Clear Sky Science · zh
用于空间组学的多重光学条形码标记与测序
在组织中看见分子的位置
我们的身体由多种细胞组成,这些细胞以精确的模式紧密排列,这些模式对健康与疾病都很重要。科学家拥有强大的工具来测量细胞中哪些基因处于活跃状态,但这些工具常常在测量时丢失了每条测量结果在组织中的原始位置信息。本文介绍了一种称为 MOLseq 的新方法,旨在同时保留两类信息:每个细胞在做什么,以及它确切的位置。
为何分子的位置至关重要
近年来,“空间组学”改变了研究者观察组织的方式。研究人员不再把细胞孤立地研究,而是询问在细胞保持原始邻域的情况下,每个细胞中哪些基因被激活。现有方法大致分为两类。成像方法使用显微镜与荧光标记直接在细胞中看到数千种分子,解析度很高,往往可以达到亚细胞结构级别,但通常要求研究者预先选择要观察的基因。测序方法则可以一次读出几乎所有活跃基因,但它们通常会将来自多个细胞的信号混合在一起,并且仅以粗糙的二维网格记录位置信息。因此,研究者常常必须在信息的广度与位置信息的精细度之间做出取舍。
一个由光控制的地址系统
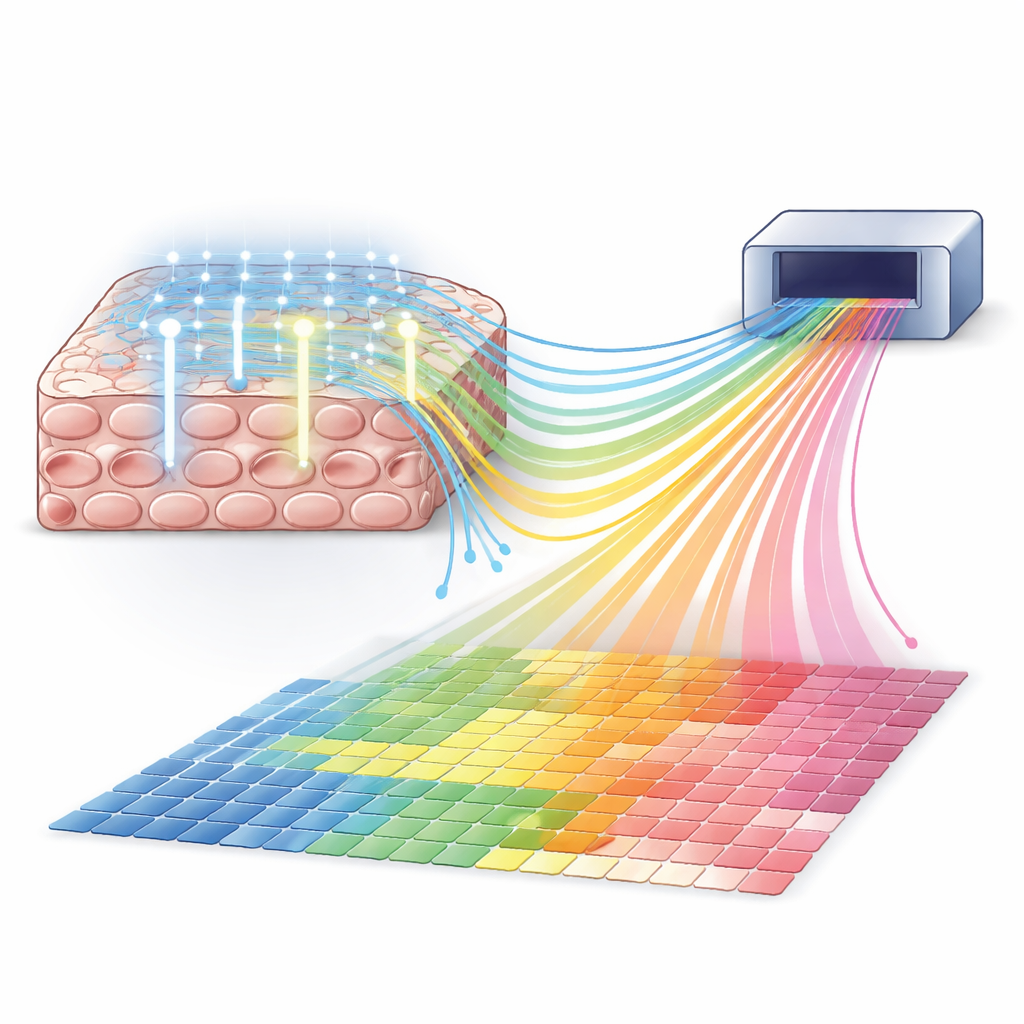
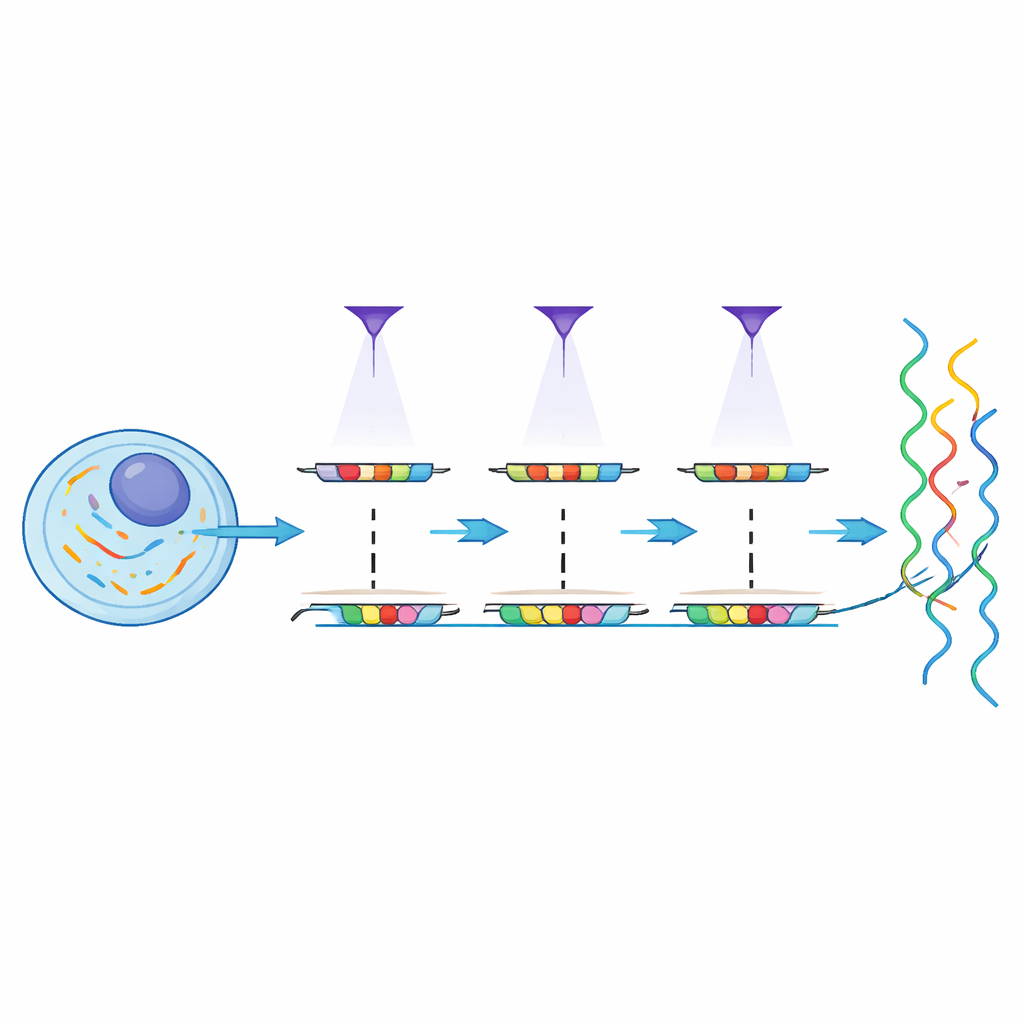
MOLseq 提供了一种将测序的广度与光的精细控制结合的方法。核心思想是给细胞内的分子附上类似“邮政编码”的标记来记录其位置,然后通过测序同时读取邮政编码和基因身份。