Clear Sky Science · ru
Мультиплексное оптическое кодирование и секвенирование для пространственной омики
Видеть, где находятся молекулы в тканях
Наше тело состоит из множества типов клеток, упакованных в точные узоры, и эти узоры важны для здоровья и заболеваний. Ученые располагают мощными инструментами, чтобы измерять, какие гены активны в клетках, но эти методы часто теряют след того, из какого именно места ткани взята каждая оценка. В этой работе представлен новый метод, названный MOLseq, который стремится одновременно сохранить обе составляющие информации: что делает каждая клетка и где именно она расположена.
Почему положение важно для молекул
За последние годы «пространственная омics» изменила подход исследователей к изучению тканей. Вместо изучения клеток в изоляции ученые теперь выясняют, какие гены включены в каждой клетке, пока она остается в своем исходном окружении. Существующие подходы делятся на два основных лагеря. Методы визуализации используют микроскопы и флуоресцентные метки, чтобы напрямую видеть тысячи молекул в клетках с очень высокой детализацией, часто до субклеточных структур. Но обычно они требуют заранее выбрать, какие гены исследовать. Методы секвенирования, наоборот, могут считывать практически все активные гены одновременно, но как правило смешивают сигналы от многих клеток и записывают положения в грубых двумерных решетках. В результате исследователям часто приходится выбирать между широтой информации и точностью локализации.
Система адресации, управляемая светом
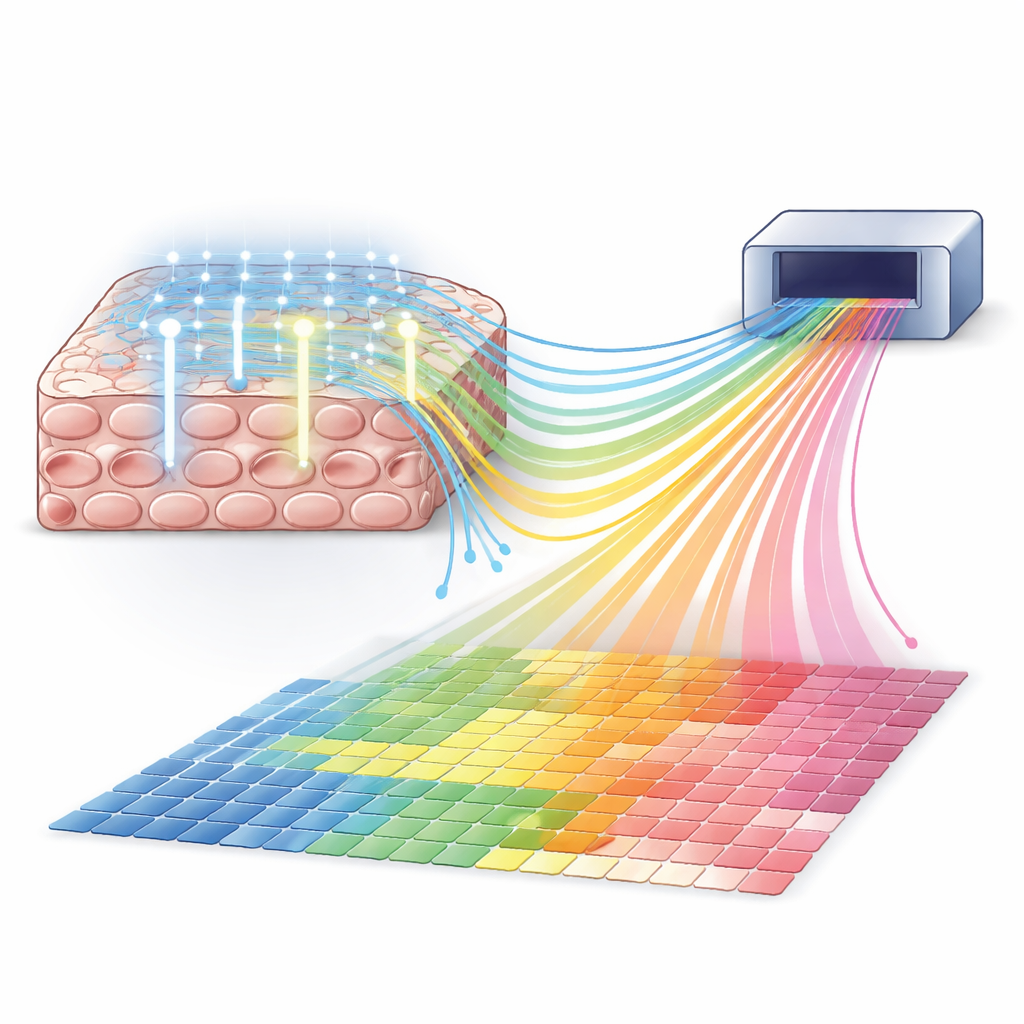
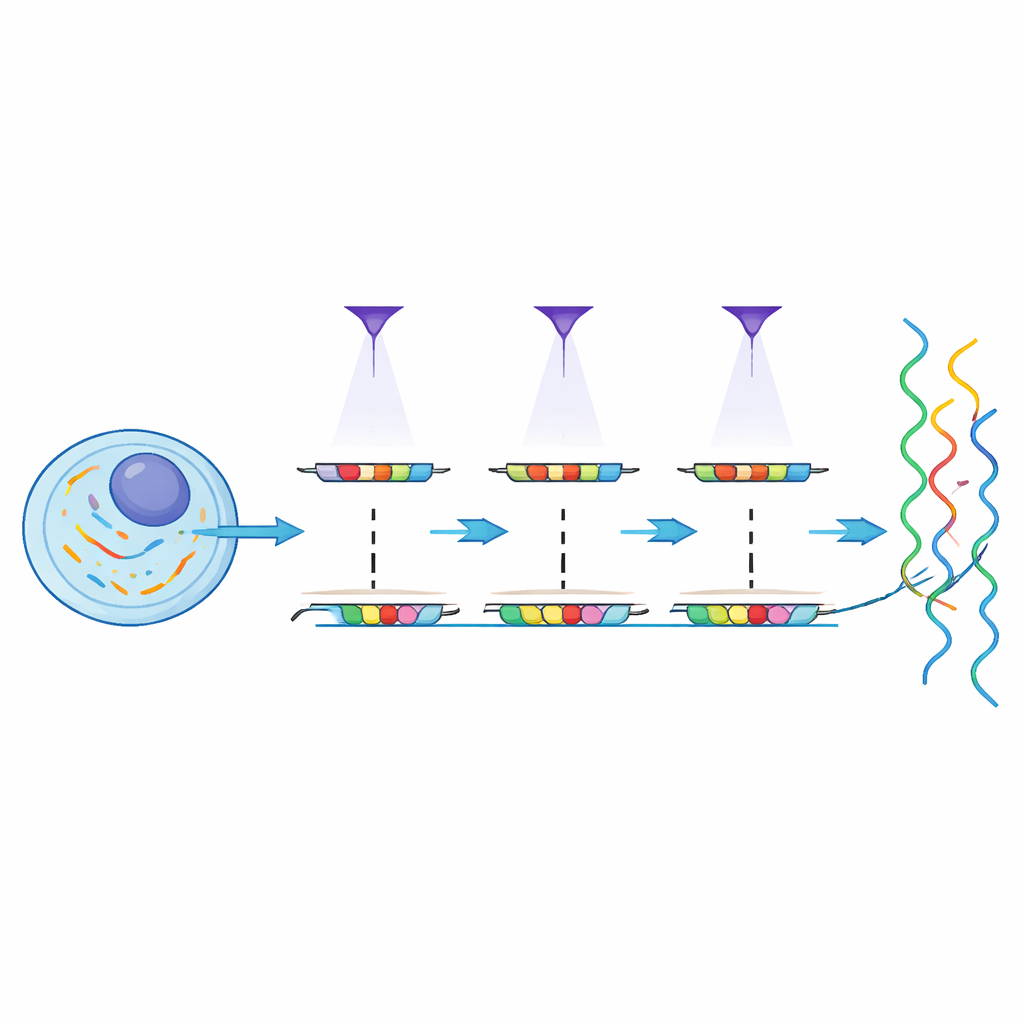
MOLseq предлагает способ объединить широту секвенирования с тонким контролем света. Основная идея — присвоить молекулам внутри клеток нечто вроде «почтового кода», фиксирующего их позицию, а затем считать и почтовый код, и идентичность гена с помощью секвенирования. Сначала метод прикрепляет короткий ДНК-праймер к матричным РНК в фиксированных клетках и превращает эти РНК в копии ДНК. Затем, используя устройство, подобное проектору, которое посылает узорный ультрафиолетовый (УФ) свет, MOLseq добавляет короткие ДНК «буквы» к этим копиям только в освещенных регионах. Каждый всплеск света добавляет ровно одну букву, и последовательность букв формирует уникальный штрихкод для каждой локации. После нескольких раундов молекулы из разных областей несут разные штрихкоды, которые служат их пространственными адресами, когда образец затем разрушают и секвенируют.
