Clear Sky Science · fr
Basecaller ADN reprogrammable et faible consommation avec un accélérateur HMM efficace pour le séquençage nanopore en temps réel
Pourquoi les séquenceurs d’ADN de poche exigent des puces plus intelligentes
Les séquenceurs d’ADN de la taille d’une paume peuvent désormais lire un génome humain en quelques heures au lieu d’années, ouvrant la voie aux diagnostics au chevet, au suivi d’épidémies et à la biologie de terrain loin des grands laboratoires. Mais si le matériel de détection est devenu petit et rapide, le calcul nécessaire pour transformer les ondulations électriques brutes en lettres A, C, G et T consomme encore beaucoup d’énergie. Cet article décrit une puce sur mesure à faible consommation qui effectue cette étape de traduction — appelée basecalling — de façon beaucoup plus efficace, rendant l’analyse d’ADN en temps réel et sur batterie plus pratique.
Des ondulations électriques au code génétique
Les séquenceurs nanopore modernes font passer des brins d’ADN à travers un minuscule pore et mesurent comment le flux d’ions varie au passage des bases. Au lieu de produire quatre niveaux de signal propres, l’appareil génère une série chronologique bruitée où chaque mesure reflète plusieurs bases voisines simultanément. Cela transforme le décodage en un problème de reconnaissance de motifs sous forte perturbation. Les algorithmes de basecalling doivent trier ces signaux fluctuants et déduire quels segments d’ADN les ont très probablement produits, car toutes les étapes ultérieures — comme l’assemblage de génomes ou la détection de mutations — dépendent d’un premier décodage fiable.
Une feuille de route probabiliste pour des signaux bruités
Les auteurs s’appuient sur une technique appelée modèle de Markov caché, qui considère le décodage de l’ADN comme un parcours à travers un réseau de motifs courts possibles tout en observant le signal entrant. Chaque état de ce réseau correspond à un petit bloc de bases, et les transitions entre états représentent la manière dont le brin d’ADN peut glisser dans le nanopore. À l’aide de l’algorithme de Viterbi, le système recherche le chemin le plus probable à travers ces états susceptible d’avoir produit le signal observé. Cette approche est attrayante pour le matériel : elle est rigoureuse mathématiquement, gère naturellement le bruit et peut être étendue en ajoutant des états, tandis que ses opérations de base — addition, comparaison et stockage de scores numériques — sont assez simples pour être câblées en dur sur une puce.
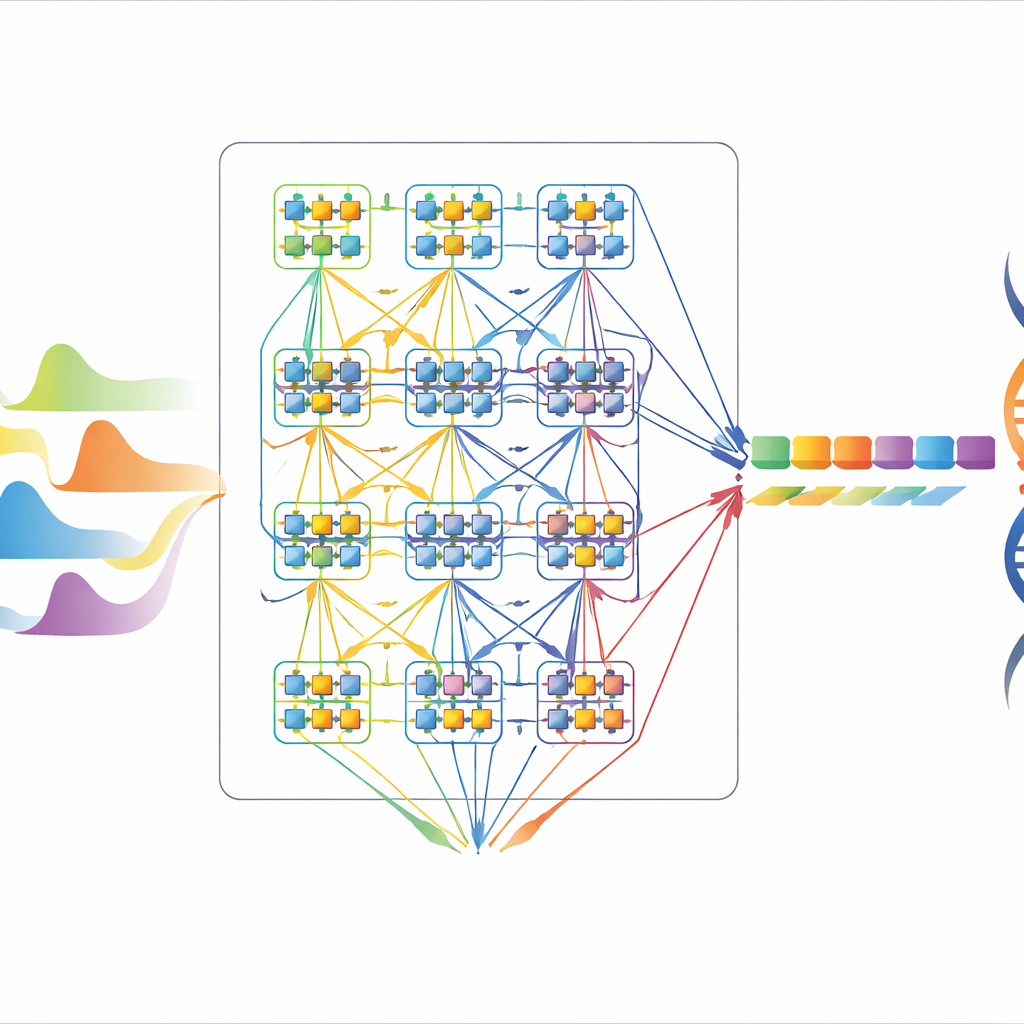
Concevoir un moteur de basecalling sobre et réutilisable
