Clear Sky Science · zh
利用学习到的表征与多任务学习发现赖氨酸甲基化位点
为什么微小的蛋白质标记对健康很重要
在每个细胞内部,蛋白质不断被加上小的化学标签,这些标签可以开启或关闭它们的活性。其中一种称为赖氨酸甲基化的标签有助于控制基因的工作方式,且与癌症和其他疾病的关联日益受到关注。然而,在数千种蛋白质上准确定位这些标记在实验室中既缓慢又昂贵。本研究介绍了 MethylSight 2.0,一种强大的计算模型,它扫描蛋白质序列并预测哪些赖氨酸可能被甲基化,帮助科学家更快地发现新的生物学现象和潜在药物靶点。
蛋白质上的隐性开关
蛋白质由氨基酸链组成,赖氨酸是细胞可以添加化学标签的关键位点之一。已知赖氨酸的甲基化调控着DNA在细胞核内的包装方式,从而影响哪些基因被打开或关闭。但许多赖氨酸甲基化事件发生在非组蛋白上,这些蛋白构成细胞骨架、驱动代谢并传递信号。若干负责添加这些标记的酶在癌症中活性过高,使其成为有吸引力的药物靶点。问题在于,在整个人类蛋白质组上实验性检测甲基化需要大量时间、资金和专用设备,因此研究人员转向预测工具,以便将实验工作集中在最有希望的位点上。
教计算机理解蛋白质的语言
作者在近期“蛋白质语言模型”的进展上展开工作,这类算法在数百万到数十亿条蛋白质序列上训练,学习将序列与结构和功能关联的模式。这些模型将蛋白质中每个氨基酸转换为丰富的数值表征,捕捉其化学环境和三维上下文。研究团队对每个赖氨酸及其邻近残基使用这些学习到的表征,测试了若干神经网络设计,包括较简单的多层感知器和更先进的 Transformer 架构。他们从公共数据库中精心整理训练数据,挑选高置信度的甲基化位点并构建现实的阴性样本,同时避免冗余以免夸大性能。
从其他化学修饰中学习
细胞不会孤立地修饰赖氨酸。同一位点可以被乙酰化、泛素化或 SUMO 化,这些标签可能相互竞争或协同,影响哪种修饰最终占优。研究者认为,与这些其他修饰相关的模式可以帮助模型更好地识别甲基化。他们将问题转为多任务设置,训练一个基于 Transformer 的单一网络同时预测四种赖氨酸修饰,并共享大部分内部参数。这种设置使得从一种修饰学到的知识能够增强对其他修饰的预测,尤其对已知样本较少的甲基化有明显帮助。
