Clear Sky Science · sv
Avslöjande av de inneboende designprinciperna i den genetiska koden via en representation som felrättande kod
Varför små fel i DNA spelar roll
Varje cell i din kropp förlitar sig på ett förvånansvärt pålitligt översättningssystem som omvandlar genetiska bokstäver till fungerande proteiner. Ändå utsätts DNA ständigt för slumpmässiga förändringar, eller mutationer. Denna artikel ställer en förrädiskt enkel fråga: är den genetiska koden i sig — den universella ordlistan som kopplar tre-bokstavskodoner till aminosyror — tyst utformad för att dämpa effekten av dessa misstag, på samma sätt som felkorrigerande koder skyddar våra digitala kommunikationer från att bli förvrängda? Genom att betrakta biologin som ett kommunikationssystem avslöjar författarna dolda designregler som hjälper till att förklara varför den genetiska koden ser ut som den gör.
Att se gener som ett kommunikationssystem
I digital teknik paketeras information, skickas genom en brusig kanal och avkodas sedan. Ingenjörer lägger medvetet till redundans så att om vissa bitar flippar kan det ursprungliga meddelandet ändå återställas. Författarna applicerar detta perspektiv på biologin. Här är kodoner (tripletter av A, C, G och T/U) kanalsymbolerna, aminosyror är informationsenheterna och den genetiska koden fungerar som avkodaren. Eftersom 64 kodoner kodar för endast 20 aminosyror plus en stoppsignal innehåller kartan inbyggd redundans. Kärn idén är att ”reverskonstruera” vilka typer av mutationer den genetiska koden är bäst på att skaka av sig, utan att anta detaljerad kunskap om hur ofta specifika mutationer sker i naturen.
Bygga en felflora för mutationer
För att göra detta introducerar författarna algoritmen Finding Error Hierarchy (FEH). Den skannar systematiskt igenom alla möjliga mutationsmönster på kodonnivå, inklusive kombinationer som förändrar upp till tre positioner i en triplet, långt bortom de enkla en-bokstavsändringar som de flesta tidigare studier undersökt. För varje möjligt mönster av nukleotidsubstitutioner frågar FEH: om denna typ av fel inträffade över alla kodoner, hur ofta skulle den genetiska koden ”avkoda” dem till samma aminosyra som tidigare, och hur ofta skulle den orsaka en förändring? Algoritmen rangordnar sedan felmönstren från dem som koden hanterar särskilt väl till dem den hanterar dåligt, och bygger en hierarki av mutationsresiliens som effektivt avslöjar vad koden verkar utformad för att skydda.
Upptäcka vad koden skyddar mest
När den tillämpas på den standardiserade genetiska koden återfinner algoritmen flera välkända insikter men fördjupar dem också. Den bekräftar att att inte göra någon förändring (inga mutationer) är det vanligaste och bäst hanterade fallet, och att förändringar på tredje kodonpositionen vanligtvis är mindre skadliga än förändringar på första eller andra. Den bekräftar också att ”transitioner” — utbyten inom samma nukleotidfamilj — tenderar att tolereras bättre än ”transversioner”, som hoppar mellan familjer. För att gå djupare komprimerar författarna informationen: istället för att följa exakta aminosyror grupperar de dem efter typer, till exempel efter hur de interagerar med vatten eller efter fördelningen A/T kontra G/C i deras kodoner. Detta ökar redundansen och låter algoritmen nysta fram en längre, mer detaljerad hierarki av tolererade mutationer.
