Clear Sky Science · nl
De Minimum Semantische Inhoud (MSC)-dataset: Een grote, evenwichtige bron voor onderzoek naar computationele esthetiek
Waarom schoonheid in beelden moeilijker te meten is dan het lijkt
Waarom vinden we sommige foto’s mooi terwijl andere saai of zelfs lelijk overkomen? Je zou denken dat wetenschappers dat kunnen verklaren door kleuren, contrast of patronen in een afbeelding te meten. Er is echter een probleem: onze reacties zijn verstrengeld met wat de afbeelding toont—mensen, plaatsen, symbolen en herinneringen. Dit artikel introduceert een nieuwe, zorgvuldig samengestelde beeldverzameling die probeert die afleidingen weg te nemen, zodat onderzoekers zich kunnen richten op hoe het oog en de hersenen reageren op het ruwe uiterlijk van een afbeelding zelf.
Het verhaal uit de afbeelding halen
De meeste populaire beelddatabanken die in onderzoek worden gebruikt, zijn samengesteld uit online fotodelingsites en wedstrijden. Deze bronnen brengen titels, thema’s en culturele verwijzingen met zich mee die subtiel sturen hoe mensen ze beoordelen. Een slimme grap die bij een wedstrijdthema past kan een middelmatig uitziende foto laten winnen. Sterke symbolen, zoals vlaggen, kunnen hoog scoren om culturele redenen in plaats van visuele. Bovendien uploaden mensen zelden echt slechte foto’s, waardoor bestaande databases vol staan met afbeeldingen die redelijk tot goed zijn. Samen maakt dit het erg lastig om vast te stellen of een hoge beoordeling voortkomt uit de manier waarop een afbeelding is opgebouwd—haar kleuren, texturen en vormen—of uit wat deze betekent. 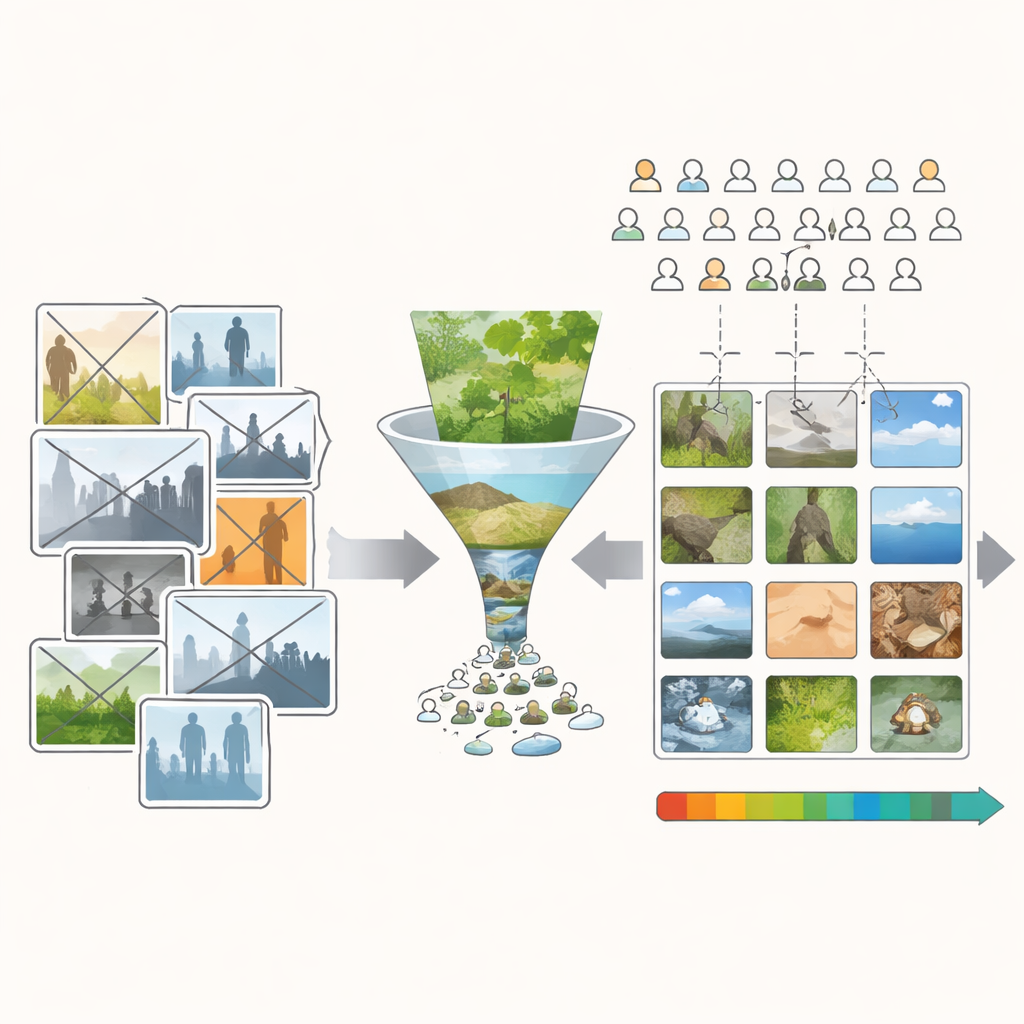
Een wereld van rustige scènes opbouwen
Om dit aan te pakken creëerden de auteurs de Minimum Semantische Inhoud (MSC)-database: meer dan tienduizend afbeeldingen die visueel rijk zijn maar zo weinig mogelijk “verhaal” bevatten. Ze begonnen met public-domain foto’s en persoonlijke collecties en verwijderden vervolgens alle afbeeldingen met mensen, dieren, gebouwen, tekst of sterke symbolische objecten. Ze vermeden ook ansichtkaartachtige uitzichten die waarschijnlijk sterke herinneringen of emoties oproepen. Wat overblijft zijn grotendeels fragmenten uit