Clear Sky Science · nl
Interpeteerbare machine-learningmodellen voor het voorspellen van beroertrisico bij patiënten met pas gediagnosticeerde boezemfibrillatie
Waarom het voorspellen van beroertrisico belangrijk is
Boezemfibrillatie, een veelvoorkomend ritmestoornis van het hart, vergroot de kans op een beroerte aanzienlijk. Artsen vertrouwen momenteel op een eenvoudige puntenscore om te beslissen wie bloedverdunners moet krijgen, maar deze score mist vaak patiënten met een hoog risico en kan sommige mensen met een lager risico ten onrechte als behandelingsbehoevend bestempelen. Deze studie onderzoekt of slimmere, maar nog steeds begrijpelijke computermodellen beter in staat zijn het kortetermijnrisico op een beroerte te schatten met alleen informatie die elke kliniek al heeft: leeftijd, bestaande aandoeningen en gebruikelijke medicatie.
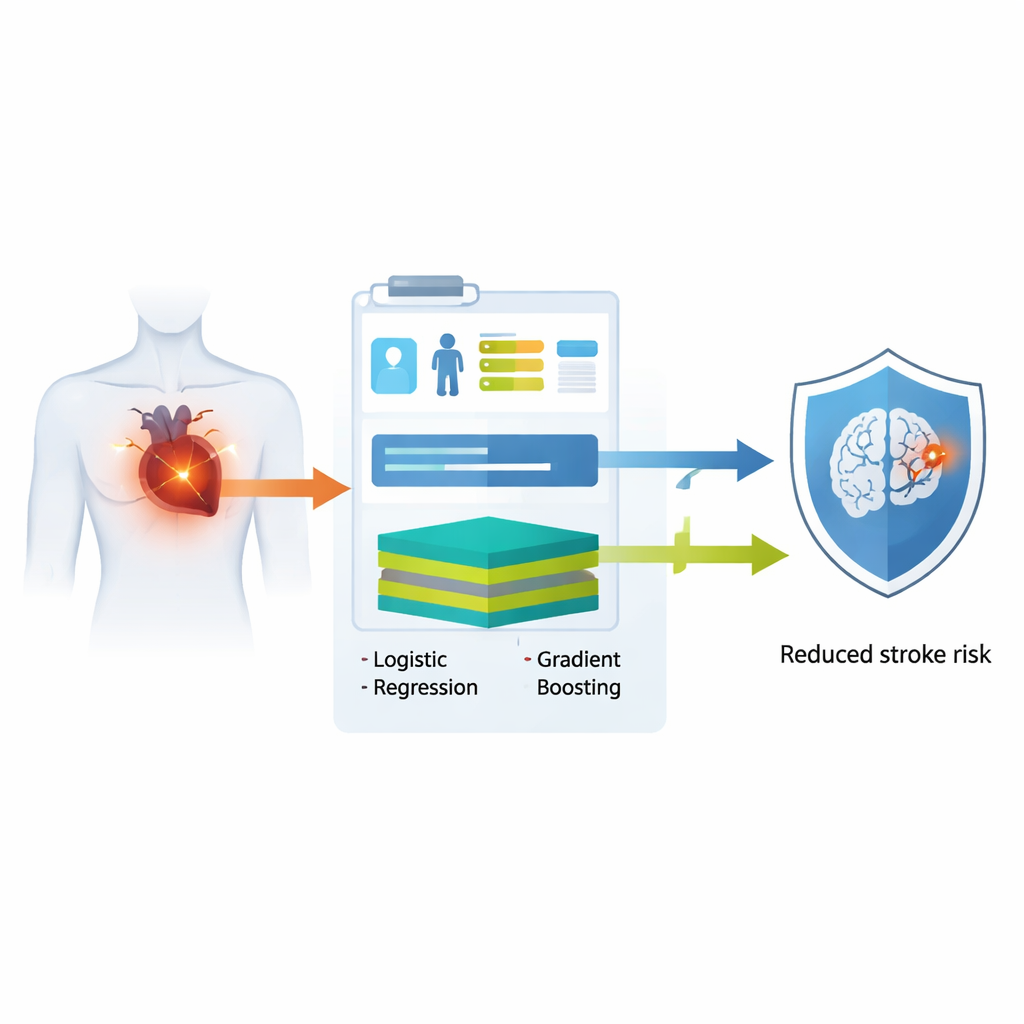
Een veelvoorkomend hartprobleem met ernstige gevolgen
Boezemfibrillatie treft wereldwijd tientallen miljoenen mensen en is een belangrijke oorzaak van invaliderende en dodelijke beroertes. Zelfs met moderne bloedverdunners blijven veel patiënten risico lopen, vooral in het eerste jaar na de diagnose van de ritmestoornis. Het meest gebruikte hulpmiddel vandaag, de CHA₂DS₂‑VASc-score, kent punten toe voor factoren zoals leeftijd, hoge bloeddruk en eerder doorgemaakte beroerte. Hoewel eenvoudig, kan deze score subtielere patronen in iemands medische voorgeschiedenis niet vastleggen en presteert hij vaak slechts matig in het voorspellen wie in de loop van de tijd een beroerte zal krijgen.
