Clear Sky Science · zh
通过纠错码表征揭示遗传密码的内在设计原理
为何微小的DNA错误至关重要
你体内的每个细胞都依赖一种极为可靠的翻译系统,将遗传字母转化为功能性蛋白质。然而,DNA不断受到随机变化或突变的冲击。本文提出了一个看似简单却耐人寻味的问题:遗传密码本身——将三联密码子映射到氨基酸的通用字典——是否在悄然“设计”上具有缓冲这些错误影响的能力,就像保护我们数字通信不被扰乱的纠错码一样?通过把生物学视为一种通信系统,作者揭示了若干隐藏的设计规则,帮助解释遗传密码为何呈现出如今的样貌。
将基因视为通信系统
在数字技术中,信息被打包,经过嘈杂信道传输,然后解码。工程师会刻意加入冗余,以便某些比特翻转时仍能恢复原始信息。作者将这一视角应用于生物学。在此,密码子(由A、C、G和T/U的三联组成)充当信道符号,氨基酸是信息单元,而遗传密码则扮演解码器的角色。由于64个密码子只编码20种氨基酸加上终止信号,映射中包含内在的冗余。核心思想是“逆向工程”出遗传密码最能抵御哪类突变,而不假定关于特定突变在自然中发生频率的详细知识。
为突变构建错误阶梯
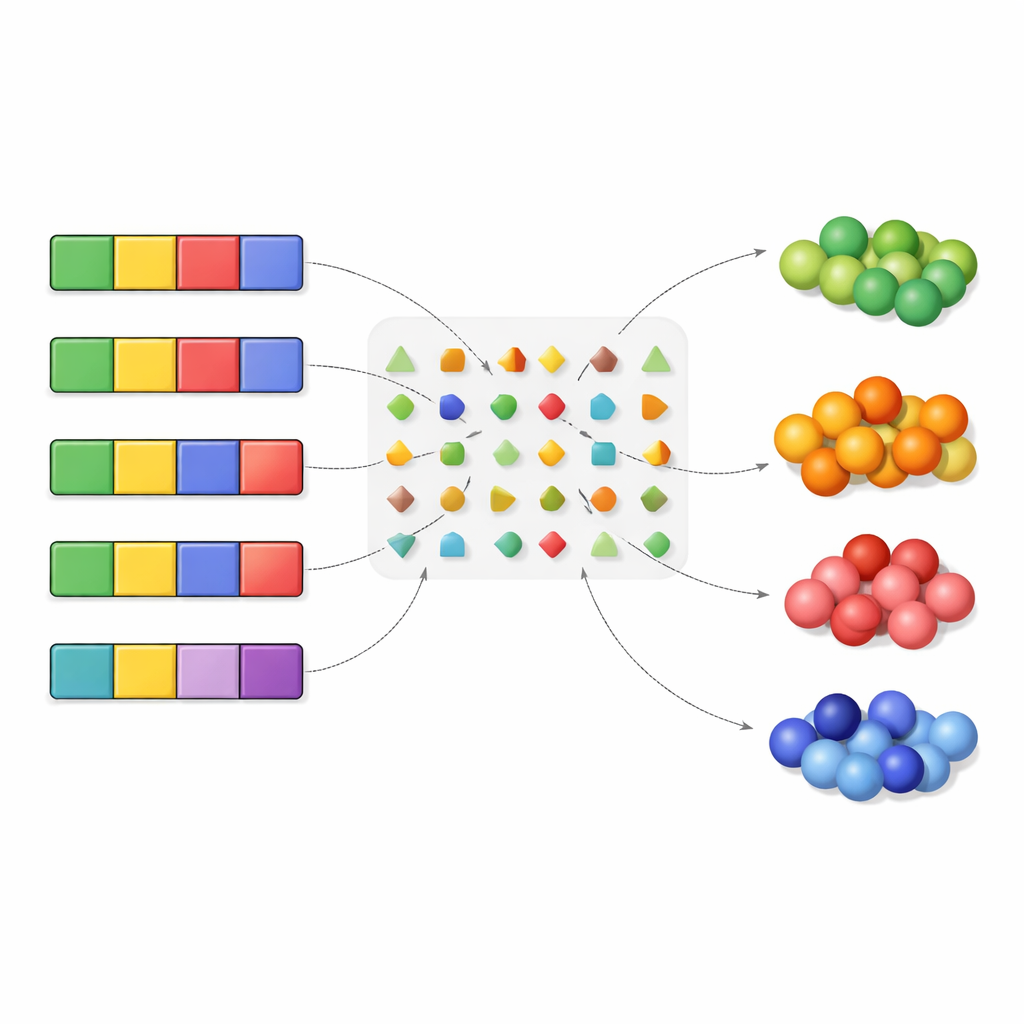
为此,作者引入了发现错误层级(Finding Error Hierarchy,FEH)算法。它系统地扫描所有可能的密码子级别突变模式,包括改变三联中多达三个位置的组合,远超以往研究大多只考察的单一字母变化。对于每一种可能的核苷酸替换模式,FEH都会提出问题:若这种类型的错误发生在所有密码子上,遗传密码有多大频率会将它们“解码”为与之前相同的氨基酸,又有多大频率会导致氨基酸改变?然后,算法将错误模式按遗传密码处理得特别好到处理得特别差的顺序进行排序,构建出一种突变抗性层级,实质上揭示了遗传密码似乎旨在保护的对象。
发现遗传密码最优先保护的内容
