Clear Sky Science · pt
O Conjunto de Dados Mínimo de Conteúdo Semântico (MSC): Um Recurso Grande e Balanceado para Pesquisa em Estética Computacional
Por que a beleza em imagens é mais difícil de medir do que parece
Por que algumas fotos nos parecem belas enquanto outras soam monótonas ou até feias? Você pode pensar que os cientistas poderiam responder medindo cores, contraste ou padrões numa imagem. Mas há um problema: nossas reações se misturam com o que a imagem mostra — pessoas, lugares, símbolos e memórias. Este artigo apresenta uma nova coleção de imagens cuidadosamente projetada que tenta afastar essas distrações para que os pesquisadores possam focar em como o olho e o cérebro respondem à aparência bruta da própria imagem.
Tirando a história da imagem
A maioria das bases de imagens populares usadas em pesquisa é construída a partir de sites de compartilhamento de fotos e concursos online. Essas fontes vêm com títulos, temas e referências culturais que silenciosamente influenciam como as pessoas as avaliam. Uma piada esperta que se encaixa no tema de um concurso pode fazer uma foto mediana vencer. Símbolos fortes, como bandeiras, podem receber notas altas por razões culturais em vez de visuais. Além disso, as pessoas raramente publicam fotos realmente ruins, então bases existentes costumam estar repletas de imagens que são razoáveis ou melhores. Junto, isso torna muito difícil dizer se uma nota alta vem da forma como uma imagem foi construída — suas cores, texturas e formas — ou do que ela significa. 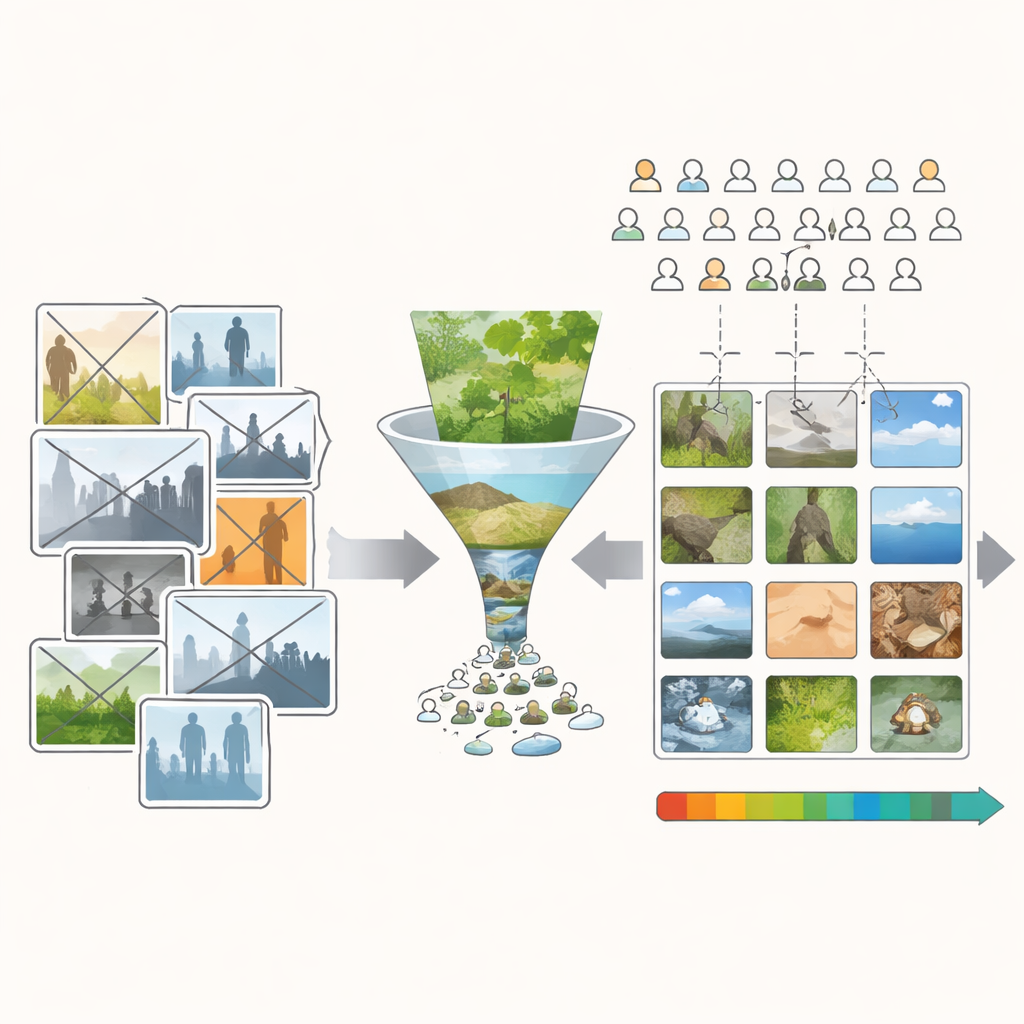
Construindo um mundo de cenas discretas
Para enfrentar isso, os autores criaram o banco de dados Minimum Semantic Content (MSC): mais de dez mil imagens escolhidas para ser visualmente ricas, mas com o mínimo possível de “história”. Eles começaram com fotos de domínio público e coleções pessoais, depois removeram qualquer imagem com pessoas, animais, edifícios, escrita ou objetos simbólicos fortes. Também evitaram vistas tipo cartão-postal que provavelmente evocariam memórias ou emoções intensas. O que resta são em sua maioria