Поскольку штрихкоды строятся поэтапно, число возможных адресов быстро растет с увеличением числа букв и раундов. Авторы показывают, что их светоуправляемая химия может добавлять буквы последовательно с примерно 90% успешностью на шаг, а несколько букв можно обрабатывать параллельно с помощью специально разработанных вспомогательных нитей. В экспериментах на культурах клеток они получили сотни различающихся штрихкодов in situ и подтвердили ожидаемую длину штрихкодов с помощью прибора для определения размеров ДНК. Важно, что они также разработали схемы штрихкодов, способные отмечать и исправлять некоторые ошибки, повышая надежность даже при несовершенных отдельных шагах.
Запись штрихкодов по одной клетке
Ключевое обещание MOLseq — точный контроль над тем, где записываются штрихкоды. Управляя УФ‑светом с помощью цифрового устройства с микрозеркалами, команда селективно фоторасщепляла и лигировала буквы в регионах от больших участков до отдельных клеток. Они использовали флуоресцентные зонды, чтобы визуализировать, где были добавлены буквы, показав, что соседние клетки всего в нескольких микрометрах получают почти никакого непреднамеренного сигнала. В одном эксперименте им удалось присвоить уникальные трехбуквенные штрихкоды 64 отдельным клеткам в одной и той же чашке. Моделирование данных показало, что вероятность добавления побочной буквы в любом данном раунде составляла всего несколько процентов, в то время как запланированная добавка на целевом участке оставалась высокой.
Чтобы проверить, могут ли эти штрихкоды направлять полное считывание генов, исследователи смешали человеческие и мышиные клетки в отдельных областях на одном покровном стекле и применили MOLseq. Они создали разные двухбуквенные штрихкоды для человеческой и мышиной областей, подтвердили их пространственное разделение при визуализации и затем секвенировали маркированный материал. Риды, несущие штрихкод «человеческой области», подавляюще соответствовали человеческим генам, а те, у которых был штрихкод «мышиной области», — мышиным генам. Небольшая доля кажущихся смешений была сопоставима с ожидаемой из естественной схожести последовательностей между двумя видами, что указывает на то, что большинство ошибок не возникло из самого кодирования, а отражает неизбежные неоднозначности при выравнивании ридов.
Перспективы и следующие шаги
Объединив узорный свет и секвенирование ДНК, MOLseq указывает на будущее, в котором ученые смогут сканировать большие участки ткани, фиксировать активность множества генов без предварительного отбора и при этом знать, откуда пришел каждый сигнал — потенциально до уровня отдельных клеток. Текущая версия по‑прежнему сталкивается с проблемами: побочные эффекты света вне целевых зон, ограниченная эффективность при большом числе раундов лигирования и трудности в захвате достаточного количества РНК из очень маленьких областей. Тем не менее исследование показывает, что мультиплексное оптическое кодирование практично и точно в культурах клеток, и описывает реалистичные пути к увеличению разнообразия штрихкодов и исправлению ошибок. Вывод для читателя таков: инструменты вроде MOLseq вскоре могут позволить исследователям создавать подробные «молекулярные карты» тканей, раскрывая, как положение клеток и генетическая активность взаимодействуют в развитии, работе мозга, раке и многих других биологических процессах.
Цитирование: Venkatramani, A., Ciftci, D., Pham, K. et al. Multiplexed optical barcoding and sequencing for spatial omics. Sci Rep 16, 14086 (2026). https://doi.org/10.1038/s41598-026-41186-y
Ключевые слова: пространственная омics, оптическое кодирование, транскриптомика, профилирование одиночных клеток, секвенирование ДНК