首先,该方法在固定的细胞内将一段短的 DNA 引物连接到信使 RNA 上,并将这些 RNA 转换为 DNA 拷贝。随后,利用类似投影仪的设备投射有图案的紫外(UV)光,MOLseq 仅在被照射的区域向这些拷贝上添加短的 DNA “字母”。每次光照添加恰好一个字母,字母序列逐步构建出每个位置独一无二的条形码。经过若干轮后,不同区域的分子携带不同的条形码,当样品被解离并测序时,这些条形码就充当了它们的空间地址。
由于条形码是逐步构建的,可用地址的数量随字母数和轮数迅速增长。作者展示了他们的光驱动化学反应可以以约 90% 的每步成功率串联添加字母,并且可以利用设计好的辅助链并行管理多个字母。在细胞培养实验中,他们原位生成了数百种不同的条形码,并用 DNA 大小测定仪确认了预期的条形码长度。重要的是,他们还设计了能标记并纠正部分错误的条形码方案,提升了可靠性,即便单步并非完美。
逐细胞写入条形码
MOLseq 的一大承诺是对条形码写入位置的精确控制。通过用数字微镜器件(DMD)引导紫外光,团队选择性地在从大块区域到单个细胞的范围内光切割并连接字母。他们使用荧光探针可视化字母添加的位置,显示相距仅几微米的相邻细胞几乎没有收到非预期信号。在一项实验中,他们成功地为同一培养皿中的 64 个单个细胞分配了独特的三字母条形码。数据建模表明,每轮发生离靶字母添加的概率仅有几个百分点,而预期的靶向添加率仍然很高。
