Clear Sky Science · sv
Tolkningsbara maskininlärningsmodeller för att förutsäga stroke hos patienter med nyupptäckt förmaksflimmer
Varför det är viktigt att förutsäga strokesrisk
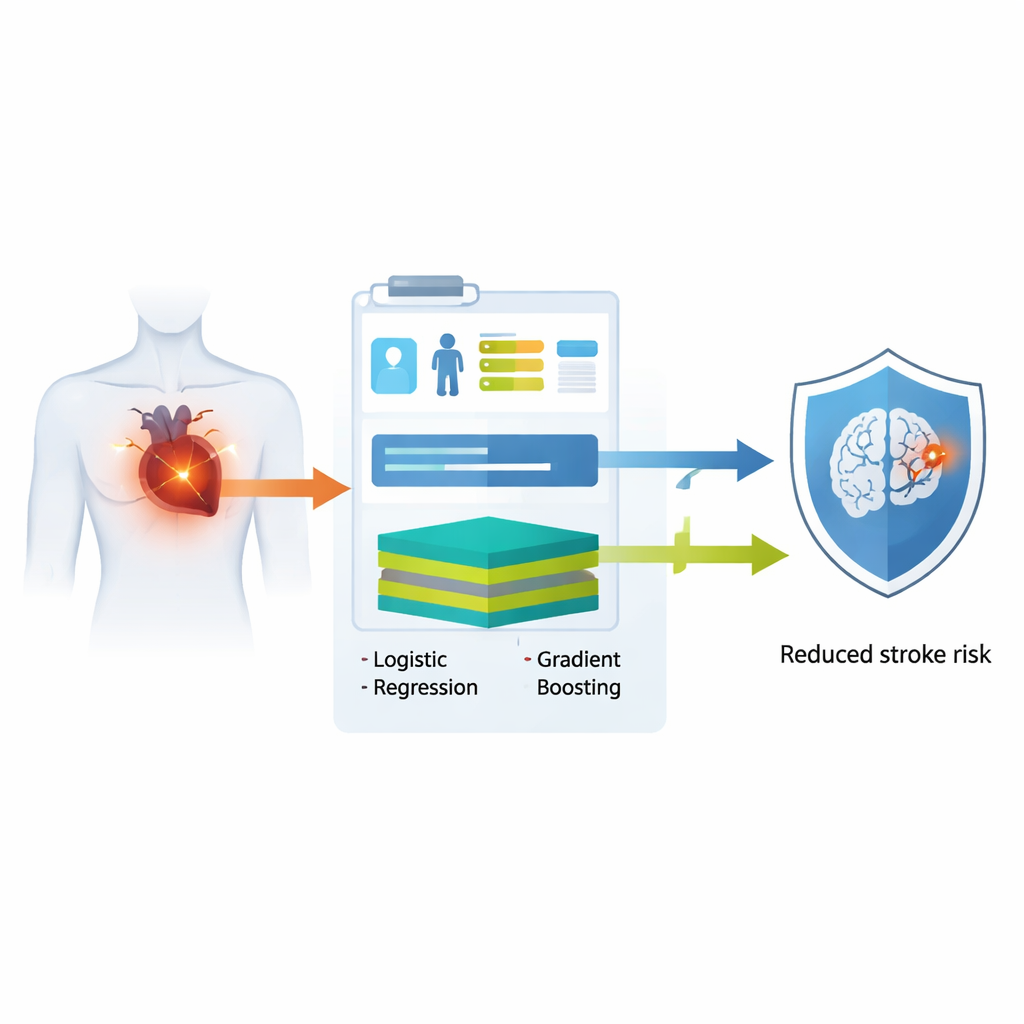
Förmaksflimmer, ett vanligt hjärtrytmproblem, ökar kraftigt risken för att drabbas av stroke. Läkare förlitar sig idag på en enkel poängbaserad skala för att avgöra vem som ska få blodförtunnande läkemedel, men den här skalan missar ofta patienter med hög risk och kan samtidigt klassificera en del med lägre risk som i behov av behandling. Denna studie undersöker om smartare, men fortfarande begripliga, datorbaserade modeller kan göra ett bättre jobb med att uppskatta kortsiktig strokesrisk med endast den information som alla mottagningar redan har: ålder, befintliga sjukdomar och vanliga mediciner.
