Clear Sky Science · pl
Wykorzystanie wyuczonych reprezentacji i uczenia wielozadaniowego do odkrywania miejsc metylacji lizyny
Dlaczego drobne oznaczenia białek mają znaczenie dla zdrowia
W każdej komórce białka są nieustannie modyfikowane małymi chemicznymi znacznikami, które mogą włączać lub wyłączać ich aktywność. Jednym z takich znaczników jest metylacja lizyny, która pomaga kontrolować działanie naszych genów i coraz częściej łączy się z rakiem oraz innymi chorobami. Znalezienie dokładnych miejsc tych oznaczeń w tysiącach białek jest jednak w laboratorium czasochłonne i kosztowne. W tej pracy przedstawiono MethylSight 2.0 — wydajny model komputerowy, który skanuje sekwencje białek i przewiduje, które reszty lizyny prawdopodobnie są metylowane, pomagając naukowcom szybciej odkrywać nową biologię i potencjalne cele terapeutyczne.
Ukryte przełączniki w białkach
Białka zbudowane są z łańcuchów aminokwasów, a lizyna jest jednym z kluczowych miejsc, gdzie komórki mogą dodawać chemiczne znaczniki. Metylacja lizyny jest już znana jako mechanizm kontrolujący pakowanie DNA w jądrze komórkowym, kształtując, które geny są włączane lub wyłączane. Jednak wiele zdarzeń metylacji lizyny występuje na białkach nie-histonowych, które tworzą szkielet komórki, napędzają jej procesy i przekazują sygnały. Kilka enzymów umieszczających te znaczniki jest nadaktywne w nowotworach, co czyni je atrakcyjnymi celami leków. Wyzwanie polega na tym, że eksperymentalne wykrywanie metylacji w całym ludzkim proteomie wymaga ogromnych nakładów czasu, pieniędzy i specjalistycznego sprzętu, dlatego badacze sięgają po narzędzia predykcyjne, aby ukierunkować prace laboratoryjne na najbardziej obiecujące miejsca.
Nauczanie komputerów języka białek
Autorzy budują na niedawnych postępach w „modelach językowych białek” — algorytmach trenowanych na milionach lub miliardach sekwencji białkowych, które uczą się wzorców łączących sekwencję ze strukturą i funkcją. Modele te przekształcają każdy aminokwas w białku w bogaty opis numeryczny, odzwierciedlający jego środowisko chemiczne i kontekst 3D. Korzystając z takich wyuczonych reprezentacji dla każdej lizyny i jej sąsiadów, zespół przetestował kilka architektur sieci neuronowych, w tym prostsze perceptrony wielowarstwowe oraz bardziej zaawansowaną architekturę transformera. Starannie skuratorowali dane treningowe z publicznych baz, wybierając miejsca metylacji wysokiego zaufania i konstruując realistyczne przykłady negatywne, jednocześnie unikając redundancji, która mogłaby zawyżyć wyniki.
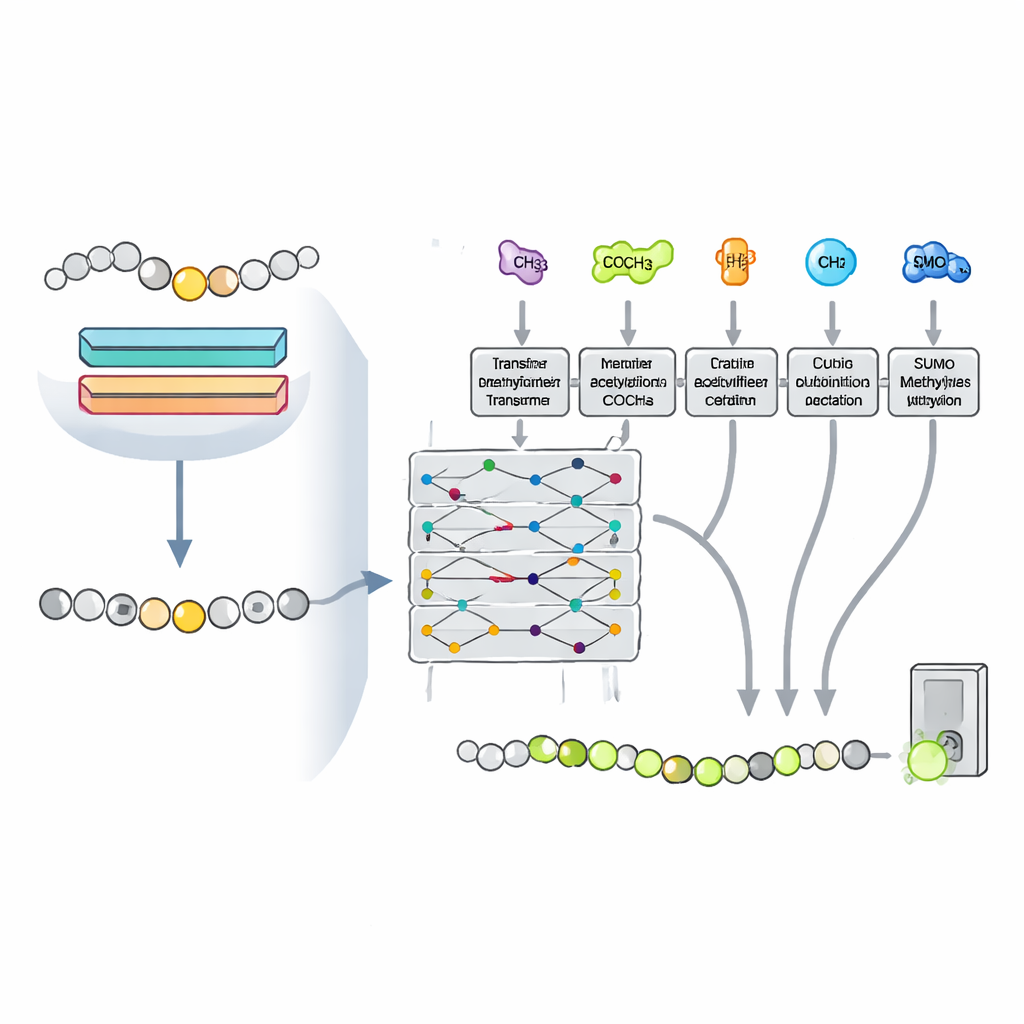
Uczenie się od innych oznaczeń chemicznych