de natuur—bladeren, schors, stenen, wolken, wateroppervlakken en bosbodems. Deze scènes zijn niet volledig betekenisloos, maar ze zijn veel uniformer qua onderwerp. Daardoor is het meer waarschijnlijk dat verschillen in oordelen van mensen voortkomen uit visuele eigenschappen zoals kleur, licht en structuur in plaats van uit wie of wat is afgebeeld.
Een hulpmiddel uitvinden om schoonheid en lelijkheid op aanvraag te maken
Zelfs met deze zorgvuldige filtering neigde de beginnende verzameling nog steeds naar aangenaam uitziende afbeeldingen. Om schoonheid wetenschappelijk goed te kunnen onderzoeken, hebben onderzoekers veel voorbeelden nodig die gelijkmatig verspreid zijn van zeer lelijk tot zeer mooi. Het team bouwde daarom een eenvoudig bewerkingsprogramma met de bijnaam de “Uglifier.” Veertig vrijwilligers gebruikten het om geselecteerde afbeeldingen in twee richtingen te duwen: maak ze zo mooi mogelijk, of zo lelijk mogelijk, door schuifregelaars aan te passen voor helderheid, contrast, kleurmengsel, scherpte, ruis, uitsnijden en een paar meer geavanceerde transformaties. De onderzoekers legden ook enkele van deze bewerkingsrecepten vast en pasten ze automatisch toe op andere afbeeldingen, waarmee een grote batch extra “lelijke” varianten werd toegevoegd. Dit resulteerde in een brede mix van originelen, verfraaide, vergruwelijkte en automatisch vergruwelijkte scènes.
Duizenden mensen met hun ogen laten stemmen
Vervolgens wendden de auteurs zich tot een crowdsourcingplatform ingebouwd in een online spel en werden meer dan tienduizend spelers wereldwijd geworven. Elke afbeelding in de MSC-set werd aan honderd verschillende niet-expert kijkers getoond, die de schoonheid beoordeelden op een eenvoudige vijfpuntschaal van zeer lelijk tot zeer mooi. Trainende voorbeelden aan de uitersten hielpen mensen de volledige schaal te gebruiken. Zorgvuldige kwaliteitscontroles verwijderden spelers die leek te klikken zonder patroon. Het eindresultaat is een afbeeldingsverzameling waarbij elke scène wordt ondersteund door een rijke beoordelingsgeschiedenis, en waarbij lelijke, gemiddelde en mooie afbeeldingen goed vertegenwoordigd zijn in plaats van geclusterd in het midden.