更好的预测与真实世界的验证
名为 MethylSight 2.0 的多任务 Transformer 模型在独立测试集上大幅优于以往工具,在一个关键准确度指标上超过老方法两倍多。使用对真实细胞中甲基化稀有性的现实估计,作者预测该模型即便在具有挑战性的条件下也能保持有用的精确度。随后他们将 MethylSight 2.0 应用于整个人类已审阅蛋白质组,并在保守阈值下预测出超过 60,000 个可能被甲基化的赖氨酸位点。从中挑选了 100 个候选位点用于靶向质谱实验证实,其中在 68 个位点检测到甲基化,表明模型的预测在实验室中具有良好的可转化性。
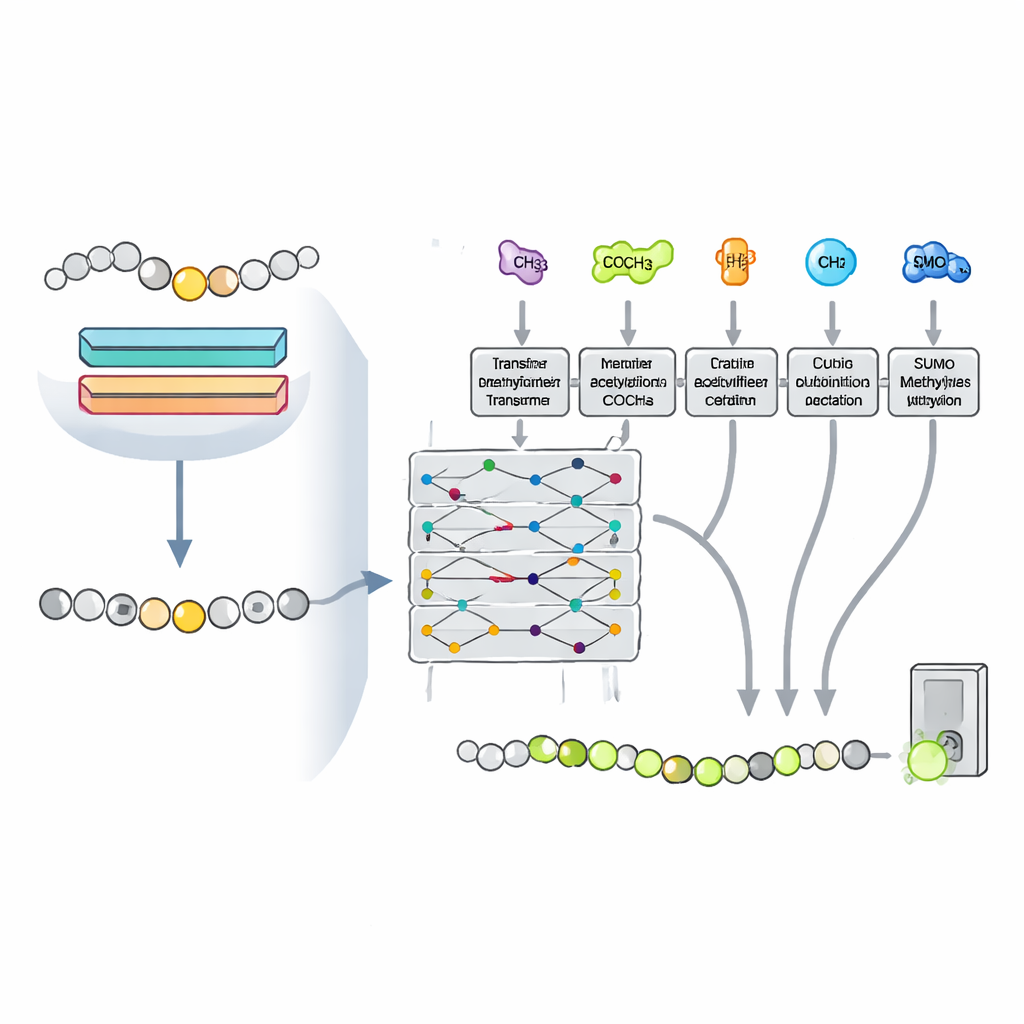
绘制日益扩展的蛋白质调控图谱
通过结合学习到的蛋白质表征、先进的神经网络和多任务训练,作者估计人类“赖氨酸甲基组”可能包含约 155,000 个位点——远比此前认识的更多。他们的分析显示,预测到的甲基化在参与翻译、RNA 加工和细胞骨架的蛋白中尤其富集,这与早期提示这些系统被化学标记精细调控的观点一致。由于 MethylSight 2.0 以公共网络服务器和可下载软件的形式提供,研究人员现在可以扫描感兴趣的蛋白、优先安排实验并更高效地寻找与疾病相关的甲基化事件。在实践层面,这项工作既提供了更清晰的地图,也提供了更可靠的指南,帮助探索蛋白质的微妙化学修饰如何影响健康与疾病。
引用: Charih, F., Boulter, M., Biggar, K.K. et al. Leveraging learned representations and multitask learning for lysine methylation site discovery. Sci Rep 16, 10212 (2026). https://doi.org/10.1038/s41598-026-39136-9
关键词: 赖氨酸甲基化, 翻译后修饰, 蛋白质语言模型, 蛋白质组学中的深度学习, 癌症表观遗传学