Ett vanligt hjärtproblem med allvarliga konsekvenser
Förmaksflimmer drabbar tiotals miljoner människor världen över och är en av de ledande orsakerna till funktionsnedsättande och dödliga stroke. Även med moderna blodförtunnande medel kvarstår risk för många patienter, särskilt under det första året efter diagnos av rytmrubbningen. Det mest använda verktyget idag, CHA₂DS₂‑VASc-poängen, tilldelar poäng för faktorer som ålder, högt blodtryck och tidigare stroke. Trots att det är enkelt kan det inte fånga mer subtila mönster i en persons sjukdomshistoria och presterar ofta bara måttligt väl när det gäller att förutsäga vem som kommer att drabbas av stroke över tid.
Att bygga smartare men ändå lättanvända riskverktyg
Forskarna använde elektroniska journaler från mer än 9 500 vuxna vid ett stort taiwanesiskt sjukhus som nyss fått diagnosen förmaksflimmer. De testade sedan sina modeller i två separata sjukhusgrenar med över 2 500 ytterligare patienter. I stället för att förlita sig på komplexa laboratorietester eller bilddiagnostik begränsade de medvetet indata till ålder, kroniska sjukdomar såsom diabetes och högt blodtryck samt nylig användning av vanliga läkemedel som blodförtunnande medel, rytmmediciner och diabetesläkemedel. Med denna grundläggande information byggde de två typer av datoriserade modeller: en traditionell logistisk regressionsmodell, som fungerar som en transparent viktad checklista, och en mer flexibel modell med extreme gradient boosting, som kan fånga invecklade, icke-linjära samband. Båda modellerna var utformade för att ge en personlig sannolikhet för att drabbas av stroke inom ett år efter diagnos.
Att testa noggrannhet, rättvisa och verklig nytta
När de nya modellerna jämfördes med standardpoängen var de mycket bättre på att sortera patienter i dem som skulle och inte skulle drabbas av stroke. I både den ursprungliga och den externa sjukhusgruppen skilde maskininlärningsmodellerna korrekt mellan hög- och lågriskpatienter i cirka 90 procent av fallen, medan standardpoängens noggrannhet låg närmare två tredjedelar. De nya verktygen gav också riskuppskattningar som stämde närmare överens med observerade strokerater, en viktig egenskap för pålitligt beslutsfattande. Viktigt är att när forskarna undersökte prestanda separat för kvinnor och män hittade de inga meningsfulla skillnader, vilket tyder på att modellerna inte orättvist gynnade ena könet framför det andra, till skillnad från den äldre poängen som automatiskt lägger till en poäng för att vara kvinna.
Från förutsägelser till bättre behandlingsbeslut
För att se om dessa förbättrade förutsägelser kunde förändra vården använde teamet beslutskurveanalys, en metod som väger nyttan av att förebygga stroke mot skadorna av onödig behandling. Över ett brett spektrum av behandlingströsklar gav båda modellerna avsevärt större nytta än standardpoängen, och identifierade över 100 ytterligare verkligt högriskpatienter per 1 000 utan att öka onödig användning av antikoagulantia. Under tre till fem års uppföljning gavs patienter som klassificerats som högrisk av de nya modellerna tydlig nytta av att ta moderna blodförtunnande medel: deras strokerater var lägre jämfört med liknande högriskpatienter som inte fick dessa läkemedel, medan de som klassificerades som lågrisk inte visade en tydlig fördel. I kontrast visade grupper definierade som hög- eller lågrisk av den äldre poängen ibland förvirrande eller till och med omvända mönster, vilket antyder felklassificering. Forskarna använde också visuella förklaringsmetoder för att visa hur specifika faktorer, såsom tidigare stroke, ålder eller användning av vissa rytmmediciner, pressade en individs riskuppskattning uppåt eller nedåt, vilket hjälpte till att göra modellernas resonemang mer transparent för kliniker.
Vad detta betyder för patienter och läkare
Denna studie visar att det är möjligt att bygga noggranna, begripliga verktyg för att uppskatta strokesrisk med enbart information som redan finns vid tiden för diagnos av förmaksflimmer. Genom att bättre identifiera vilka som verkligen löper hög kortsiktig strokesrisk kan dessa modeller hjälpa läkare att tryggare ordinera blodförtunnande till dem som mest behöver det, samtidigt som onödig behandling undviks hos personer med lägre risk. Även om ytterligare testning i andra länder och vårdsystem krävs, pekar detta arbete mot en framtid där vardagliga kliniska beslut styrs av intuitiva, datadrivna verktyg som anpassar strokeförebyggande till varje enskild patient.
Citering: Lin, J.CW., Chang, CM., Pan, HY. et al. Interpretable machine learning models for stroke risk prediction in patients with newly diagnosed atrial fibrillation. npj Digit. Med. 9, 289 (2026). https://doi.org/10.1038/s41746-026-02470-3
Nyckelord: förmaksflimmer, strokeprediktion, maskininlärning, riskstratifiering, antikoagulantiabehandling