Komórki nie oznaczają lizyny w izolacji. Ta sama pozycja może być acetylowana, ubikwitynowana lub sumoilowana, a te znaczniki mogą konkurować lub współdziałać, wpływając na to, która modyfikacja przeważy. Badacze założyli, że wzorce związane z tymi innymi oznaczeniami mogą pomóc modelowi lepiej rozpoznawać metylację. Przekształcili zadanie w ustawienie wielozadaniowe, trenując jedną sieć opartą na transformerze do przewidywania czterech modyfikacji lizyny jednocześnie, przy dzieleniu większości wewnętrznych parametrów. Takie rozwiązanie pozwala, by wiedza zdobyta dla jednego rodzaju modyfikacji wzmocniła predykcje dla pozostałych, zwłaszcza dla metylacji, dla której znanych jest mniej przykładów.
Lepsze przewidywania i potwierdzenie w praktyce
Model wielozadaniowy oparty na transformerze, nazwany MethylSight 2.0, przewyższył poprzednie narzędzia znacząco na niezależnym zestawie testowym, ponad dwukrotnie poprawiając kluczowy wskaźnik dokładności w porównaniu ze starszymi metodami. Używając realistycznych szacunków rzadkości metylacji w komórkach, autorzy przewidują, że model utrzymuje użyteczną precyzję nawet w trudnych warunkach. Następnie zastosowali MethylSight 2.0 do całego przeglądanego ludzkiego proteomu i, stosując konserwatywne progi, przewidzieli ponad 60 000 prawdopodobnych metylowanych lizyn. Z tej puli wybrali 100 kandydatów do ukierunkowanych eksperymentów za pomocą spektrometrii mas i wykryli metylację w 68 z nich, co sugeruje, że przewidywania modelu dobrze przekładają się na rzeczywistość laboratoryjną.
Mapowanie rosnącego pejzażu kontroli białek
Łącząc wyuczone reprezentacje białek, zaawansowaną sieć neuronową i trening wielozadaniowy, autorzy szacują, że ludzki „metylom lizynowy” może zawierać około 155 000 miejsc — znacznie więcej niż wcześniej sądzono. Ich analiza pokazuje, że przewidywana metylacja jest szczególnie wzbogacona w białkach zaangażowanych w translację, przetwarzanie RNA i cytoszkielet, co jest zgodne z wcześniejszymi wskazówkami, że systemy te są ściśle regulowane przez chemiczne oznaczenia. Ponieważ MethylSight 2.0 jest dostępny jako publiczny serwer internetowy i do pobrania jako oprogramowanie, badacze mogą teraz skanować interesujące ich białka, priorytetyzować eksperymenty i efektywniej poszukiwać modyfikacji istotnych dla chorób. W praktycznym ujęciu praca ta dostarcza zarówno ostrzejszej mapy, jak i lepszego kompasu do badania, jak subtelne chemiczne poprawki białek kształtują zdrowie i choroby.
Cytowanie: Charih, F., Boulter, M., Biggar, K.K. et al. Leveraging learned representations and multitask learning for lysine methylation site discovery. Sci Rep 16, 10212 (2026). https://doi.org/10.1038/s41598-026-39136-9
Słowa kluczowe: metylacja lizyny, modyfikacja potranslacyjna, modele językowe białek, uczenie głębokie w proteomice, epigenetyka nowotworowa