Clear Sky Science · ru
Интерпретируемые модели машинного обучения для прогнозирования риска инсульта у пациентов с недавно выявленной фибрилляцией предсердий
Почему важно прогнозирование риска инсульта
Фибрилляция предсердий — распространённое нарушение сердечного ритма — значительно увеличивает вероятность инсульта. Врачи сейчас пользуются простым балльным методом, чтобы решить, кто должен получать антикоагулянты, но эта шкала часто пропускает пациентов с высоким риском и может ошибочно относить к лечению людей с более низким риском. В этом исследовании проверяют, могут ли более «умные», но по‑прежнему понятные компьютерные модели точнее оценивать краткосрочный риск инсульта, используя только ту информацию, которая уже имеется в любой клинике: возраст, сопутствующие заболевания и обычные лекарства.
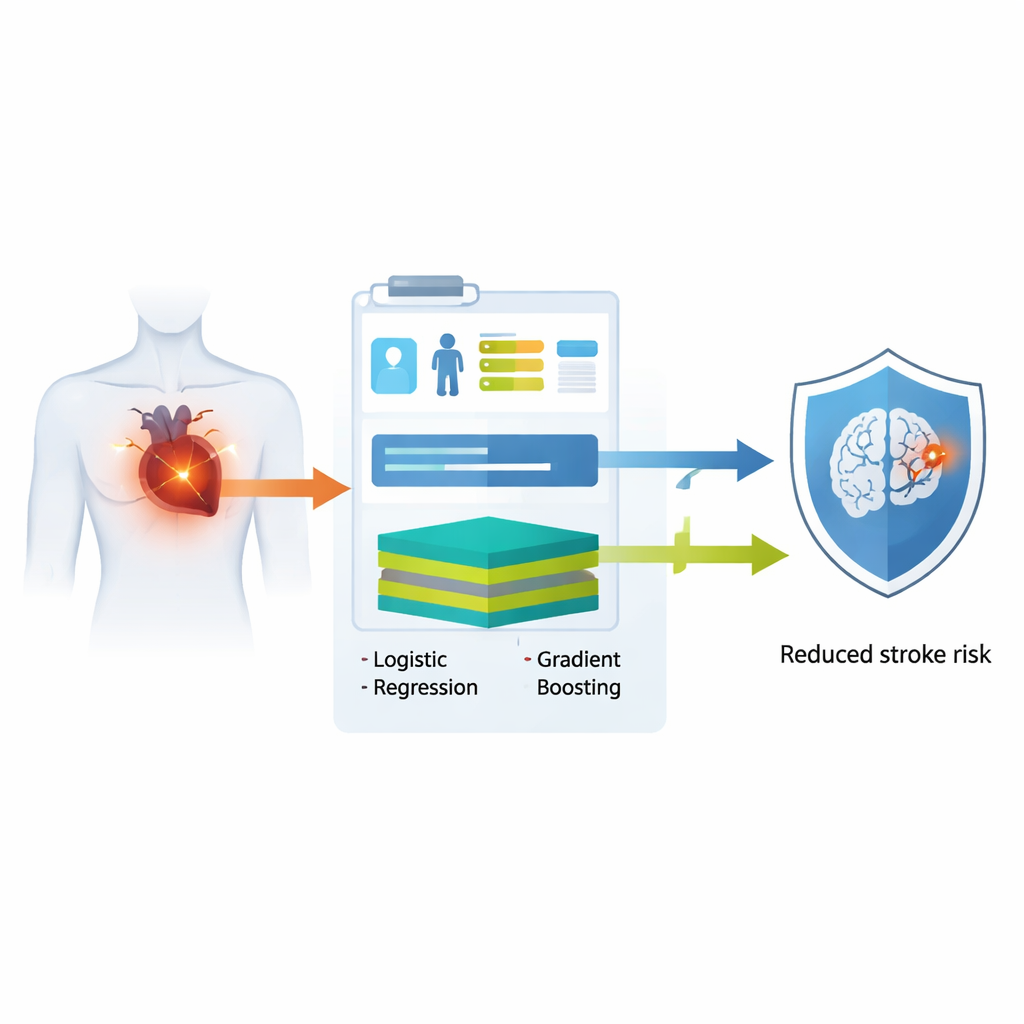
Распространённая проблема сердца с серьёзными последствиями
Фибрилляция предсердий поражает десятки миллионов людей во всём мире и является одной из ведущих причин инвалидизирующих и смертельных инсультов. Даже при современных антикоагулянтах многие пациенты остаются в группе риска, особенно в первый год после установления диагноза. Наиболее широко используемый инструмент сегодня, шкала CHA₂DS₂‑VASc, назначает баллы за такие факторы, как возраст, повышенное артериальное давление и перенесённый инсульт. Несмотря на простоту, она не в состоянии учесть более тонкие закономерности в анамнезе пациента и часто показывает лишь умеренную точность при прогнозировании, кто перенесёт инсульт со временем.