Wat dit onthult over schoonheid en visuele structuur
Met deze gebalanceerde dataset in handen onderzocht het team hoe tientallen basale afbeeldingskenmerken—zoals contrast, kleurvariabiliteit, randdichtheid, symmetrie en fractalachtige textuur—samenhangen met schoonheidsbeoordelingen. Ze ontdekten dat wanneer scores gelijkmatig over het lelijk–mooi bereik zijn verdeeld, verbanden tussen deze laag-niveau eigenschappen en de oordelen van mensen duidelijker en vaak sterker worden. In sommige gevallen draait de richting van de relatie zelfs om vergeleken met wat in oudere, bevooroordeelde databases werd gezien. Ze controleerden ook of de Uglifier een smalle, kunstmatige soort lelijkheid produceerde; in plaats daarvan bleken de bewerkte afbeeldingen vergelijkbare basisstatistieken te delen met oorspronkelijk laag beoordeelde afbeeldingen, wat suggereert dat de manipulaties echte visuele neigingen vastleggen in plaats van karikaturale extremen. 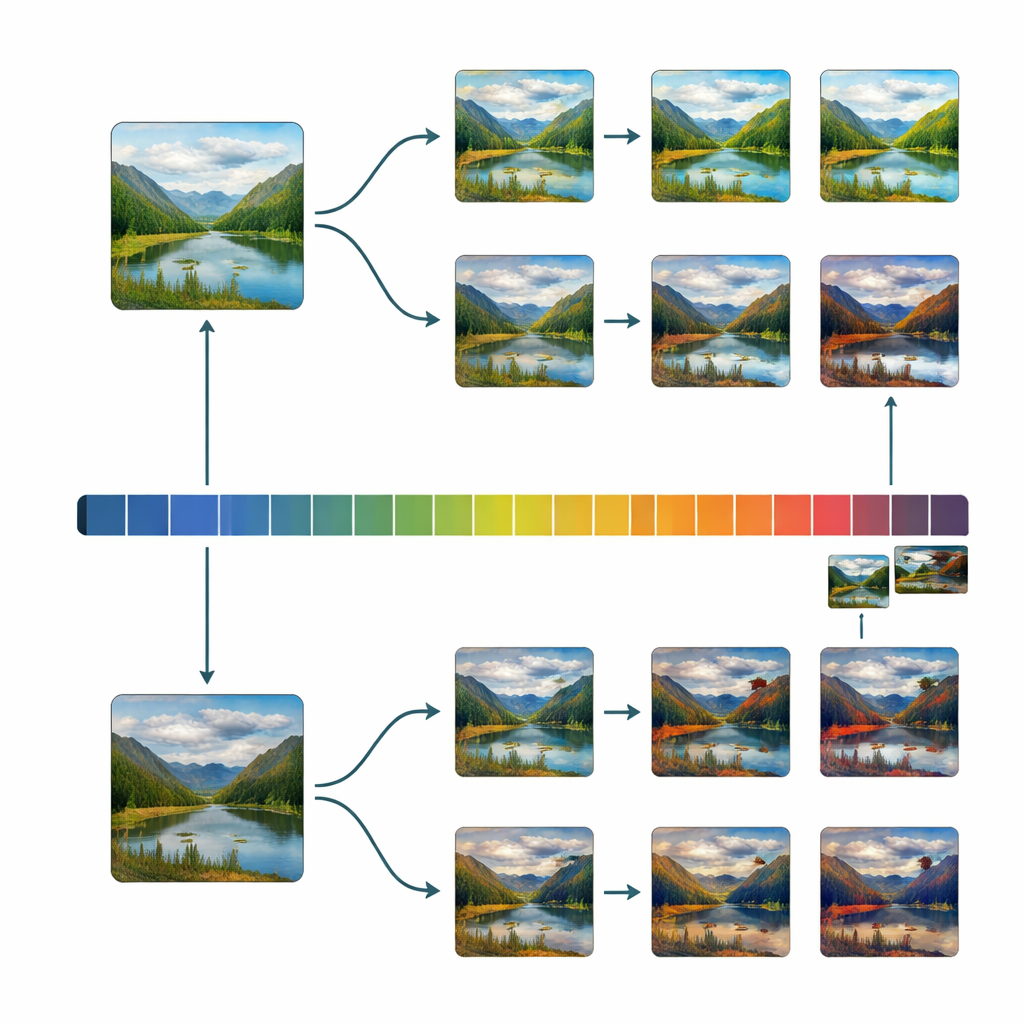
Waarom dit er toe doet voor het begrijpen van smaak
Voor de lezer is de kernboodschap dat wetenschappers nu visuele smaak op een schonere manier kunnen bestuderen. De MSC-database biedt een wereld van rustige, grotendeels natuurlijke scènes waarin schoonheid en lelijkheid voornamelijk afhangen van hoe iets eruitziet, niet van wie of wat het voorstelt. Dit maakt het een krachtig testveld voor psychologie, neurowetenschap en kunstmatige-intelligentieonderzoek dat esthetische voorkeuren wil voorspellen op basis van de structuur van beelden alleen. Later kunnen complexere betekenissen en culturele context weer worden toegevoegd. Door te beginnen met beelden die weinig zeggen en er toch heel verschillend uitzien, helpt het MSC-project te verduidelijken hoeveel van ons gevoel voor schoonheid voortkomt uit het oog voordat de geest zijn verhalen toevoegt.
Bronvermelding: Penacchio, O., Javed, A., Raducanu, B. et al. The Minimum Semantic Content (MSC) Dataset: A Large, Balanced Resource for Computational Aesthetics Research. Sci Data 13, 470 (2026). https://doi.org/10.1038/s41597-026-06816-0
Trefwoorden: visuele esthetiek, beeldendatabank, crowdsourced beoordelingen, computationele schoonheid, natuurlijke texturen