Clear Sky Science · en
The Minimum Semantic Content (MSC) Dataset: A Large, Balanced Resource for Computational Aesthetics Research
Why beauty in pictures is harder to measure than it seems
Why do some photos strike us as beautiful while others feel dull or even ugly? You might think scientists could answer this by measuring colors, contrast, or patterns in a picture. But there is a problem: our reactions are tangled up with what the picture shows—people, places, symbols, and memories. This article introduces a new, carefully designed image collection that tries to strip away those distractions so researchers can focus on how the eye and brain respond to the raw look of an image itself.
Taking the story out of the picture
Most popular image databases used in research are built from online photo-sharing sites and contests. These sources come with titles, themes, and cultural references that quietly steer how people rate them. A clever joke that fits a contest theme can make a mediocre-looking picture win. Strong symbols, such as flags, can score highly for cultural reasons rather than visual ones. On top of that, people rarely upload truly bad photos, so existing databases are crowded with pictures that are decent or better. Together, this makes it very hard to tell whether a high rating comes from the way an image is built—its colors, textures, and shapes—or from what it means. 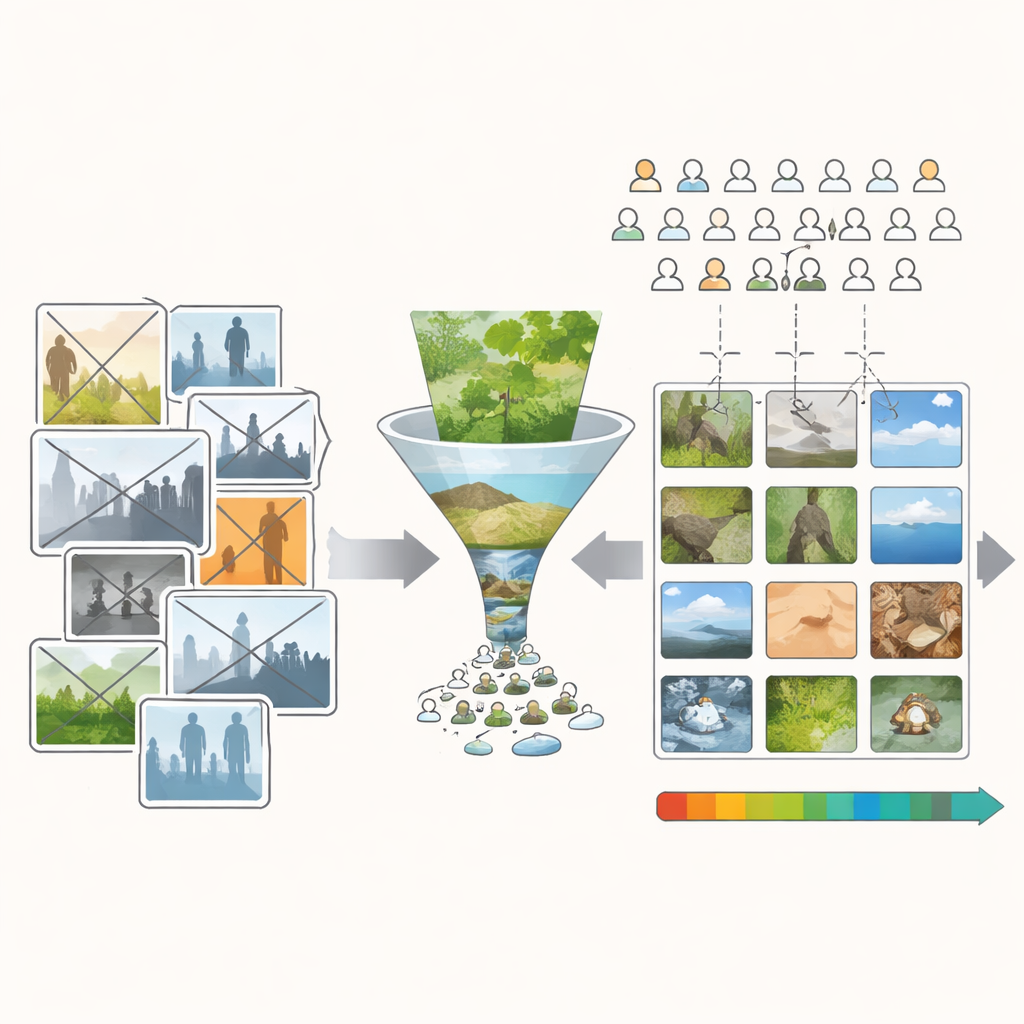
Building a world of quiet scenes
To tackle this, the authors created the Minimum Semantic Content (MSC) database: over ten thousand images chosen to be visually rich but as low in “story” as possible. They began with public-domain photos and personal collections, then removed any pictures with people, animals, buildings, writing, or strong symbolic objects. They also avoided postcard-style views likely to stir strong memories or emotions. What remains are mostly bits of nature—leaves, bark, rocks, clouds, water surfaces, and forest floors. These scenes are not completely meaningless, but they are far more uniform in subject matter. That makes differences in people’s judgments more likely to come from visual qualities such as color, light, and structure rather than from who or what is depicted.
Inventing a tool to make beauty and ugliness on demand
Even with this careful filtering, the starting collection still leaned toward pleasant-looking images. To get a good scientific grip on beauty, researchers need many examples spread evenly from very ugly to very beautiful. The team therefore built a simple editing program nicknamed the “Uglifier.” Forty volunteers used it to push selected images in two directions: make them as beautiful as possible, or as ugly as possible, by adjusting sliders for brightness, contrast, color mix, sharpness, noise, cropping, and a few more advanced transformations. The researchers also recorded some of these editing recipes and applied them automatically to other images, adding a large batch of extra “ugly” variants. This produced a broad mix of originals, beautified, uglified, and automatically uglified scenes.
