Clear Sky Science · it
Il dataset del Contenuto Semantico Minimo (MSC): Una risorsa ampia e bilanciata per la ricerca sull’estetica computazionale
Perché la bellezza nelle immagini è più difficile da misurare di quanto sembri
Perché alcune foto ci sembrano belle mentre altre risultano piatte o addirittura brutte? Si potrebbe pensare che gli scienziati possano rispondere misurando colori, contrasto o pattern presenti in un’immagine. Ma c’è un problema: le nostre reazioni sono intrecciate con ciò che l’immagine rappresenta — persone, luoghi, simboli e ricordi. Questo articolo presenta una nuova raccolta di immagini progettata con cura che cerca di eliminare queste distrazioni in modo che i ricercatori possano concentrarsi su come occhi e cervello rispondono al puro aspetto visivo di un’immagine.
Rimuovere la storia dall’immagine
La maggior parte dei database di immagini usati in ricerca proviene da siti di condivisione fotografica e concorsi online. Queste fonti portano con sé titoli, temi e riferimenti culturali che influenzano silenziosamente le valutazioni. Una battuta arguta che si adatta a un tema di concorso può far vincere una foto dall’aspetto mediocre. Simboli forti, come bandiere, possono ottenere punteggi elevati per ragioni culturali più che visive. Inoltre, le persone raramente caricano foto davvero brutte, quindi i database esistenti sono pieni di immagini decenti o migliori. Insieme, questi fattori rendono molto difficile stabilire se un punteggio alto derivi dalla costruzione visiva dell’immagine — colori, texture e forme — o dal suo significato. 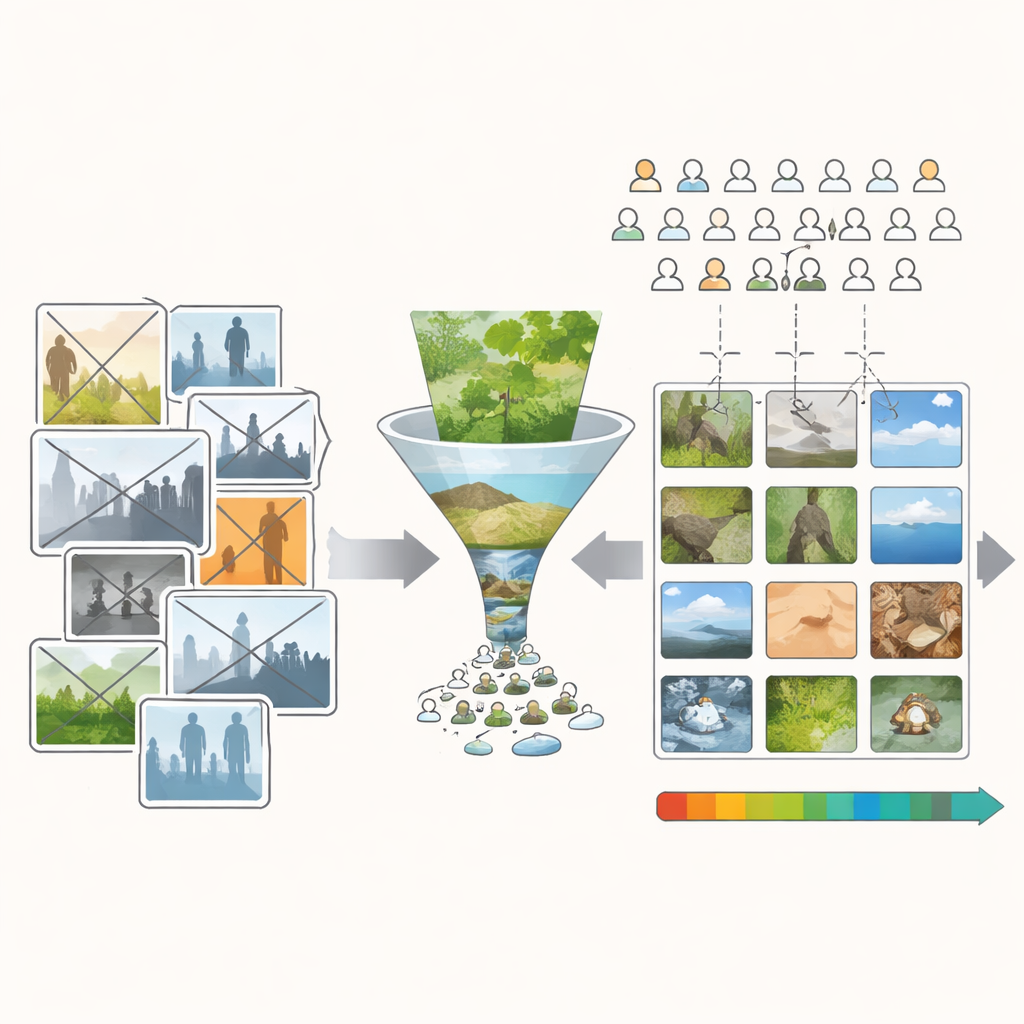
Costruire un mondo di scene tranquille
Per affrontare il problema, gli autori hanno creato il database Minimum Semantic Content (MSC): oltre diecimila immagini scelte per essere ricche dal punto di vista visivo ma il più possibile povere di “storia”. Hanno iniziato con foto di dominio pubblico e collezioni personali, poi hanno rimosso ogni immagine contenente persone, animali, edifici, scritte o oggetti simbolici forti. Hanno anche evitato vedute in stile cartolina che potrebbero suscitare ricordi o emozioni intense. Ciò che rimane sono per lo più