Clear Sky Science · pl
Interpretowalne modele uczenia maszynowego do przewidywania ryzyka udaru u pacjentów ze świeżo rozpoznaną migotaniem przedsionków
Dlaczego przewidywanie ryzyka udaru ma znaczenie
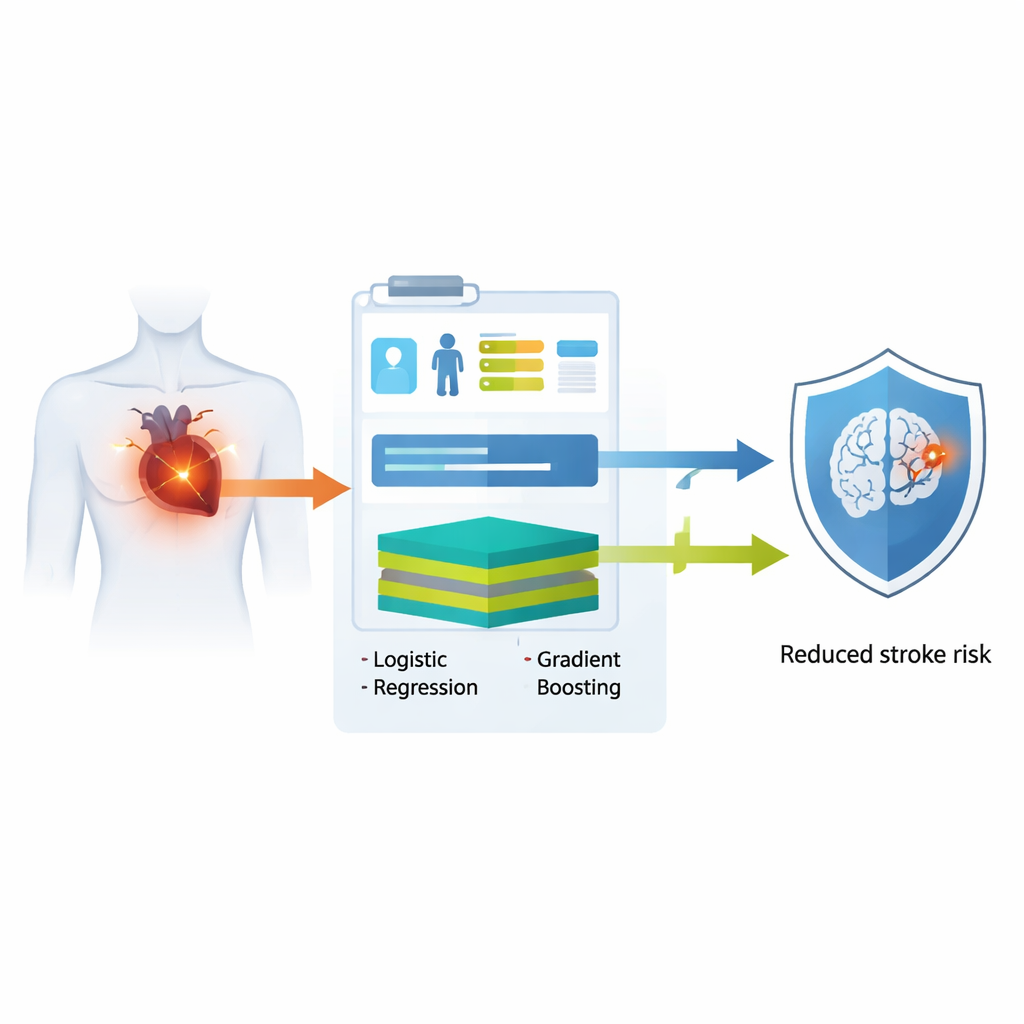
Migotanie przedsionków, powszechne zaburzenie rytmu serca, znacząco zwiększa prawdopodobieństwo wystąpienia udaru. Lekarze obecnie opierają decyzje o leczeniu przeciwkrzepliwym na prostym systemie punktowym, który jednak często nie rozpoznaje pacjentów z wysokim ryzykiem i może wskazać leczenie u osób o niższym ryzyku. W tym badaniu sprawdzono, czy inteligentniejsze, a zarazem zrozumiałe modele komputerowe mogą lepiej oszacować krótkoterminowe ryzyko udaru, wykorzystując wyłącznie dane dostępne w każdej przychodni: wiek, istniejące choroby i stosowane powszechne leki.
Powszechny problem sercowy o poważnych konsekwencjach
Migotanie przedsionków dotyka dziesiątki milionów ludzi na świecie i jest jedną z głównych przyczyn odległonowych i śmiertelnych udarów. Nawet przy nowoczesnych lekach przeciwzakrzepowych wielu pacjentów nadal pozostaje zagrożonych, zwłaszcza w pierwszym roku po rozpoznaniu zaburzenia rytmu. Najczęściej stosowane narzędzie, punktacja CHA₂DS₂‑VASc, przyznaje punkty za takie czynniki jak wiek, nadciśnienie tętnicze czy wcześniejszy udar. Choć proste, nie jest w stanie uchwycić subtelniejszych wzorców w historii medycznej pacjenta i często wykazuje jedynie umiarkowaną skuteczność w przewidywaniu, kto w przyszłości dozna udaru.