Создание более умных, но простых в использовании инструментов оценки риска
Исследователи использовали данные электронных медицинских карт более чем 9 500 взрослых из крупной тайваньской больницы с недавно выявленной фибрилляцией предсердий. Затем они протестировали свои модели в двух отдельных филиалах больницы на более чем 2 500 дополнительных пациентах. Вместо опоры на сложные лабораторные тесты или визуализацию они намеренно ограничили входные данные возрастом, хроническими заболеваниями, такими как диабет и гипертензия, и недавним приёмом распространённых препаратов — антикоагулянтов, антиаритмиков и препаратов для лечения диабета. На основании этой базовой информации они построили два типа компьютерных моделей: традиционную логистическую регрессию, которая функционирует как прозрачный взвешенный чек‑лист, и более гибкую модель с экстремальным градиентным бустингом (XGBoost), способную улавливать сложные нелинейные связи. Обе модели были рассчитаны на выдачу персонализированной вероятности инсульта в течение года после постановки диагноза.
Тестирование точности, справедливости и практической полезности
При сравнении новых моделей со стандартной шкалой они оказались значительно лучше в разделении пациентов на тех, кто перенесёт инсульт, и тех, кто не перенесёт. В исходной и внешней группах больниц модели машинного обучения правильно различали пациентов с высоким и низким риском примерно в 90% случаев, тогда как точность стандартной шкалы была ближе к двум третям. Новые инструменты также давали оценки риска, которые гораздо ближе соответствовали наблюдаемым уровням инсульта — важное свойство для надёжного принятия решений. Существенно, что при раздельной оценке у женщин и мужчин исследователи не выявили значимых различий в производительности, что указывает на отсутствие предвзятости в пользу одного пола в новых моделях, в отличие от старой шкалы, которая автоматически добавляет очко за женский пол.
От прогнозов к лучшим решениям о лечении
Чтобы выяснить, могут ли улучшенные прогнозы изменить практику, команда применила анализ кривых решений — метод, который сопоставляет пользу предотвращения инсультов с вредом от ненужного лечения. В широком диапазоне порогов для лечения обе модели принесли заметно большую пользу по сравнению со стандартной шкалой, выявив свыше 100 дополнительных действительно высокорисковых пациентов на каждые 1 000 человек без увеличения ненужного назначения антикоагулянтов. При наблюдении в течение трёх-пяти лет пациенты, отнесённые новыми моделями к группе высокого риска, однозначно выигрывали от приёма современных антикоагулянтов: у них отмечались более низкие показатели инсульта по сравнению с сопоставимыми высокорисковыми пациентами, не получавшими эти препараты, тогда как у классифицированных как низкорисковые явной пользы не наблюдалось. В отличие от этого, группы, определённые старой шкалой как высоко- или низкорисковые, порой показывали запутанные или даже обратные закономерности, что указывает на возможную ошибочную классификацию. Исследователи также применили визуальные методы объяснения, чтобы продемонстрировать, как отдельные факторы — такие как предшествующий инсульт, возраст или применение определённых антиаритмиков — повышали или понижали оценку риска конкретного человека, делая рассуждения моделей более прозрачными для клиницистов.
Что это значит для пациентов и врачей
Исследование показывает, что возможно создать точные и понятные инструменты оценки риска инсульта, используя лишь ту информацию, которая уже доступна в момент постановки диагноза фибрилляции предсердий. Лучше идентифицируя тех, кто действительно находится в группе высокого краткосрочного риска, эти модели могут помочь врачам увереннее назначать антикоагулянты тем, кто в них наиболее нуждается, и избегать ненужного лечения у людей с более низким риском. Хотя необходимы дополнительные проверки в других странах и системах здравоохранения, эта работа указывает на будущее, в котором повседневные клинические решения будут опираться на интуитивные, основанные на данных инструменты, адаптирующие профилактику инсульта к каждому отдельному пациенту.
Цитирование: Lin, J.CW., Chang, CM., Pan, HY. et al. Interpretable machine learning models for stroke risk prediction in patients with newly diagnosed atrial fibrillation. npj Digit. Med. 9, 289 (2026). https://doi.org/10.1038/s41746-026-02470-3
Ключевые слова: фибрилляция предсердий, прогнозирование инсульта, машинное обучение, стратификация риска, антикоагулянтная терапия