将该算法应用于标准遗传密码后,算法恢复了若干众所周知的事实,同时又将其延伸。结果证实:不发生突变(无错误)是最常见且最易处理的情况;第三位密码子的变化通常比第一位或第二位的变化危害更小;并且“转换”(在同一核苷酸家族内的互换)通常比“颠换”(跨家族的替换)更易被容忍。为了更深入地分析,作者对信息进行了压缩:不再追踪精确的氨基酸,而是按类型对其分组,例如按与水的相互作用或按密码子中的A/T与G/C比例进行分组。这种做法增加了冗余,使算法能够辨析出更长、更细致的可容忍突变层级。
蛋白质与DNA稳定性的隐含优先项
通过测试多种不同的氨基酸分组方法,研究识别出哪些分组最自然地被遗传密码保留。两个特征尤为突出。首先,疏水性——氨基酸避水的倾向——受到强烈保护。会把蛋白质核心中疏水残基变为亲水残基的突变相对不被偏好。其次,氨基酸密码子的A/T与G/C之间的特定平衡,以及G/T与A/C之间的比例,也有优先被维持的倾向。这些模式源自同义密码子的排列方式以及密码子第二位的重要性——第二位已知强烈影响氨基酸是疏水还是亲水。综上,这些发现表明遗传密码在调谐上既旨在保护蛋白质结构,也旨在维护某些基础的核苷酸模式。
这对生命韧性意味着什么
简言之,这项工作表明遗传密码表现得很像精心设计的纠错方案:它对某些类型的DNA变化远比其他类型更为宽容,尤其是那些不会改变氨基酸与水相关行为或关键核苷酸比例的变化。FEH算法提供了一种严格的方法,在不依赖物种特异数据的前提下揭示这种内建的保护层级。这有助于解释为何几乎所有生命形式都保留了相同的遗传密码,并为研究突变如何从DNA传导到蛋白质——以及为何某些变化特别重要——提供了新的框架。
引用: Aharon, A., Polak, P. & Yaari, G. Revealing the inherent design principles of the genetic code via an error correcting code representation. Sci Rep 16, 11035 (2026). https://doi.org/10.1038/s41598-026-39862-0
关键词: 遗传密码, 突变鲁棒性, 纠错码, 蛋白质结构, 分子进化