Clear Sky Science · zh
最低语义内容(MSC)数据集:一个用于计算美学研究的大型、平衡资源
为什么图片中的美比看起来更难测量
为什么有些照片让我们觉得美丽,而另一些则显得平淡甚至丑陋?你可能认为科学家可以通过测量图像的颜色、对比度或图案来回答这个问题。但问题在于:我们的反应与图片所展示的内容——人物、地点、符号和记忆——交织在一起。本文介绍了一个新的、经过精心设计的图像集合,试图剥除这些干扰,使研究者能集中研究眼睛和大脑对图像本身外观的反应。
把故事从画面中移走
大多数研究中常用的热门图像数据库来自在线照片分享网站和比赛。这些来源带有标题、主题和文化参照,会悄悄地影响人们的评分。契合比赛主题的巧妙笑点可能让一张平庸的照片获胜。强烈的符号,比如国旗,常常因文化原因而得高分,而非视觉因素。此外,人们很少上传真正糟糕的照片,因此现有数据库充斥着外观尚可或更好的图片。综合起来,这使得很难判断高评分是源于图像的构成——它的颜色、纹理和形状——还是源于它所代表的含义。 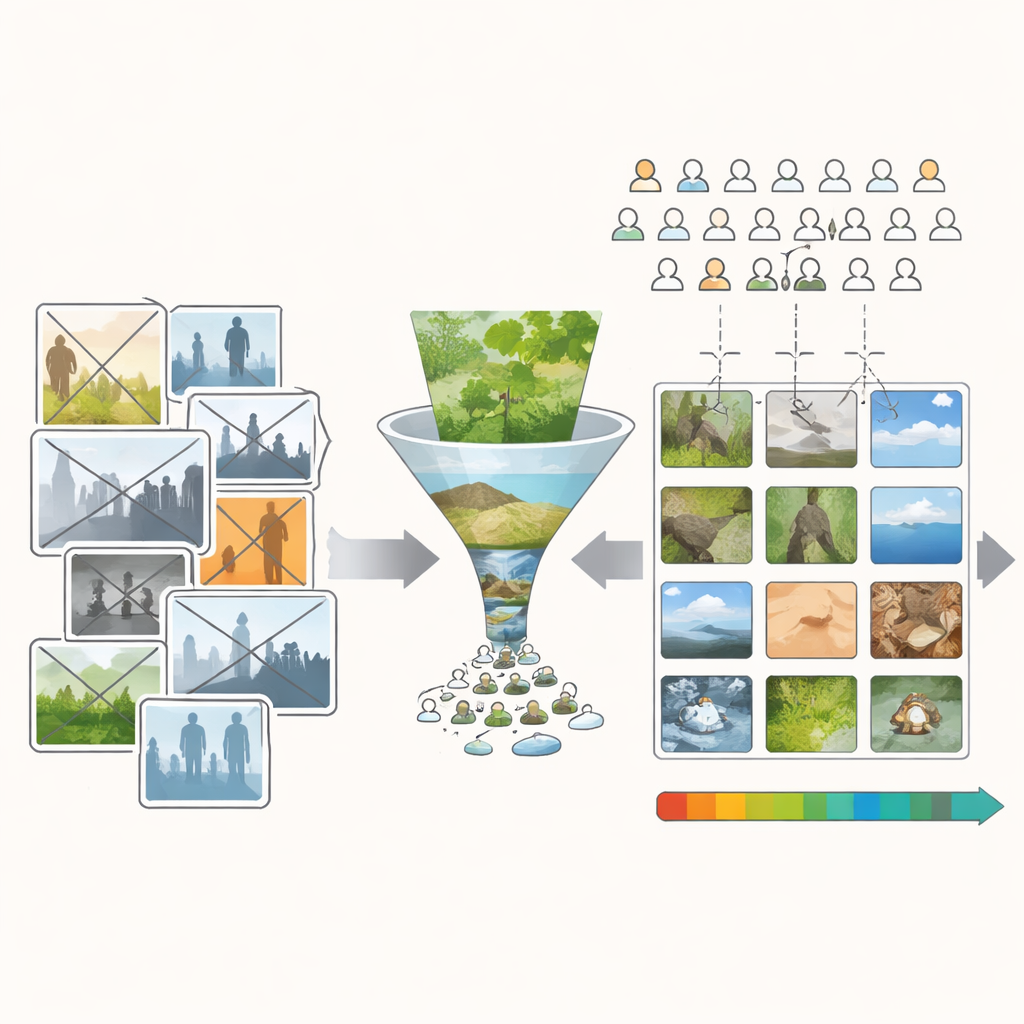
构建一个宁静场景的世界
为了解决这个问题,作者创建了最低语义内容(MSC)数据库:超过一万张图像,选择时力求视觉丰富但“故事”含量尽可能低。研究者从公有领域照片和个人收藏开始,移除了任何含有人物、动物、建筑、文字或明显符号性物体的图片。他们还避免选择那种易于唤起强烈记忆或情感的明信片式景观。剩下的大多是自然元素——叶子、树皮、岩石、云朵、水面和林地地表。这些场景并非完全没有意义,但在主题上要均一得多。这使得人们判断差异更可能来自色彩、光线和结构等视觉特性,而不是来自被描绘的对象或人物。
发明一个按需制造美或丑的工具
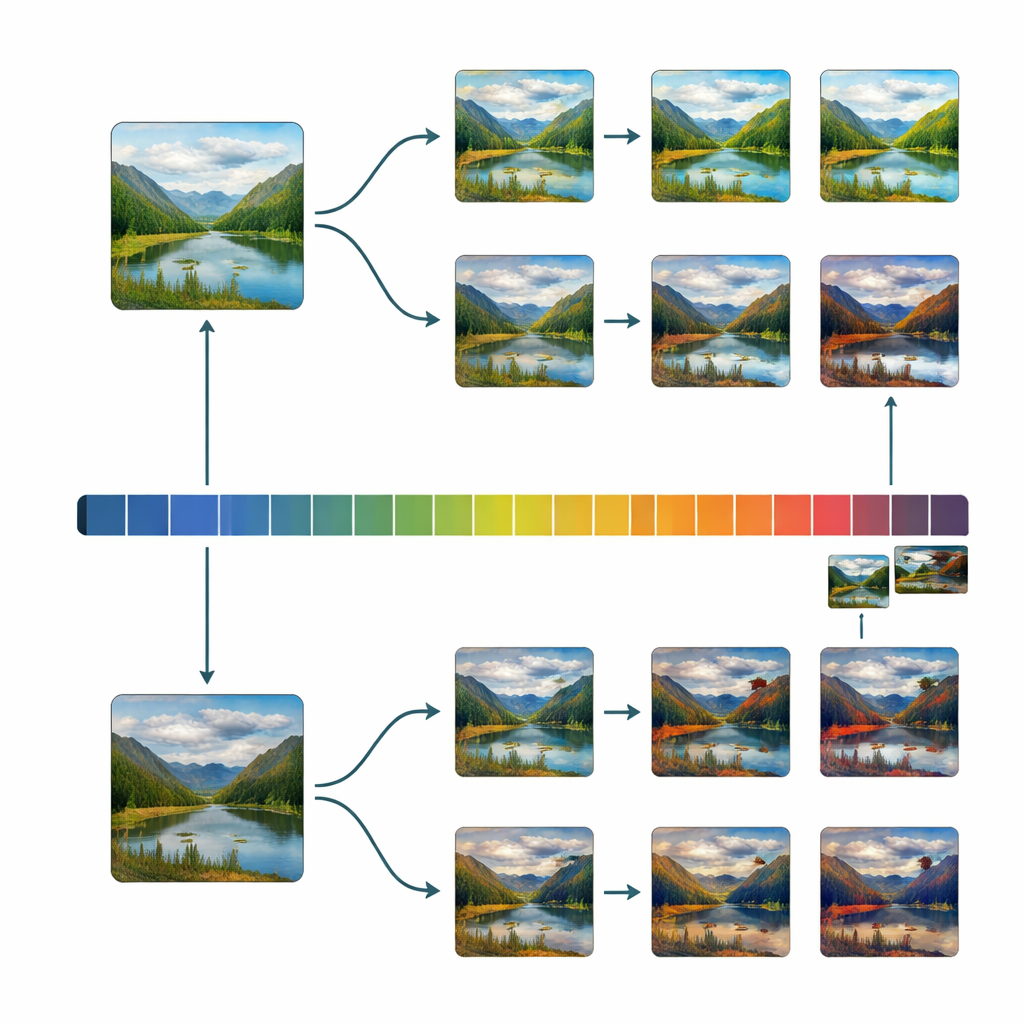
即便经过如此谨慎的筛选,起始集合仍偏向赏心悦目的图像。要在美学上做到科学严谨,研究者需要大量样本,均匀分布在非常丑到非常美之间。因此团队构建了一个简单的编辑程序,昵称为“丑化器”。四十位志愿者使用它把选定图像推向两个方向:尽可能美化或尽可能丑化,通过调整亮度、对比度、色彩混合、锐度、噪点、裁剪以及若干更高级的变换。研究者还记录了一些编辑配方并将其自动应用于其他图像,生成大量额外的“丑化”变体。由此产生了原图、美化、丑化和自动丑化场景的广泛混合。