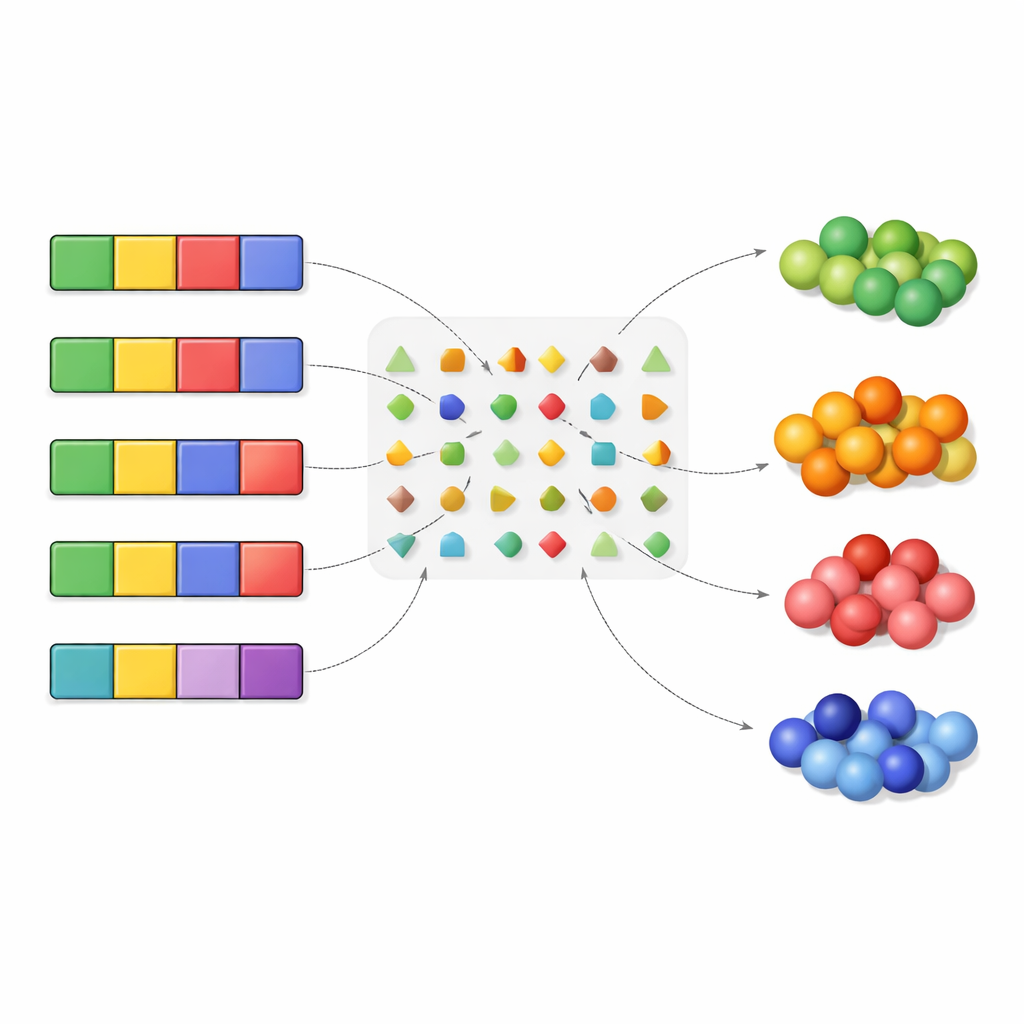
Dolda prioriteringar för protein- och DNA-stabilitet
Genom att testa många olika sätt att gruppera aminosyror identifierar studien vilka grupperingarna som mest naturligt bevaras av koden. Två framträder särskilt. För det första försvaras hydrofobicitet — aminosyrors tendens att undvika vatten — starkt. Mutationer som skulle omvandla en vattenhatande rest i proteinets inre till en vattenälskande är relativt missgynnade. För det andra bevaras också särskilda balanser mellan A/T och G/C samt mellan G/T och A/C i en aminosyras kodoner. Dessa mönster uppstår från hur synonymiska kodoner är ordnade och från den speciella betydelsen av den andra positionen i ett kodon, vilken är känd för att starkt påverka om en aminosyra är hydrofob eller hydrofil. Tillsammans tyder dessa fynd på att den genetiska koden är inställd för att skydda både proteinstruktur och vissa underliggande nukleotidmönster.
Vad detta betyder för livets motståndskraft
Enkelt uttryckt visar detta arbete att den genetiska koden beter sig mycket som ett omsorgsfullt utformat felkorrigeringsschema: den är mycket mer förlåtande mot vissa typer av DNA-förändringar än andra, särskilt sådana som skulle lämna en aminosyras vattenrelaterade egenskaper och viktiga nukleotidkvoter intakta. FEH-algoritmen ger ett strikt sätt att exponera denna inbyggda skyddshierarki utan att förlita sig på artspecifika data. Det hjälper till att förklara varför samma genetiska kod bevarats över nästan allt liv på jorden, och erbjuder ett nytt ramverk för att studera hur mutationer sprider sig från DNA till proteiner — och varför vissa förändringar särskilt sannolikt får betydelse.
Citering: Aharon, A., Polak, P. & Yaari, G. Revealing the inherent design principles of the genetic code via an error correcting code representation. Sci Rep 16, 11035 (2026). https://doi.org/10.1038/s41598-026-39862-0
Nyckelord: genetisk kod, mutationsresiliens, felkorrigerande koder, proteinstruktur, molekylär evolution