rep 16, 11425 (2026). https://doi.org/10.1038/s41598-026-41649-2
Parole chiave: sequenziamento nanopore, basecalling del DNA, hardware a basso consumo, Modello di Markov nascosto, acceleratore ASIC