Slimmere maar eenvoudig te gebruiken risicotools ontwikkelen
De onderzoekers gebruikten elektronische medische dossiers van meer dan 9.500 volwassenen in een groot Taiwanees ziekenhuis die net gediagnosticeerd waren met boezemfibrillatie. Ze testten hun modellen vervolgens in twee afzonderlijke ziekenhuisvestigingen met meer dan 2.500 extra patiënten. In plaats van te vertrouwen op complexe laboratoriumtests of beeldvorming, beperkten zij de invoer opzettelijk tot leeftijd, chronische aandoeningen zoals diabetes en hoge bloeddruk, en recent gebruik van veel gebruikte geneesmiddelen zoals bloedverdunners, medicijnen voor het hartritme en diabetesmedicatie. Met deze basisinformatie bouwden ze twee typen computermodellen: een traditionele logistieke regressie, die werkt als een transparante gewogen checklist, en een flexibeler extreme gradient boosting-model, dat ingewikkelde niet-lineaire verbanden kan vastleggen. Beide modellen waren ontworpen om een gepersonaliseerde kans te geven op het krijgen van een beroerte binnen een jaar na diagnose.
Het testen van nauwkeurigheid, rechtvaardigheid en bruikbaarheid in de praktijk
Toen de nieuwe modellen werden vergeleken met de standaardscore, bleken ze veel beter in het onderscheiden van patiënten die wel en niet een beroerte zouden krijgen. Zowel in de oorspronkelijke als de externe ziekenhuisgroepen onderscheidden de machine-learningmodellen hoog- en laagrisicopatiënten correct in ongeveer 90% van de gevallen, terwijl de nauwkeurigheid van de standaardscore dichter bij tweederde lag. De nieuwe hulpmiddelen gaven ook risicoschattingen die veel beter overeenkwamen met de waargenomen beroertecijfers, een belangrijke eigenschap voor betrouwbare besluitvorming. Belangrijk is dat toen de onderzoekers de prestaties apart voor vrouwen en mannen bekeken, ze geen betekenisvolle verschillen vonden, wat suggereert dat de modellen niet onterecht één geslacht bevoordeelden, in tegenstelling tot de oudere score die automatisch een punt toevoegt voor vrouw zijn.
Van voorspellingen naar betere behandelkeuzes
Om te onderzoeken of deze verbeterde voorspellingen de zorg zouden kunnen veranderen, gebruikte het team decision curve analysis, een methode die de voordelen van het voorkomen van beroertes afzet tegen de nadelen van onnodige behandeling. Over een breed scala aan behandelingsdrempels boden beide modellen aanzienlijk meer voordeel dan de standaardscore, waarbij ze meer dan 100 extra werkelijk hoogrisicopatiënten per 1.000 identificeerden zonder het onnodige gebruik van antistolling te vergroten. Over drie tot vijf jaar follow-up profiteerden patiënten die door de nieuwe modellen als hoogrisico werden geclassificeerd duidelijk van het gebruik van moderne bloedverdunners: hun beroertecijfers waren lager vergeleken met vergelijkbare hoogrisicopatiënten die deze middelen niet kregen, terwijl degenen die als laagrisico werden aangemerkt geen duidelijk voordeel lieten zien. Daarentegen toonden groepen die door de oudere score als hoog- of laagrisico waren gedefinieerd soms verwarrende of zelfs omgekeerde patronen, wat wijst op mogelijke foutclassificatie. De onderzoekers gebruikten ook visuele verklaringsmethoden om te laten zien hoe specifieke factoren, zoals een eerdere beroerte, leeftijd of gebruik van bepaalde hartritmemedicatie, de risicoschatting van een individu omhoog of omlaag duwden, waardoor de redenering van de modellen voor clinici duidelijker werd.