为了测试这些条形码是否能指导完整的基因读出,研究者在同一盖玻片上将人细胞和鼠细胞分别放置在不同区域并应用 MOLseq。他们为人源和鼠源区域构建了不同的两字母条形码,通过成像确认了它们的空间分离,然后对带条形码的材料进行测序。携带“人类区域”条形码的测序读段压倒性地比对到人类基因,携带“鼠类区域”条形码的则比对到鼠类基因。少部分看似混淆的读段与两种物种之间的天然序列相似性相当,这表明大多数误差并非源自条形码步骤本身,而是来自读段比对中不可避免的歧义。
前景与下一步
通过将光图案化与 DNA 测序相结合,MOLseq 指向了一个未来:研究者可以扫描大面积组织、在不预先选择基因的情况下捕获许多基因的活性,并且仍能知道每个信号的来源位置——可能精确到单个细胞。当前版本仍面临挑战:光的离靶效应、许多连接轮次时的效率限制,以及从非常小区域捕获足够 RNA 的困难。然而这项研究表明,多重光学条形码在培养细胞中是可行且准确的,并且概述了可行的路径以扩展条形码多样性与错误校正。对读者的启示是,像 MOLseq 这样的工具可能很快让研究者绘制出精细的组织“分子地图”,揭示细胞位置与基因活动如何在发育、大脑功能、癌症及许多其他生物过程中过渡协同作用。
引用: Venkatramani, A., Ciftci, D., Pham, K. et al. Multiplexed optical barcoding and sequencing for spatial omics. Sci Rep 16, 14086 (2026). https://doi.org/10.1038/s41598-026-41186-y
关键词: 空间组学, 光学条形码, 转录组学, 单细胞分型, DNA 测序