Clear Sky Science · pl
Wielopasmowe optyczne kodowanie i sekwencjonowanie dla omiki przestrzennej
Widzieć, gdzie molekuły występują w tkankach
Nasze ciała zbudowane są z wielu typów komórek ułożonych w precyzyjne wzory, a te wzory mają znaczenie dla zdrowia i choroby. Naukowcy dysponują potężnymi narzędziami do mierzenia, które geny są aktywne w komórkach, ale te narzędzia często tracą informację o tym, skąd w tkance pochodzi każde pomiar. W artykule przedstawiono nową metodę nazwaną MOLseq, która ma na celu zachować obie informacje jednocześnie: co robi każda komórka i dokładnie gdzie się znajduje.
Dlaczego lokalizacja ma znaczenie dla molekuł
W ostatnich latach „omika przestrzenna” zmieniła sposób, w jaki badacze analizują tkanki. Zamiast badać komórki w izolacji, naukowcy pytają, które geny są włączone w każdej komórce, gdy pozostaje ona w swoim pierwotnym otoczeniu. Istniejące podejścia dzielą się na dwie główne szkoły. Metody obrazowania wykorzystują mikroskopy i znaczniki fluorescencyjne, aby bezpośrednio zobaczyć tysiące molekuł w komórkach z bardzo dużą rozdzielczością, często sięgającą struktur podkomórkowych. Jednak zazwyczaj wymagają od badaczy wcześniejszego wyboru genów do analizy. Metody oparte na sekwencjonowaniu potrafią natomiast odczytać