Clear Sky Science · fr
Révéler les principes de conception intrinsèques du code génétique via une représentation en code correcteur d’erreurs
Pourquoi de petites erreurs dans l'ADN comptent
Chaque cellule de votre corps s'appuie sur un système de traduction remarquablement fiable qui convertit les lettres génétiques en protéines fonctionnelles. Pourtant l'ADN est constamment soumis à des modifications aléatoires, ou mutations. Cet article pose une question apparemment simple : le code génétique lui-même — le dictionnaire universel qui associe les codons de trois lettres aux acides aminés — est‑il implicitement conçu pour amortir l'impact de ces erreurs, à la manière des codes correcteurs d'erreurs qui empêchent nos communications numériques d'être corrompues ? En abordant la biologie comme un système de communication, les auteurs mettent au jour des règles de conception cachées qui aident à expliquer pourquoi le code génétique est tel qu'il est.
Voir les gènes comme un système de communication
En technologie numérique, l'information est empaquetée, envoyée à travers un canal bruité, puis décodée. Les ingénieurs ajoutent volontairement de la redondance pour que si certains bits se renversent, le message original puisse être récupéré. Les auteurs appliquent cette perspective à la biologie. Ici, les codons (triplets de A, C, G et T/U) sont les symboles du canal, les acides aminés sont les unités d'information, et le code génétique joue le rôle du décodeur. Parce que 64 codons codent seulement 20 acides aminés plus un signal de stop, le mappage contient une redondance intégrée. L'idée centrale est de « rétroconcevoir » quels types de mutations le code génétique gère le mieux, sans supposer une connaissance détaillée des fréquences de mutation particulières dans la nature.
Construire une échelle d'erreurs pour les mutations
Pour cela, les auteurs introduisent l'algorithme Finding Error Hierarchy (FEH). Il explore systématiquement tous les schémas de mutation possibles au niveau des codons, y compris des combinaisons qui modifient jusqu'à trois positions d'un triplet, bien au‑delà des changements d'une seule lettre examinés par la plupart des études antérieures. Pour chaque motif possible de substitutions nucléotidiques, FEH se demande : si ce type d'erreur se produisait sur tous les codons, à quelle fréquence le code génétique les « décoderait » en le même acide aminé qu'avant, et à quelle fréquence provoquerait‑il un changement ? L'algorithme classe ensuite les motifs d'erreur de ceux que le code traite particulièrement bien à ceux qu'il gère mal, construisant une hiérarchie de résilience aux mutations qui révèle de fait ce que le code semble protégé de préserver.
Découvrir ce que le code protège le plus
Appliqué au code génétique standard, l'algorithme restitue plusieurs faits bien connus tout en les étendant. Il confirme que l'absence de mutation est le cas le plus courant et le mieux géré, et que les changements à la troisième position du codon sont généralement moins nocifs que ceux à la première ou à la seconde. Il réaffirme aussi que les « transitions » — échanges au sein d'une même famille de nucléotides — sont en général mieux tolérées que les « transversions », qui sautent entre familles. Pour aller plus loin, les auteurs compressent ensuite l'information : au lieu de suivre les acides aminés exacts, ils les regroupent en types, par exemple selon leur interaction avec l'eau ou selon la proportion A/T versus G/C dans leurs codons. Cela augmente la redondance et permet à l'algorithme d'extraire une hiérarchie plus longue et plus détaillée de mutations tolérées.
