Clear Sky Science · it
Rivelare i principi di progetto insiti nel codice genetico tramite una rappresentazione come codice a correzione d’errori
Perché anche piccoli errori nel DNA contano
Ogni cellula del tuo corpo si affida a un sistema di traduzione sorprendentemente affidabile che trasforma le lettere genetiche in proteine funzionanti. Eppure il DNA è continuamente soggetto a cambiamenti casuali, o mutazioni. Questo articolo pone una domanda apparentemente semplice: il codice genetico stesso — il dizionario universale che mappa i codoni di tre lettere agli amminoacidi — è in qualche modo progettato per attenuare l’impatto di quegli errori, analogamente ai codici a correzione d’errori che impediscono la corruzione delle nostre comunicazioni digitali? Trattando la biologia come se fosse un sistema di comunicazione, gli autori scoprono regole di progetto nascoste che aiutano a spiegare perché il codice genetico appare com’è.
Vedere i geni come un sistema di comunicazione
Nella tecnologia digitale, l’informazione viene impacchettata, inviata attraverso un canale rumoroso e poi decodificata. Gli ingegneri aggiungono deliberatamente ridondanza in modo che se alcuni bit cambiano, il messaggio originale possa essere comunque recuperato. Gli autori applicano questa lente alla biologia. Qui, i codoni (triplette di A, C, G e T/U) sono i simboli del canale, gli amminoacidi le unità informazionali e il codice genetico svolge il ruolo del decodificatore. Poiché 64 codoni codificano solo 20 amminoacidi più un segnale di stop, la mappatura contiene ridondanza intrinseca. L’idea centrale è “ingegnerizzare al contrario” quali tipi di mutazioni il codice genetico è più in grado di sopportare, senza presumere una conoscenza dettagliata della frequenza con cui particolari mutazioni avvengono in natura.
Costruire una scala di errori per le mutazioni
Per farlo, gli autori introducono l’algoritmo Finding Error Hierarchy (FEH). Esso scandaglia sistematicamente tutti i possibili schemi di mutazione a livello di codone, incluse combinazioni che alterano fino a tre posizioni in una tripla, ben oltre i cambiamenti di una singola lettera che la maggior parte degli studi precedenti ha esaminato. Per ciascun possibile schema di sostituzioni nucleotidiche, FEH si chiede: se questo tipo di errore si verificasse su tutti i codoni, quanto spesso il codice genetico li “decodificherebbe” nello stesso amminoacido di prima e quanto spesso causerebbe un cambiamento? L’algoritmo quindi classifica i modelli di errore da quelli che il codice gestisce particolarmente bene a quelli che gestisce male, costruendo una gerarchia della resilienza alle mutazioni che rivela in pratica ciò che il codice sembra progettato a proteggere.
Scoprire cosa il codice protegge maggiormente
Applicato al codice genetico standard, l’algoritmo recupera diversi fatti ben noti ma li estende. Conferma che non fare nulla (nessuna mutazione) è il caso più comune e meglio gestito e che i cambiamenti nella terza posizione del codone sono generalmente meno dannosi rispetto a quelli nella prima o nella seconda. Ribadisce inoltre che le “transizioni” — scambi all’interno della stessa famiglia di nucleotidi — tendono ad essere meglio tollerate delle “transversioni”, che saltano tra famiglie. Per approfondire, gli autori comprimono l’informazione: invece di tracciare esattamente gli amminoacidi, li raggruppano in tipi, ad esempio per come interagiscono con l’acqua o per la composizione A/T rispetto a G/C nei loro codoni. Questo aumenta la ridondanza e permette all’algoritmo di ricavare una gerarchia di mutazioni tollerate più lunga e dettagliata.
