Clear Sky Science · pl
Niskomocny rekonfigurowalny basecaller DNA z wydajnym akceleratorem HMM do sekwencjonowania nanoporem w czasie rzeczywistym
Dlaczego miniaturowe sekwensery DNA potrzebują mądrzejszych układów
Sequensery DNA wielkości dłoni potrafią dziś odczytać genom człowieka w ciągu godzin zamiast lat, otwierając możliwości diagnostyki przy łóżku pacjenta, śledzenia ognisk chorób i badań terenowych z dala od dużych laboratoriów. Jednak choć sprzęt pomiarowy stał się mały i szybki, obliczenia potrzebne do przekształcenia surowych elektrycznych „zawijasów” w litery A, C, G i T wciąż zużywają dużo energii. Ten artykuł opisuje niestandardowy układ niskiego poboru mocy, który wykonuje ten etap tłumaczenia — zwany basecallingiem — znacznie efektywniej, co sprawia, że analiza DNA w czasie rzeczywistym na baterii staje się bardziej praktyczna.
Od elektrycznych zawijasów do kodu genetycznego
Nowoczesne sekwensery nanopore przeciągają nici DNA przez mikroskopijny otwór i mierzą, jak zmienia się przepływ jonów, gdy kolejne zasady mijają bramkę. Zamiast czterech odrębnych poziomów sygnału urządzenie generuje zaszumiony szereg czasowy, w którym każde odczytanie odzwierciedla kilka sąsiednich zasad jednocześnie. To sprawia, że rozszyfrowanie sekwencji jest zadaniem rozpoznawania wzorców przy dużym poziomie szumu. Algorytmy basecallingu muszą przesiać te fluktuujące sygnały i wywnioskować, które fragmenty DNA najprawdopodobniej je wygenerowały, ponieważ wszystkie późniejsze etapy — jak składanie genomów czy wykrywanie mutacji — zależą od poprawności tego pierwszego kroku.
Probabilistyczna mapa drogowa dla zaszumnionych sygnałów
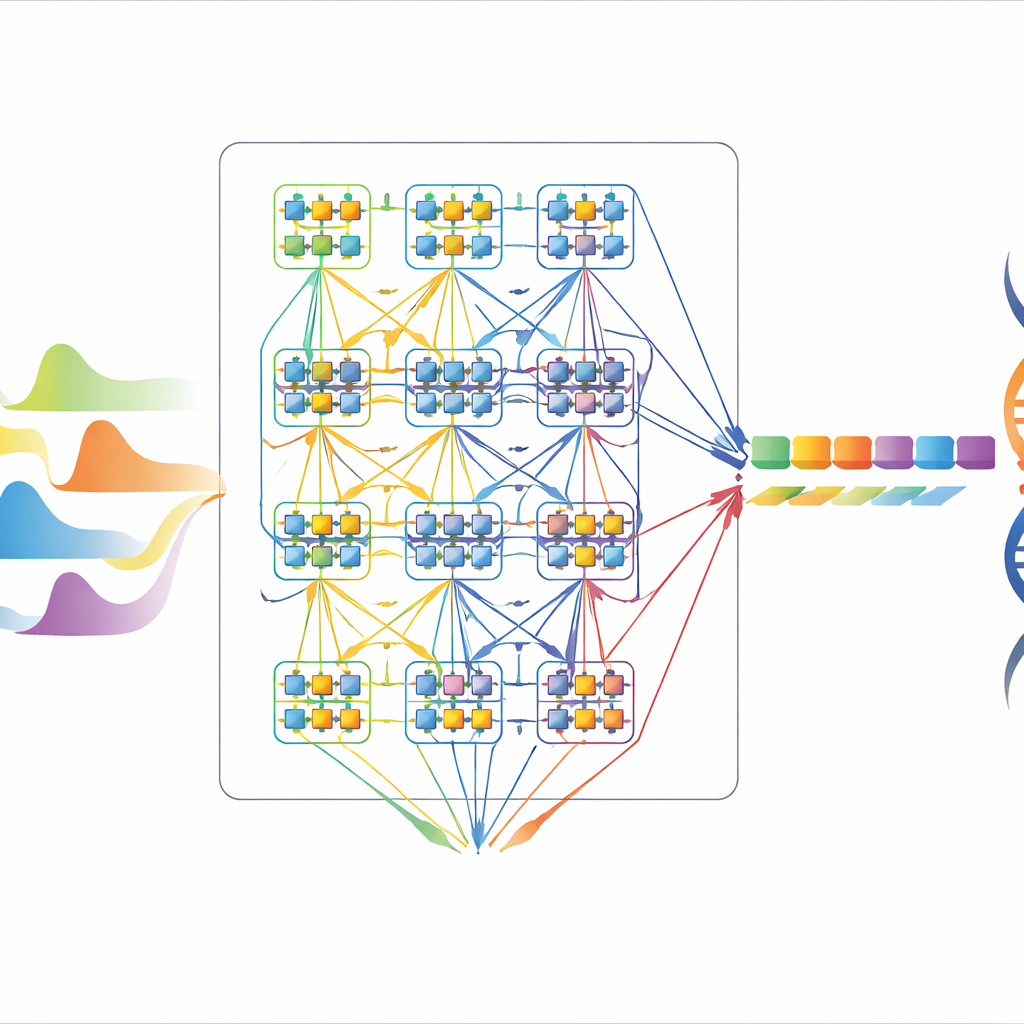
Autorzy opierają się na technice zwanej Ukrytym Modelem Markowa (Hidden Markov Model), która traktuje dekodowanie DNA jako poruszanie się po sieci możliwych krótkich wzorców zasad przy jednoczesnym obserwowaniu nadchodzącego sygnału. Każdy stan w tej sieci odpowiada małemu blokowi zasad, a przejścia między stanami reprezentują sposób, w jaki nić DNA może przesuwać się przez nanoporę. Z użyciem algorytmu Viterbiego system szuka najbardziej prawdopodobnej ścieżki przez te stany, która mogła wygenerować zaobserwowany sygnał. Podejście to jest atrakcyjne dla sprzętu: jest matematycznie solidne, naturalnie radzi sobie ze szumem i można je skalować przez dodawanie stanów, a jego podstawowe operacje — dodawanie, porównywanie i przechowywanie ocen numerycznych — są wystarczająco proste, by zrealizować je w twardym układzie na chipie.