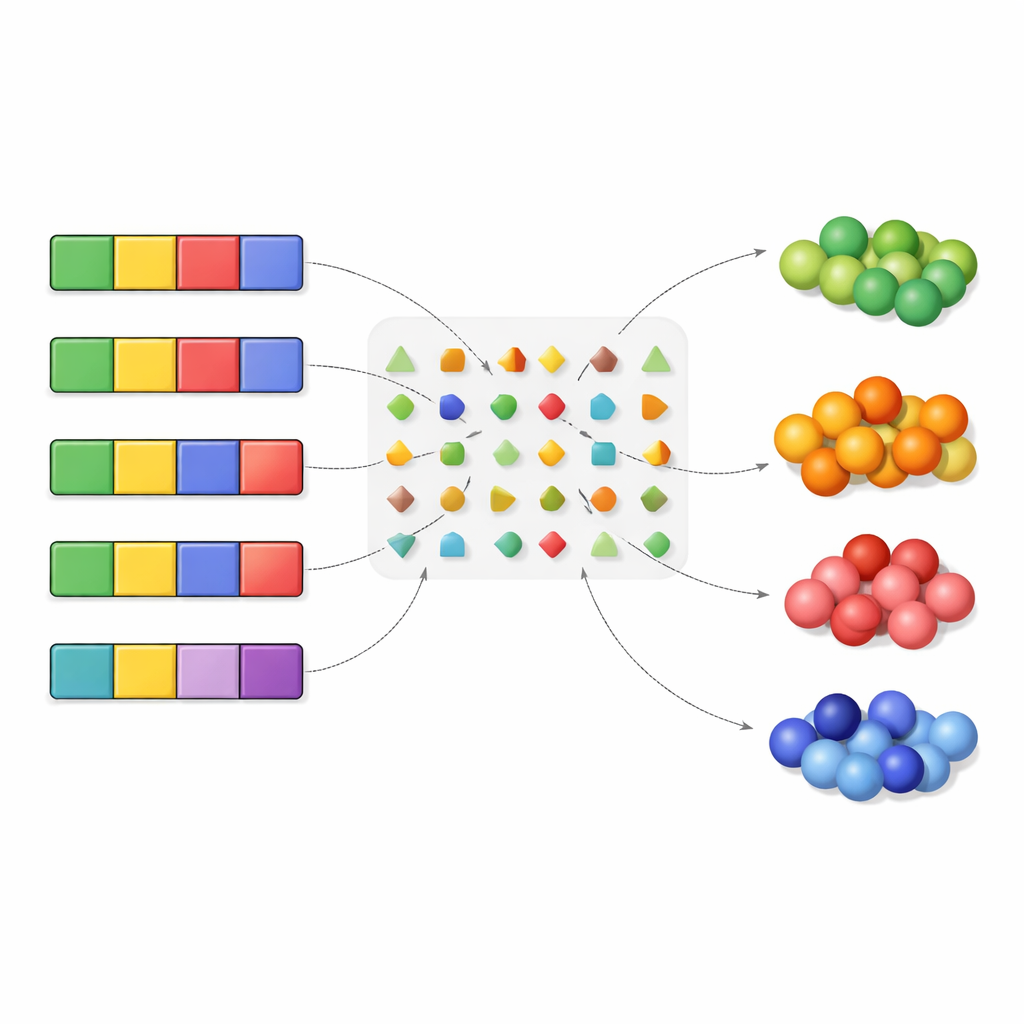
Priorités cachées pour la stabilité des protéines et de l'ADN
En testant de nombreuses manières de regrouper les acides aminés, l'étude identifie quels regroupements sont le plus naturellement préservés par le code. Deux ressortent particulièrement. D'abord, l'hydrophobicité — la tendance des acides aminés à éviter l'eau — est fortement protégée. Les mutations qui transformeraient un résidu hydrophobe au cœur d'une protéine en un résidu hydrophile sont relativement défavorisées. Ensuite, certains équilibres spécifiques de A/T versus G/C et de G/T versus A/C parmi les codons d'un acide aminé sont également privilégiés. Ces motifs découlent de la façon dont les codons synonymes sont organisés et de l'importance particulière de la deuxième position d'un codon, connue pour influencer fortement si un acide aminé est hydrophobe ou hydrophile. Ensemble, ces résultats suggèrent que le code génétique est accordé pour protéger à la fois la structure protéique et certains motifs nucléotidiques sous‑jacents.
Ce que cela signifie pour la résilience de la vie
En termes simples, ce travail montre que le code génétique se comporte comme un schéma correcteur d'erreurs soigneusement conçu : il est bien plus indulgent envers certains types de changements d'ADN que d'autres, en particulier ceux qui préservent le comportement vis‑à‑vis de l'eau d'un acide aminé et des rapports nucléotidiques clés. L'algorithme FEH offre une manière rigoureuse de mettre en évidence cette hiérarchie de protection intégrée sans s'appuyer sur des données spécifiques à une espèce. Cela aide à expliquer pourquoi le même code génétique a été conservé à travers presque toute la vie sur Terre, et fournit un nouveau cadre pour étudier comment les mutations se propagent de l'ADN aux protéines — et pourquoi certains changements sont particulièrement susceptibles d'avoir des conséquences.
Citation: Aharon, A., Polak, P. & Yaari, G. Revealing the inherent design principles of the genetic code via an error correcting code representation. Sci Rep 16, 11035 (2026). https://doi.org/10.1038/s41598-026-39862-0
Mots-clés: code génétique, robustesse aux mutations, codes correcteurs d'erreurs, structure des protéines, évolution moléculaire