让几千人用眼睛投票
接着,作者借助内置于一款在线游戏的众包平台,招募了来自世界各地的一万多名玩家。MSC中每张图像都展示给一百名不同的非专业观众,他们在一个简单的五点量表上对图像的美感进行评分,范围从非常丑到非常美。极端的训练示例帮助参与者使用量表的完整范围。谨慎的质量检查剔除了那些似乎随机点击的玩家。最终结果是一个每个场景都有丰富评分记录的图像集合,丑、普通和美的图像都有良好代表性,而不是集中在中间。
这对美与视觉结构揭示了什么
有了这个平衡的数据集,团队检查了几十种基本图像属性——如对比度、颜色变异、边缘密度、对称性和类分形纹理——与美感评分的关系。他们发现,当分数在丑—美范围内均匀分布时,这些低层属性与人们判断之间的关联变得更清晰且常常更强。在某些情况下,与旧的、有偏数据库中观察到的关系方向甚至会发生翻转。他们还检验了丑化器是否产生了一种狭窄、人工的丑;结果显示,经过编辑的图像在基本统计特性上与自然低分原图相似,表明这些操作捕捉到的是真实的视觉倾向,而非漫画式的极端。
这为何有助于理解品味
对普通读者来说,结论是科学家现在可以用更清晰的方式研究视觉品味。MSC数据库提供了一个宁静、以自然场景为主的世界,在这里美与丑主要取决于事物的外观,而非其代表的对象或人物。这使其成为心理学、神经科学和人工智能等领域的强大测试平台,旨在仅从图像结构预测审美偏好。之后可以逐步把更复杂的意义和文化语境叠加回去。通过从那些“话语很少却外观各异”的图片出发,MSC项目有助于澄清我们对美的感觉有多少是来自眼睛在心智加入故事之前的直观反应。
引用: Penacchio, O., Javed, A., Raducanu, B. et al. The Minimum Semantic Content (MSC) Dataset: A Large, Balanced Resource for Computational Aesthetics Research. Sci Data 13, 470 (2026). https://doi.org/10.1038/s41597-026-06816-0
关键词: 视觉美学, 图像数据库, 众包评分, 计算美, 自然纹理