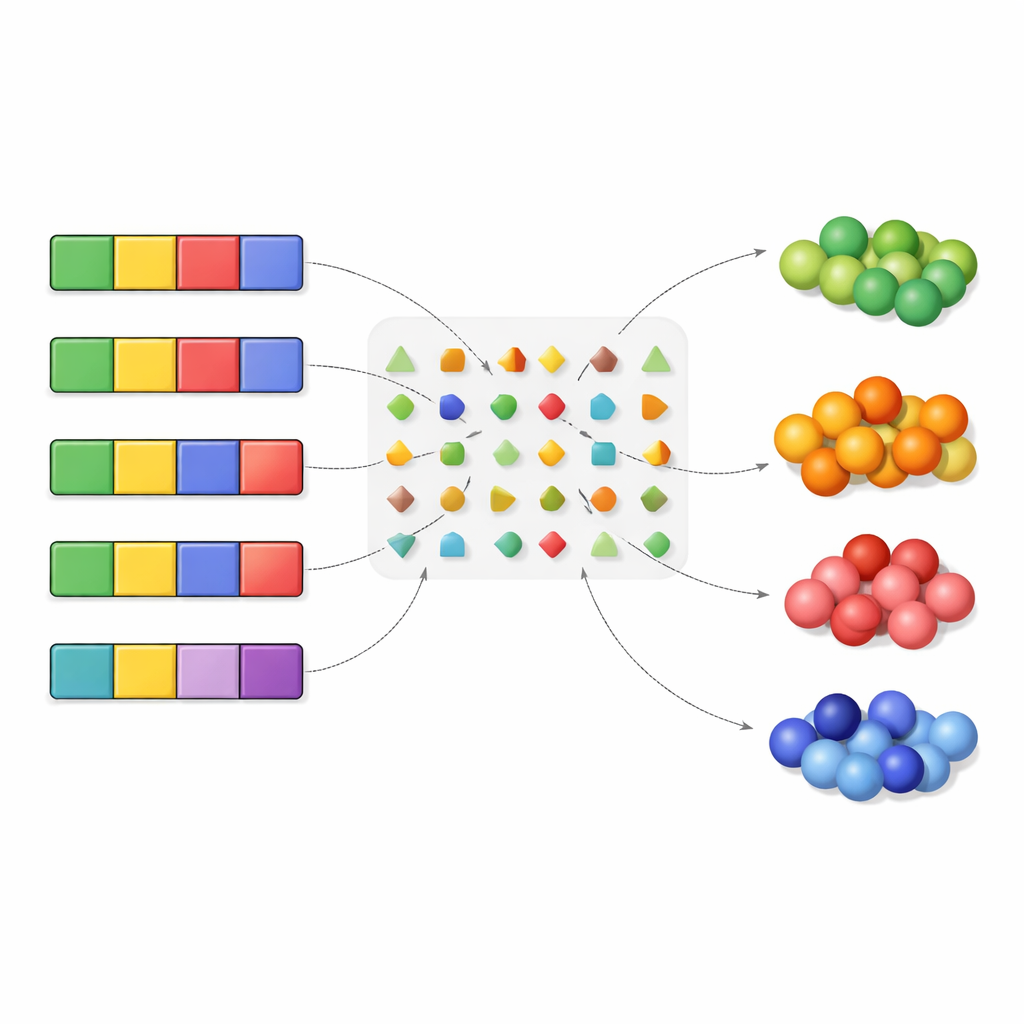
Priorità nascoste nella stabilità di proteine e DNA
Testando molti modi diversi di raggruppare gli amminoacidi, lo studio identifica quali raggruppamenti sono più naturalmente preservati dal codice. Due emergono con forza. Primo, l’idrofobicità — la tendenza degli amminoacidi a evitare l’acqua — è fortemente protetta. Le mutazioni che trasformerebbero un residuo che evita l’acqua nel nucleo di una proteina in uno che la preferisce sono relativamente svantaggiate. Secondo, sono preferenzialmente mantenuti certi equilibri specifici di A/T rispetto a G/C e di G/T rispetto a A/C nei codoni di un amminoacido. Questi schemi derivano dal modo in cui i codoni sinonimi sono disposti e dall’importanza particolare della seconda posizione nel codone, nota per influenzare fortemente se un amminoacido è idrofobico o idrofilo. Nel loro insieme, queste scoperte suggeriscono che il codice genetico è sintonizzato per proteggere sia la struttura delle proteine sia alcuni schemi nucleotidici sottostanti.
Cosa significa per la resilienza della vita
In termini semplici, questo lavoro mostra che il codice genetico si comporta molto come uno schema di correzione d’errori accuratamente progettato: è molto più indulgente rispetto ad alcuni tipi di cambiamenti nel DNA rispetto ad altri, in particolare quelli che lasciano intatti il comportamento idrico di un amminoacido e i rapporti chiave tra nucleotidi. L’algoritmo FEH fornisce un modo rigoroso per mettere in luce questa gerarchia di protezione incorporata senza fare affidamento su dati specifici per specie. Questo aiuta a spiegare perché lo stesso codice genetico è stato conservato in quasi tutta la vita sulla Terra e offre un nuovo quadro per studiare come le mutazioni si propagano dal DNA alle proteine — e perché certi cambiamenti sono particolarmente rilevanti.
Citazione: Aharon, A., Polak, P. & Yaari, G. Revealing the inherent design principles of the genetic code via an error correcting code representation. Sci Rep 16, 11035 (2026). https://doi.org/10.1038/s41598-026-39862-0
Parole chiave: codice genetico, robustezza alle mutazioni, codici a correzione d’errori, struttura delle proteine, evoluzione molecolare