Asking thousands of people to vote with their eyes
Next, the authors turned to a crowdsourcing platform built into an online game, recruiting more than ten thousand players around the world. Each image in the MSC set was shown to one hundred different non-expert viewers, who rated its beauty on a simple five-point scale from very ugly to very beautiful. Training examples at the extremes helped people use the full range of the scale. Careful quality checks removed players who seemed to click randomly. The final result is an image collection where every scene is backed by a rich rating history, and where ugly, average, and beautiful images are all well represented rather than bunched in the middle.
What this reveals about beauty and visual structure
With this balanced dataset in hand, the team examined how dozens of basic image properties—such as contrast, color variability, edge density, symmetry, and fractal-like texture—relate to beauty ratings. They found that when scores are spread evenly across the ugly–beautiful range, connections between these low-level properties and people’s judgments become clearer and often stronger. In some cases, the direction of the relationship even flips compared with what is seen in older, biased databases. They also checked whether the Uglifier produced a narrow, artificial kind of ugliness; instead, the edited images turned out to share similar basic statistics with naturally low-rated originals, suggesting that the manipulations captured real visual tendencies rather than cartoonish extremes. 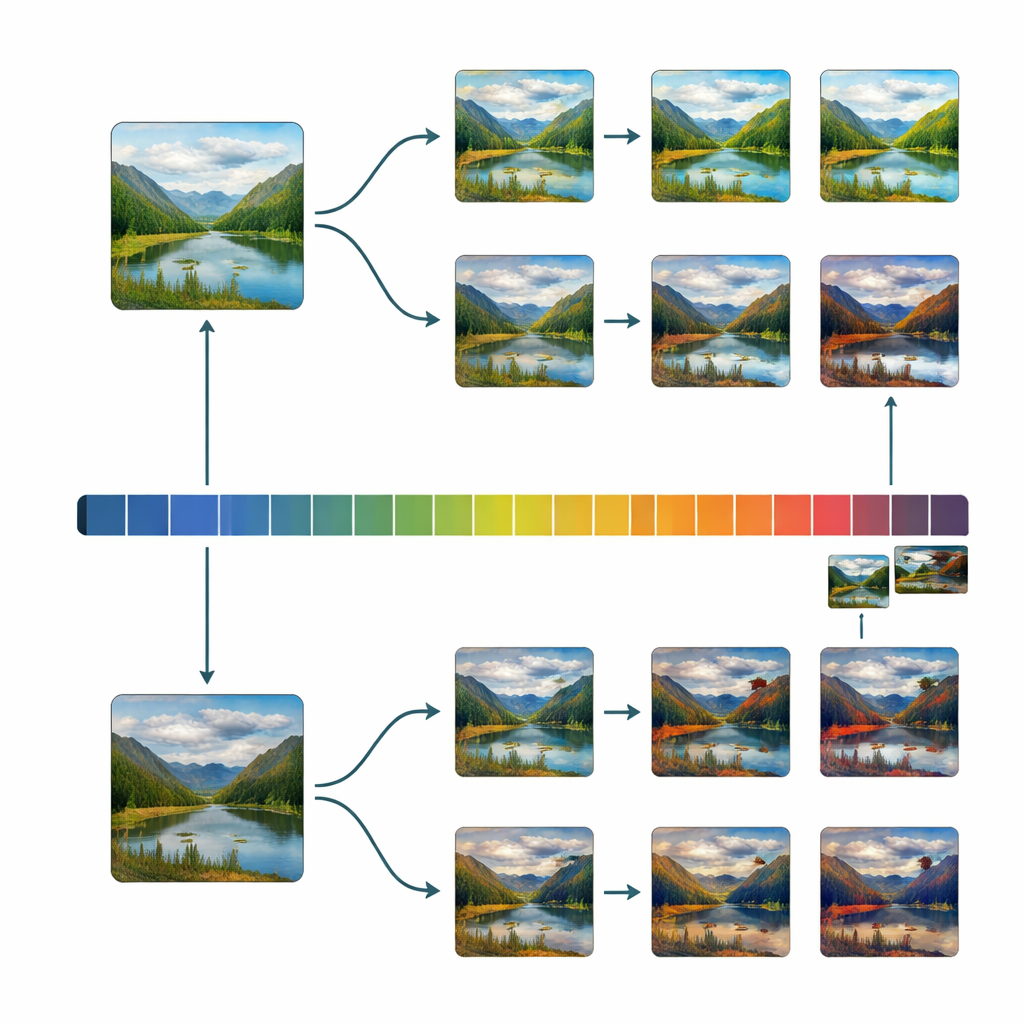
Why this matters for understanding taste
To a lay viewer, the takeaway is that scientists can now study visual taste in a cleaner way. The MSC database offers a world of quiet, mostly natural scenes where beauty and ugliness depend mainly on how things look, not on who or what they represent. This makes it a powerful test bed for psychology, neuroscience, and artificial intelligence research that aims to predict aesthetic preference from the structure of images alone. Later, more complex meaning and cultural context can be layered back in. By starting with pictures that say very little and look very different, the MSC project helps clarify how much of our sense of beauty arises from the eye before the mind adds its stories.
Citation: Penacchio, O., Javed, A., Raducanu, B. et al. The Minimum Semantic Content (MSC) Dataset: A Large, Balanced Resource for Computational Aesthetics Research. Sci Data 13, 470 (2026). https://doi.org/10.1038/s41597-026-06816-0
Keywords: visual aesthetics, image database, crowdsourced ratings, computational beauty, natural textures