frammenti di natura — foglie, cortecce, sassi, nuvole, superfici d’acqua e letti di bosco. Queste scene non sono completamente prive di significato, ma sono molto più uniformi per soggetto. Questo rende più probabile che le differenze nei giudizi delle persone derivino da qualità visive come colore, luce e struttura piuttosto che da chi o cosa è raffigurato.
Inventare uno strumento per creare bellezza e bruttezza su richiesta
Anche con questo accurato filtraggio, la raccolta iniziale tendeva comunque verso immagini piacevoli. Per ottenere una base scientifica solida sulla bellezza, i ricercatori avevano bisogno di molti esempi distribuiti uniformemente dal molto brutto al molto bello. Il team ha quindi costruito un semplice programma di editing soprannominato “Uglifier” (Il Bruttificatore). Quaranta volontari lo hanno usato per spingere immagini selezionate in due direzioni: renderle il più belle possibile o il più brutte possibile, regolando cursori per luminosità, contrasto, bilanciamento dei colori, nitidezza, rumore, ritaglio e alcune trasformazioni avanzate. I ricercatori hanno anche registrato alcune di queste “ricette” di modifica e le hanno applicate automaticamente ad altre immagini, aggiungendo un grande gruppo di varianti “brutte” generate automaticamente. Ne è derivata una miscela ampia di originali, abbellite, inbruttite e varianti inbruttite automaticamente.
Chiedere a migliaia di persone di votare con gli occhi
Successivamente, gli autori hanno utilizzato una piattaforma di crowdsourcing integrata in un gioco online, reclutando più di diecimila giocatori nel mondo. Ogni immagine del set MSC è stata mostrata a cento spettatori non esperti diversi, che l’hanno valutata su una semplice scala a cinque punti dal molto brutto al molto bello. Esempi di addestramento agli estremi hanno aiutato le persone a usare l’intera gamma della scala. Controlli di qualità accurati hanno rimosso i giocatori che sembravano cliccare a caso. Il risultato finale è una collezione di immagini in cui ogni scena è supportata da una ricca storia di valutazioni, e in cui immagini brutte, nella media e belle sono tutte ben rappresentate invece che concentrate al centro.