pedaços da natureza — folhas, casca, pedras, nuvens, superfícies de água e o chão da floresta. Essas cenas não são completamente desprovidas de significado, mas são muito mais uniformes quanto ao assunto. Isso faz com que diferenças nos julgamentos das pessoas tenham mais probabilidade de vir de qualidades visuais como cor, luz e estrutura do que de quem ou do que é retratado.
Inventando uma ferramenta para gerar beleza e feiura sob demanda
Mesmo com essa filtragem cuidadosa, a coleção inicial ainda tendia para imagens agradáveis. Para obter um controle científico melhor sobre a beleza, os pesquisadores precisavam de muitos exemplos distribuídos uniformemente do muito feio ao muito belo. A equipe, portanto, construiu um programa de edição simples apelidado de “Uglifier” (Feiificador). Quarenta voluntários o usaram para empurrar imagens selecionadas em duas direções: torná-las o mais bonitas possível, ou o mais feias possível, ajustando controles deslizantes de brilho, contraste, mistura de cores, nitidez, ruído, corte e algumas transformações avançadas. Os pesquisadores também registraram algumas dessas “receitas” de edição e as aplicaram automaticamente a outras imagens, adicionando um grande lote de variantes “feias” extras. Isso produziu uma ampla mistura de originais, embelezadas, feiificadas e feiificadas automaticamente.
Pedir a milhares de pessoas que votem com os olhos
Em seguida, os autores recorreram a uma plataforma de crowdsourcing integrada a um jogo online, recrutando mais de dez mil jogadores ao redor do mundo. Cada imagem do conjunto MSC foi mostrada a cem espectadores leigos diferentes, que avaliaram sua beleza em uma escala simples de cinco pontos, de muito feio a muito belo. Exemplos de treinamento nas extremidades ajudaram as pessoas a usar toda a amplitude da escala. Verificações cuidadosas de qualidade removeram jogadores que pareciam clicar aleatoriamente. O resultado final é uma coleção de imagens em que cada cena é respaldada por um histórico de avaliações rico, e onde imagens feias, médias e belas estão bem representadas em vez de concentradas no meio.