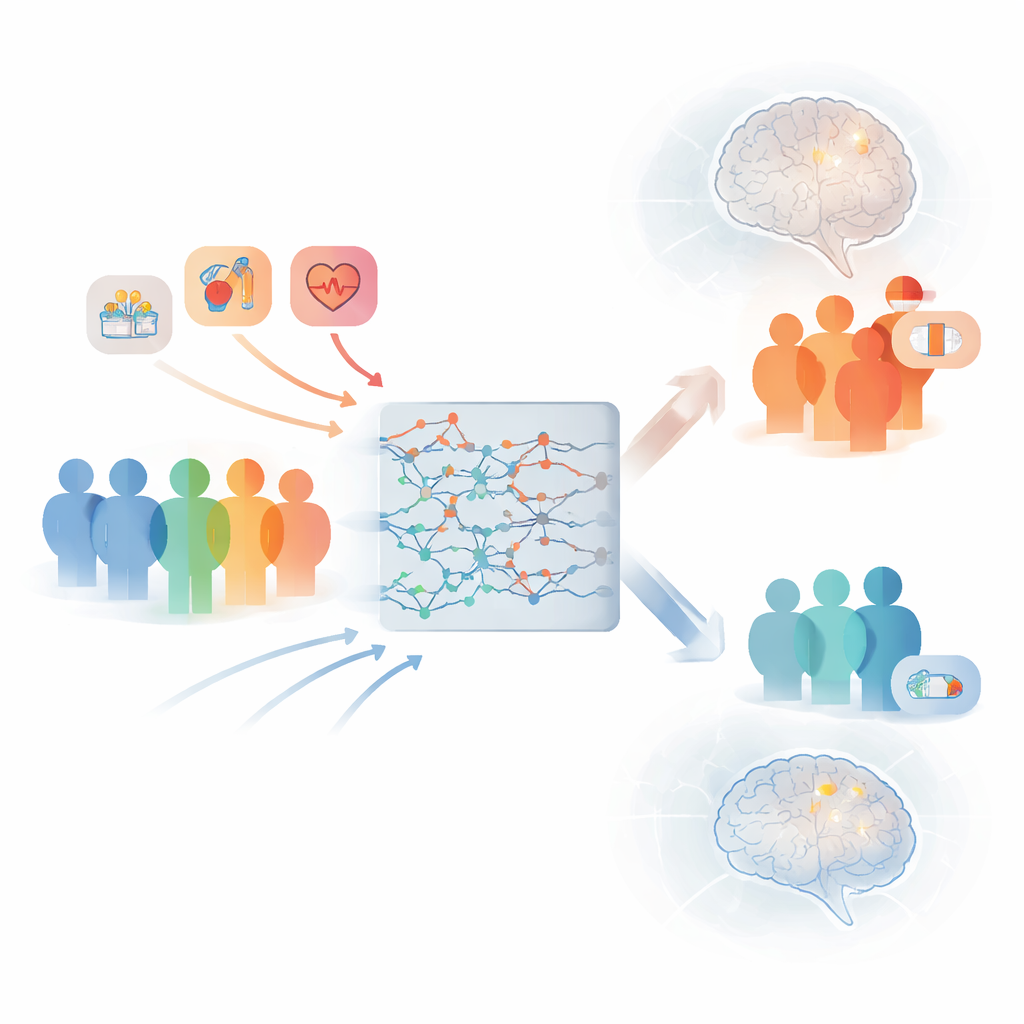
Wat dit betekent voor patiënten en artsen
Deze studie toont aan dat het mogelijk is nauwkeurige, begrijpelijke risicotools voor beroerte te bouwen met alleen informatie die al beschikbaar is op het moment dat boezemfibrillatie wordt gediagnosticeerd. Door beter te bepalen wie werkelijk een hoog kortetermijnrisico op een beroerte loopt, kunnen deze modellen artsen helpen bloedverdunners met meer vertrouwen voor te schrijven aan degenen die ze het meest nodig hebben, terwijl onnodige behandeling bij lager-risicopersonen wordt vermeden. Hoewel verder testen in andere landen en zorgsystemen nodig is, wijst dit werk op een toekomst waarin alledaagse klinische beslissingen worden gestuurd door intuïtieve, datagedreven hulpmiddelen die beroertepreventie op maat van de individuele patiënt maken.
Bronvermelding: Lin, J.CW., Chang, CM., Pan, HY. et al. Interpretable machine learning models for stroke risk prediction in patients with newly diagnosed atrial fibrillation. npj Digit. Med. 9, 289 (2026). https://doi.org/10.1038/s41746-026-02470-3
Trefwoorden: boezemfibrillatie, beroertevoorspelling, machine learning, risicostratificatie, antistollingstherapie