praktycznie wszystkie aktywne geny jednocześnie, ale zwykle mieszają sygnały z wielu komórek i rejestrują pozycje tylko w przybliżonych, dwuwymiarowych siatkach. W rezultacie badacze często muszą wybierać między szerokością informacji a precyzją lokalizacji.
System adresowy sterowany światłem
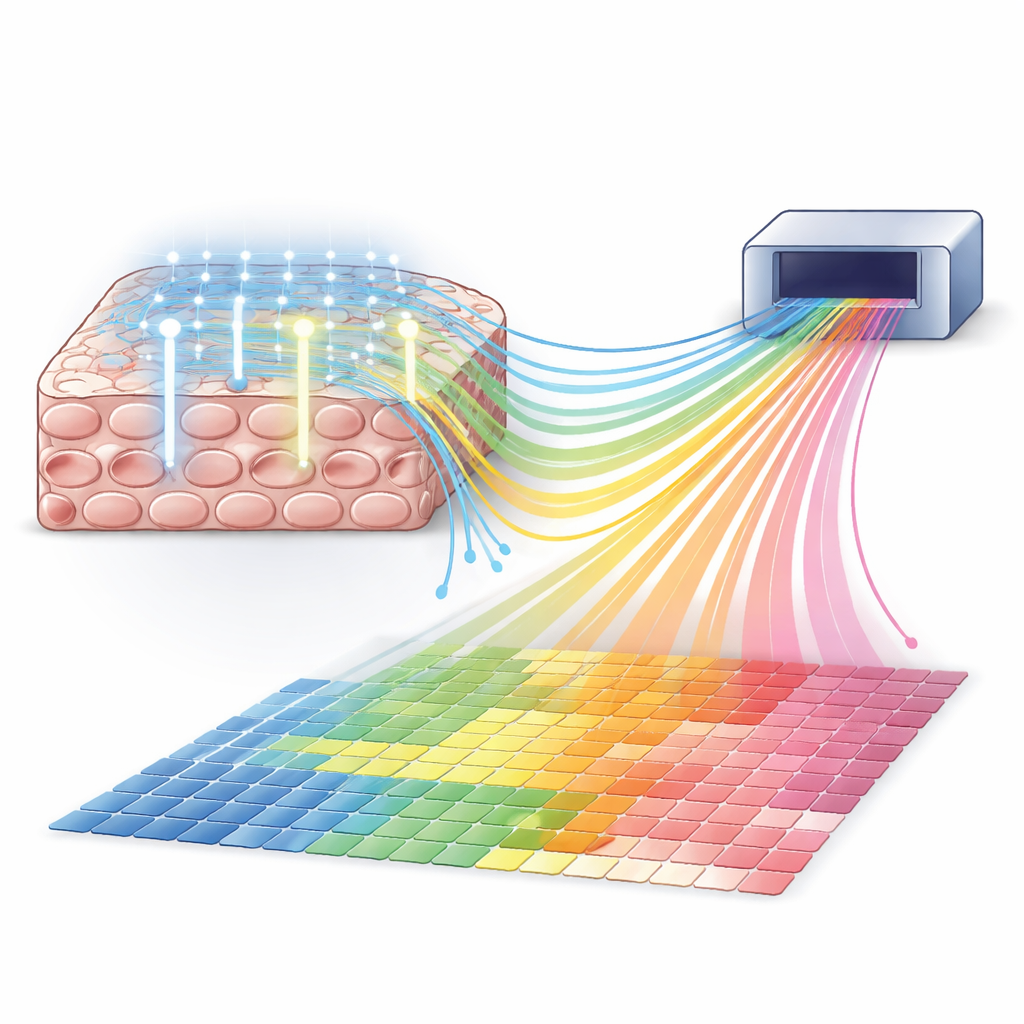
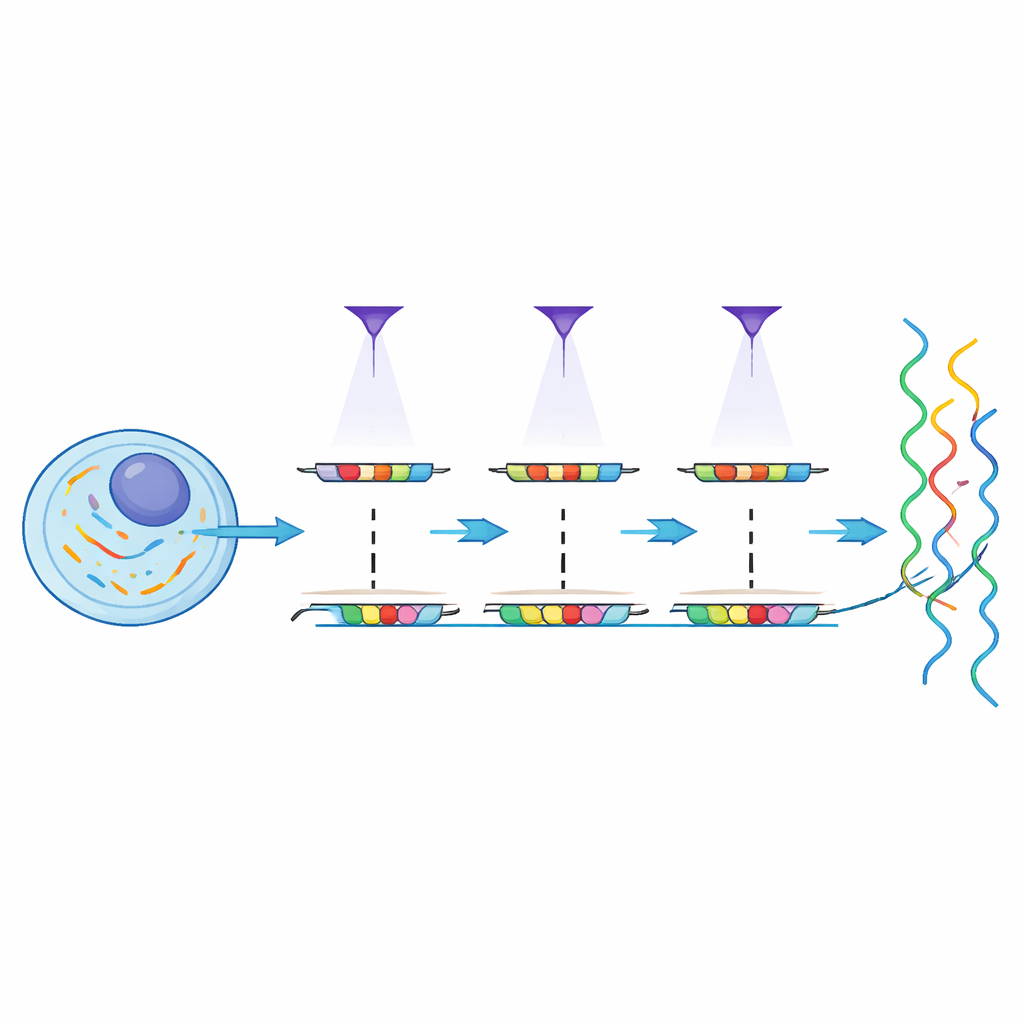
MOLseq oferuje sposób połączenia szerokiego zasięgu sekwencjonowania z precyzją sterowania światłem. Istota pomysłu polega na nadaniu molekułom wewnątrz komórek rodzaju „kodów pocztowych”, które zapisują ich położenie, a następnie odczytaniu zarówno kodu, jak i tożsamości genu przez sekwencjonowanie. Najpierw metoda przyłącza krótki starter DNA do mRNA wewnątrz utrwalonych komórek i przekształca te RNA w kopie DNA. Następnie, używając projektoropodobnego urządzenia emitującego wzorzyste promieniowanie ultrafioletowe (UV), MOLseq dokłada krótkie „litery” DNA do tych kopii tylko w oświetlonych regionach. Każde naświetlenie dodaje dokładnie jedną literę, a sekwencja liter tworzy unikalny kod kreskowy dla danej lokalizacji. Po kilku rundach molekuły z różnych obszarów niosą różne kody, które działają jak ich adresy przestrzenne, kiedy próbka zostanie później rozproszona i poddana sekwencjonowaniu.