Cosa rivela questo sulla bellezza e la struttura visiva
Con questo dataset bilanciato a disposizione, il team ha esaminato come decine di proprietà di base dell’immagine — come contrasto, variabilità del colore, densità dei bordi, simmetria e texture di tipo frattale — si relazionano alle valutazioni di bellezza. Hanno scoperto che quando i punteggi sono distribuiti uniformemente lungo la gamma brutto–bello, le connessioni tra queste proprietà a basso livello e i giudizi delle persone diventano più chiare e spesso più forti. In alcuni casi, la direzione della relazione si inverte rispetto a quanto osservato in database più vecchi e distorti. Hanno anche verificato se l’Uglifier producesse un tipo di bruttezza stretto e artificiale; invece, le immagini modificate si sono rivelate condividere statistiche di base simili a quelle degli originali con valutazioni naturalmente basse, suggerendo che le manipolazioni catturano tendenze visive reali più che estremi caricaturali. 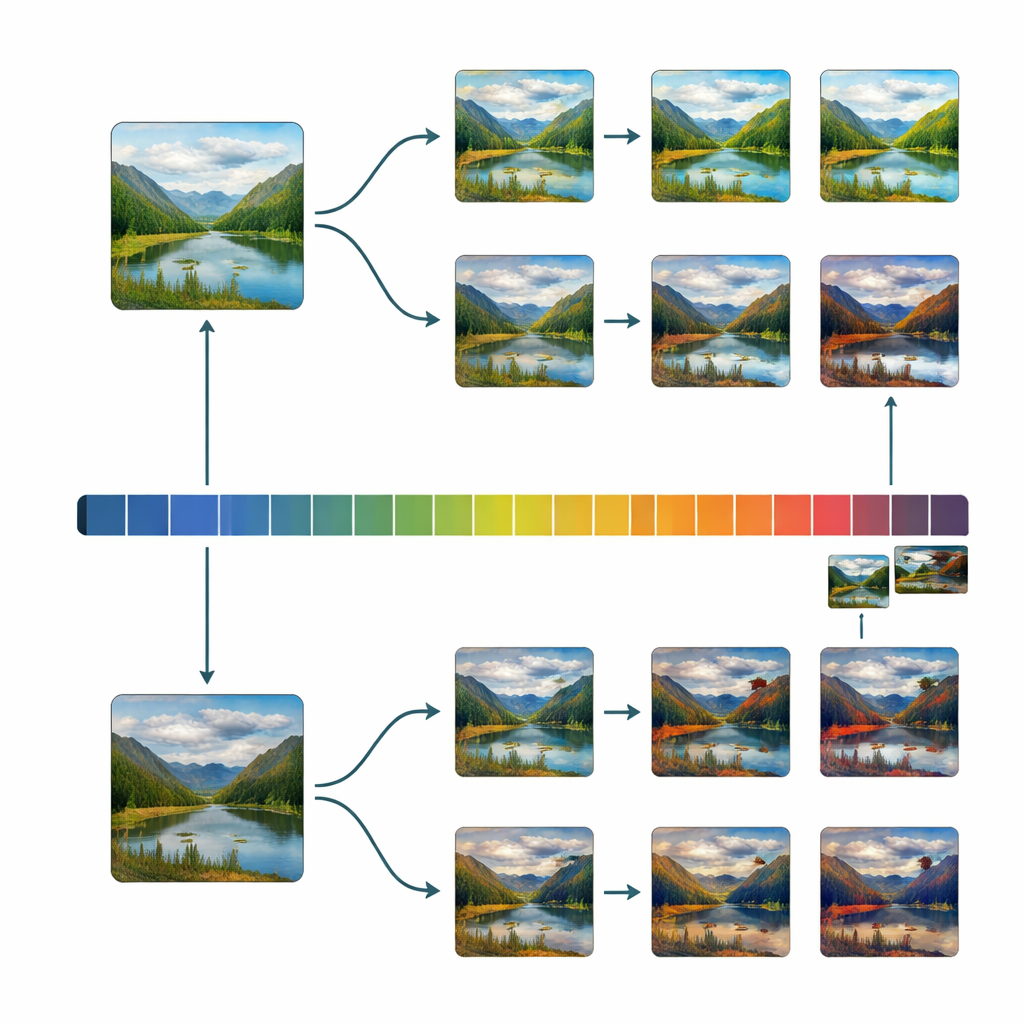
Perché questo è importante per capire il gusto
Per un lettore non specialista, la conclusione è che gli scienziati possono ora studiare il gusto visivo in modo più pulito. Il database MSC offre un mondo di scene tranquille, per lo più naturali, in cui bellezza e bruttezza dipendono principalmente dall’aspetto visivo, non da chi o cosa rappresentano. Questo lo rende un banco di prova potente per la psicologia, le neuroscienze e la ricerca in intelligenza artificiale che mira a prevedere le preferenze estetiche a partire soltanto dalla struttura delle immagini. Successivamente, significati più complessi e contesti culturali potranno essere reintrodotti. Partendo da immagini che dicono molto poco e che appaiono molto diverse, il progetto MSC aiuta a chiarire quanto del nostro senso della bellezza nasca dall’occhio prima che la mente aggiunga le sue storie.
Citazione: Penacchio, O., Javed, A., Raducanu, B. et al. The Minimum Semantic Content (MSC) Dataset: A Large, Balanced Resource for Computational Aesthetics Research. Sci Data 13, 470 (2026). https://doi.org/10.1038/s41597-026-06816-0
Parole chiave: estetica visiva, database di immagini, valutazioni crowdsourced, bellezza computazionale, texture naturali