Projektowanie oszczędnego, wielokrotnego silnika basecallingu
Prosty sprzętowy implementacja poświęciłaby oddzielne obwody dla każdego możliwego stanu i każdego przejścia, co dałoby dużą prędkość, ale bardzo duży i prądożerny chip. Zamiast tego autorzy wprowadzają architekturę seryjno‑równoległą, która ponownie wykorzystuje mniejsze bloki w czasie. Najpierw projektują wydajną jednostkę przetwarzającą 16 stanów, a następnie stosują sprytne harmonogramowanie i współdzielenie, tak aby ten blok obsłużył pełny model 64 stanów, a nawet mógł być wielokrotnie użyty do obsługi do 4096 stanów w razie potrzeby. Kluczowe sztuczki obejmują organizację przejść stanów tak, by wiele stanów współdzieliło tę samą arytmetyczną część sprzętu, rozbijanie dużych porównań na małe etapy czterowyborowe oraz wstępne obliczanie kosztownych funkcji, takich jak logarytmy, poza chipem. Razem te wybory wymieniają umiarkowany wzrost liczby cykli przetwarzania na dramatyczne zmniejszenie liczby obwodów.
Równoważenie szybkości, dokładności i czasu pracy na baterii
Wytworzony w standardowym procesie 130 nanometrów proponowany basecaller przetwarza około 8 milionów zasad DNA na sekundę — wystarczająco szybko, by nadążyć za sekwencjonowaniem w czasie rzeczywistym — przy zużyciu jedynie 200 miliwatów mocy. Jego dokładność dekodowania (94,3%) przewyższa kilka narzędzi programowych używających tego samego podejścia modelowego i nieznacznie wyprzedza wcześniejszy akcelerator sprzętowy, a jednocześnie zużywa od czterech do sześciu razy mniej energii niż wiele konkurencyjnych projektów. W porównaniu z basecallerami opartymi na głębokim uczeniu, które osiągają o kilka punktów procentowych wyższą dokładność, lecz wymagają watów mocy i złożonego sprzętu, ten chip poświęca część maksymalnej wydajności na rzecz prostszej, bardziej przewidywalnej i znacznie bardziej energooszczędnej pracy. Pomiary i symulacje potwierdzają, że arytmetyka stałoprzecinkowa jest wystarczająco precyzyjna, by dopasować się do wyników odniesienia w zmiennoprzecinkowym formacie, gdy skonfigurowana jest z odpowiednią szerokością bitową.
W stronę genomiki mieszczącej się w kieszeni
Dla laików najważniejszy wniosek jest taki, że ta praca przybliża dekodowanie DNA do czegoś, co może działać wewnątrz urządzenia wielkości telefonu czy przenośnego analizatora bez polegania na masywnych komputerach czy energochłonnych procesorach graficznych. Poprzez umiejętne przekształcenie dobrze znanej metody statystycznej w kompaktowy, wielokrotnie używalny silnik sprzętowy, autorzy pokazują, że możliwe jest szybkie, dokładne i energooszczędne odczytywanie genomów. W przyszłości przewidują łączenie tego podejścia z lżejszymi technikami głębokiego uczenia, ale nawet w obecnej formie chip stanowi solidną podstawę dla następnej generacji mobilnych i wbudowanych systemów sekwencjonowania DNA.
Cytowanie: Shahraki, A.S., Magierowski, S., Abbasi, M. et al. Low power reprogrammable DNA basecaller with an efficient HMM accelerator for real time nanopore sequencing. Sci Rep 16, 11425 (2026). https://doi.org/10.1038/s41598-026-41649-2
Słowa kluczowe: sekwencjonowanie nanopore, basecalling DNA, sprzęt niskiego poboru mocy, Ukryty model Markowa, akcelerator ASIC