Une implémentation matérielle directe dédierait des circuits séparés à chaque état possible et à chaque transition, offrant une grande vitesse mais une puce très volumineuse et énergivore. Au lieu de cela, les auteurs présentent une architecture série-parallèle qui réutilise de petits blocs de construction au fil du temps. Ils conçoivent d’abord une unité de traitement efficace de 16 états, puis appliquent une planification astucieuse et du partage pour que ce bloc puisse gérer un modèle complet à 64 états, et même être réutilisé de façon répétée pour prendre en charge jusqu’à 4096 états si nécessaire. Les astuces clés incluent l’organisation des transitions d’états de sorte que de nombreux états partagent le même matériel arithmétique, la décomposition de grandes comparaisons en petites étapes à quatre entrées, et le précalcul hors puce de fonctions coûteuses comme les logarithmes. Ensemble, ces choix échangent une augmentation modeste des cycles de traitement contre une réduction spectaculaire du circuit.
Arbitrer vitesse, précision et autonomie
Fabriqué dans un procédé standard à 130 nanomètres, le basecaller proposé traite environ 8 millions de bases d’ADN par seconde — suffisamment rapide pour suivre le séquençage en temps réel — tout en ne consommant que 200 milliwatts. Sa précision de décodage (94,3 %) dépasse celle de plusieurs outils logiciels utilisant la même approche de modélisation et devance légèrement un accélérateur matériel précédent, tout en consommant quatre à six fois moins d’énergie que de nombreux designs concurrents. Comparés aux basecallers par apprentissage profond, qui atteignent quelques points de pourcentage de précision en plus mais exigent des watts de puissance et un matériel complexe, cette puce sacrifie une partie de la performance maximale au profit d’un fonctionnement plus simple, plus prévisible et beaucoup plus économe en énergie. Mesures et simulations confirment que l’arithmétique en virgule fixe est suffisamment précise pour égaler les résultats en virgule flottante de référence lorsque les largeurs de bits appropriées sont choisies.
Vers la génomique de poche
Pour les non-spécialistes, l’essentiel est que ce travail rapproche le décodage de l’ADN d’un fonctionnement possible à l’intérieur d’un appareil de la taille d’un téléphone ou d’un analyseur prêt pour le terrain, sans dépendre d’ordinateurs volumineux ou de processeurs graphiques énergivores. En remodelant soigneusement une méthode statistique bien comprise en un moteur matériel compact et réutilisable, les auteurs montrent qu’il est possible de lire des génomes rapidement, précisément et avec une consommation d’énergie frugale. À l’avenir, ils envisagent de combiner cette approche avec des techniques d’apprentissage profond plus légères, mais même dans sa forme actuelle, la puce constitue une base solide pour les systèmes de séquençage d’ADN mobiles et embarqués de prochaine génération.
Citation: Shahraki, A.S., Magierowski, S., Abbasi, M. et al. Low power reprogrammable DNA basecaller with an efficient HMM accelerator for real time nanopore sequencing. Sci Rep 16, 11425 (2026). https://doi.org/10.1038/s41598-026-41649-2
Mots-clés: séquençage nanopore, basecalling ADN, matériel basse consommation, modèle de Markov caché, accélérateur ASIC