O que isso revela sobre beleza e estrutura visual
Com esse conjunto balanceado em mãos, a equipe examinou como dezenas de propriedades básicas da imagem — como contraste, variabilidade de cor, densidade de bordas, simetria e textura com padrão fractal — se relacionam com as avaliações de beleza. Eles descobriram que, quando as pontuações estão distribuídas uniformemente ao longo do espectro feio–belo, as conexões entre essas propriedades de baixo nível e os julgamentos das pessoas ficam mais claras e frequentemente mais fortes. Em alguns casos, a direção da relação até se inverte em comparação com o que se vê em bases antigas e enviesadas. Eles também verificaram se o Uglifier produziu um tipo estreito e artificial de feiura; em vez disso, as imagens editadas mostraram estatísticas básicas similares às dos originais naturalmente mal avaliados, sugerindo que as manipulações capturaram tendências visuais reais em vez de extremos caricaturais. 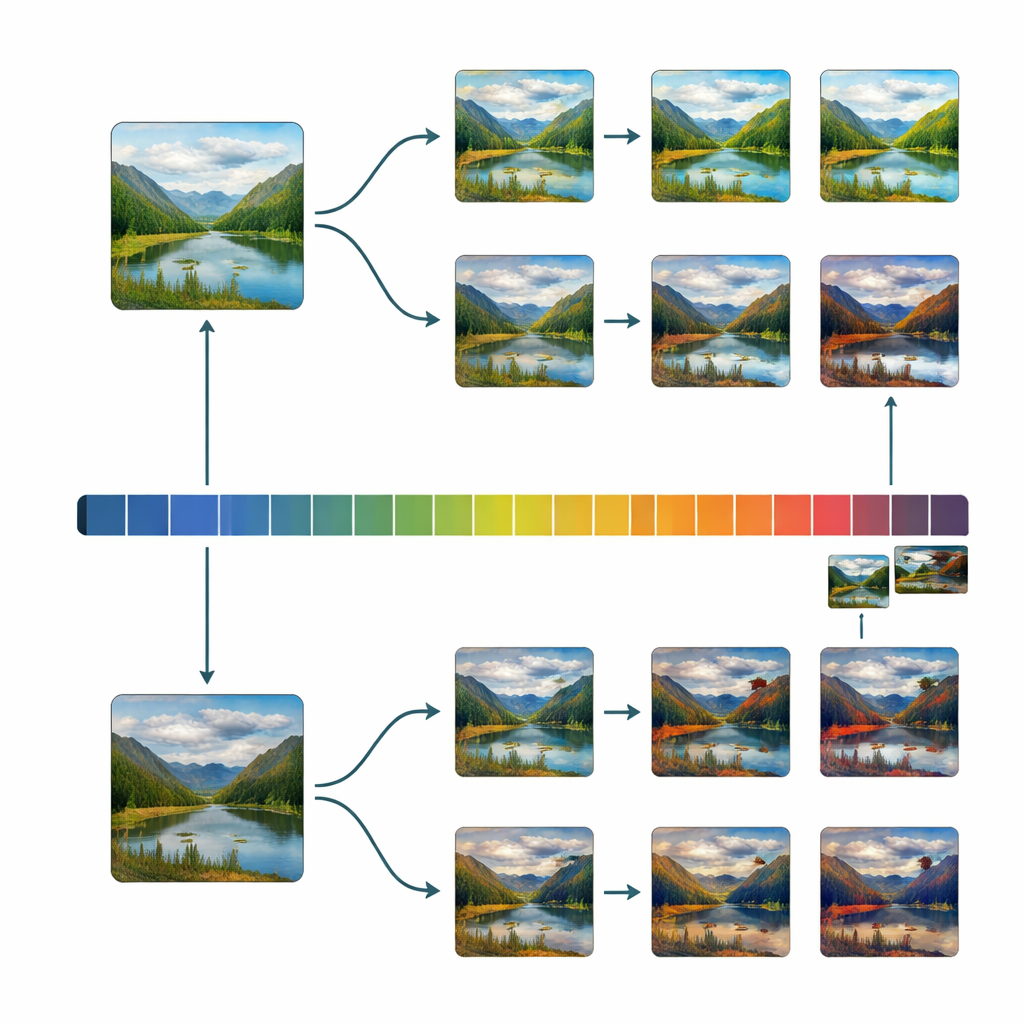
Por que isso importa para entender o gosto
Para um leitor leigo, a conclusão é que os cientistas agora podem estudar o gosto visual de maneira mais limpa. O banco de dados MSC oferece um mundo de cenas discretas, majoritariamente naturais, onde beleza e feiura dependem principalmente de como as coisas parecem, não de quem ou do que representam. Isso o torna um campo de testes poderoso para psicologia, neurociência e pesquisa em inteligência artificial que busca prever preferência estética a partir da estrutura das imagens sozinha. Mais tarde, significados mais complexos e contextos culturais podem ser reincorporados. Ao começar com imagens que dizem muito pouco e têm aparências muito diferentes, o projeto MSC ajuda a esclarecer quanto do nosso senso de beleza surge do olho antes que a mente acrescente suas histórias.
Citação: Penacchio, O., Javed, A., Raducanu, B. et al. The Minimum Semantic Content (MSC) Dataset: A Large, Balanced Resource for Computational Aesthetics Research. Sci Data 13, 470 (2026). https://doi.org/10.1038/s41597-026-06816-0
Palavras-chave: estética visual, base de imagens, avaliações por crowdsourcing, beleza computacional, texturas naturais