Tworzenie mądrzejszych, a jednocześnie prostych w użyciu narzędzi ryzyka
Naukowcy wykorzystali elektroniczne dokumentacje medyczne ponad 9 500 dorosłych z dużego szpitala na Tajwanie, u których niedawno rozpoznano migotanie przedsionków. Następnie przetestowali swoje modele w dwóch oddzielnych oddziałach szpitala na ponad 2 500 dodatkowych pacjentów. Zamiast polegać na złożonych badaniach laboratoryjnych czy obrazowaniu, celowo ograniczyli dane wejściowe do wieku, chorób przewlekłych, takich jak cukrzyca i nadciśnienie, oraz niedawnego stosowania powszechnych leków, takich jak środki przeciwzakrzepowe, leki przeciwarytmiczne i leki przeciwcukrzycowe. Na podstawie tych podstawowych informacji zbudowali dwa typy modeli komputerowych: tradycyjny model regresji logistycznej, działający jak przejrzysta ważona lista kontrolna, oraz bardziej elastyczny model extreme gradient boosting, zdolny uchwycić złożone, nieliniowe zależności. Oba modele miały za zadanie zwracać spersonalizowane prawdopodobieństwo wystąpienia udaru w ciągu roku od rozpoznania.
Testowanie dokładności, rzetelności i użyteczności w praktyce
W porównaniu z dotychczasową punktacją nowe modele znacznie lepiej rozdzielały pacjentów na tych, którzy doświadczą udaru, i tych, którzy mu nie ulegną. Zarówno w grupie pierwotnej, jak i w grupach zewnętrznych, modele uczenia maszynowego poprawnie rozróżniały pacjentów wysokiego i niskiego ryzyka w około 90% przypadków, podczas gdy dokładność standardowej punktacji była bliższa dwóch trzecich. Nowe narzędzia również generowały oszacowania ryzyka znacznie lepiej dopasowane do obserwowanych częstości udarów, co jest istotne dla zaufanego podejmowania decyzji. Co ważne, przy analizie wyników osobno u kobiet i mężczyzn badacze nie stwierdzili istotnych różnic, co sugeruje, że modele nie faworyzują jednej płci — w przeciwieństwie do starszej punktacji, która automatycznie dodaje punkt za bycie kobietą.
Od przewidywań do lepszych decyzji terapeutycznych
Aby sprawdzić, czy lepsze przewidywania mogą wpłynąć na opiekę, zespół użył analizy krzywej decyzyjnej, metody ważącej korzyści z zapobiegania udarom wobec szkód wynikających z niepotrzebnego leczenia. W szerokim zakresie progów decyzyjnych oba modele przyniosły znacznie większe korzyści niż standardowa punktacja, identyfikując ponad 100 dodatkowych rzeczywiście wysokiego ryzyka pacjentów na 1 000 bez zwiększania niepotrzebnego stosowania leków przeciwzakrzepowych. W ciągu trzech do pięciu lat obserwacji pacjenci sklasyfikowani jako wysokiego ryzyka przez nowe modele wyraźnie odnosili korzyść z przyjmowania nowoczesnych leków przeciwzakrzepowych: ich częstość udarów była niższa w porównaniu z podobnymi pacjentami wysokiego ryzyka, którzy tych leków nie otrzymali, podczas gdy osoby uznane za niskiego ryzyka nie wykazywały wyraźnej korzyści. Dla kontrastu, grupy zdefiniowane jako wysokie lub niskie ryzyko przez starszą punktację czasami pokazywały mylące, a nawet odwrócone wzorce, co sugeruje błędy klasyfikacji. Badacze użyli też wizualnych technik wyjaśniających, aby pokazać, jak konkretne czynniki, takie jak wcześniejszy udar, wiek czy stosowanie określonych leków przeciwarytmicznych, podnosiły lub obniżały indywidualne oszacowanie ryzyka, co pomaga uczynić rozumowanie modeli bardziej przejrzystym dla klinicystów.
Co to oznacza dla pacjentów i lekarzy
To badanie pokazuje, że możliwe jest zbudowanie dokładnych, zrozumiałych narzędzi do oceny ryzyka udaru, wykorzystujących wyłącznie informacje dostępne w chwili rozpoznania migotania przedsionków. Lepsze rozpoznawanie, kto naprawdę stoi w obliczu wysokiego krótkoterminowego ryzyka udaru, może pomóc lekarzom pewniej przepisywać leki przeciwzakrzepowe tym, którzy najbardziej ich potrzebują, a jednocześnie unikać niepotrzebnego leczenia u osób o niższym ryzyku. Choć potrzebne są dalsze testy w innych krajach i systemach opieki zdrowotnej, praca ta wskazuje drogę ku przyszłości, w której codzienne decyzje kliniczne wspierane są przez intuicyjne, oparte na danych narzędzia dopasowujące profil zapobiegania udarom do każdego pacjenta indywidualnie.
Cytowanie: Lin, J.CW., Chang, CM., Pan, HY. et al. Interpretable machine learning models for stroke risk prediction in patients with newly diagnosed atrial fibrillation. npj Digit. Med. 9, 289 (2026). https://doi.org/10.1038/s41746-026-02470-3
Słowa kluczowe: migotanie przedsionków, predykcja udaru, uczenie maszynowe, stratyfikacja ryzyka, terapia przeciwzakrzepowa