Ponieważ kody budowane są krok po kroku, liczba możliwych adresów rośnie szybko wraz z liczbą liter i rund. Autorzy pokazują, że ich chemia aktywowana światłem może dodawać litery seryjnie z około 90% skutecznością na krok, oraz że wiele liter można obsługiwać równolegle przy użyciu zaprojektowanych nici pomocniczych. W eksperymentach na hodowlach komórkowych wygenerowali setki odrębnych kodów in situ i potwierdzili oczekiwane długości kodów przy pomocy urządzenia do pomiaru rozmiaru DNA. Co ważne, zaprojektowali również schematy kodów, które potrafią wykrywać i korygować niektóre błędy, poprawiając niezawodność nawet gdy pojedyncze kroki nie są perfekcyjne.
Pisanie kodów komórka po komórce
Kluczową obietnicą MOLseq jest precyzyjna kontrola tego, gdzie kody są zapisywane. Sterując światłem UV za pomocą cyfrowego urządzenia z mikrolustrem, zespół selektywnie fotoodcinał i ligował litery w regionach od dużych płytek aż po pojedyncze komórki. Użyli sond fluorescencyjnych, by zwizualizować miejsca dodania liter, pokazując, że sąsiednie komórki oddalone o zaledwie kilka mikrometrów otrzymywały prawie żaden niezamierzony sygnał. W jednym eksperymencie pomyślnie przypisali unikalne trzy-literowe kody 64 poszczególnym komórkom na tej samej płytce. Modelowanie danych wskazywało, że prawdopodobieństwo dodania litery poza celem w dowolnej rundzie wynosiło tylko kilka procent, podczas gdy zamierzony współczynnik dodania na cel pozostał wysoki.
Aby sprawdzić, czy te kody umożliwiają pełne odczyty genów, badacze wymieszali ludzkie i mysie komórki w oddzielnych regionach na tej samej szybkach i zastosowali MOLseq. Zbudowali odrębne dwuliterowe kody dla regionów ludzkich i mysich, potwierdzili ich przestrzenną separację obrazowaniem, a następnie zsekwencjonowali otagowany materiał. Odczyty niosące kod „region-ludzki” w przeważającej mierze mapowały się do ludzkich genów, a te z kodem „region-myszy” do genów mysich. Niewielka część pozornych pomyłek była podobna do tej, której można się spodziewać ze względu na naturalne podobieństwo sekwencji między gatunkami, co sugeruje, że większość błędów nie wynikała z samego kodowania, lecz z nieuniknionych niejednoznaczności mapowania odczytów.
Obietnica i kolejne kroki
Łącząc wzorstowanie światła z sekwencjonowaniem DNA, MOLseq wskazuje drogę ku przyszłości, w której naukowcy będą mogli skanować duże obszary tkanek, uchwycić aktywność wielu genów bez wstępnego wyboru i jednocześnie wiedzieć, skąd pochodził każdy sygnał — potencjalnie aż do pojedynczych komórek. Obecna wersja nadal stoi przed wyzwaniami: efekty świetlne poza celem, ograniczona wydajność przy wielu rundach ligacji oraz trudność uchwycenia wystarczającej ilości RNA z bardzo małych obszarów. Mimo to badanie pokazuje, że wielopasmowe optyczne kodowanie jest praktyczne i dokładne w komórkach hodowlanych, oraz przedstawia realistyczne drogi zwiększenia różnorodności kodów i korekcji błędów. Dla czytelników wniosek jest taki, że narzędzia pokroju MOLseq mogą wkrótce pozwolić badaczom tworzyć szczegółowe „mapy molekularne” tkanek, ujawniając, jak pozycje komórek i aktywność genów współdziałają w rozwoju, funkcjonowaniu mózgu, nowotworach i wielu innych procesach biologicznych.
Cytowanie: Venkatramani, A., Ciftci, D., Pham, K. et al. Multiplexed optical barcoding and sequencing for spatial omics. Sci Rep 16, 14086 (2026). https://doi.org/10.1038/s41598-026-41186-y
Słowa kluczowe: omika przestrzenna, optyczne kodowanie, transkryptomika, profilowanie pojedynczych komórek, sekwencjonowanie DNA