Clear Sky Science · sv
Påverkan av strategi för dataförstoring på modellens noggrannhet och generalisering vid klassificering av tunnslipade bergarter
Varför smartare bergbilder spelar roll
Djupt under markytan bestämmer hur bergarter är uppbyggda var vatten, olja, gas och till och med koldioxid kan flöda eller lagras. Geologer studerar ultratunna bergskivor i mikroskop för att avläsa denna dolda arkitektur. Datorer tränas i ökande grad att känna igen bergartstyper från sådana bilder. Den här artikeln ställer en förrädiskt enkel fråga med stora praktiska konsekvenser: när vi konstgjort förstorar dessa bildsamlingar genom ”dataaugmentation”, gör vi verkligen datorn klokare — eller kan vi ibland göra den sämre?
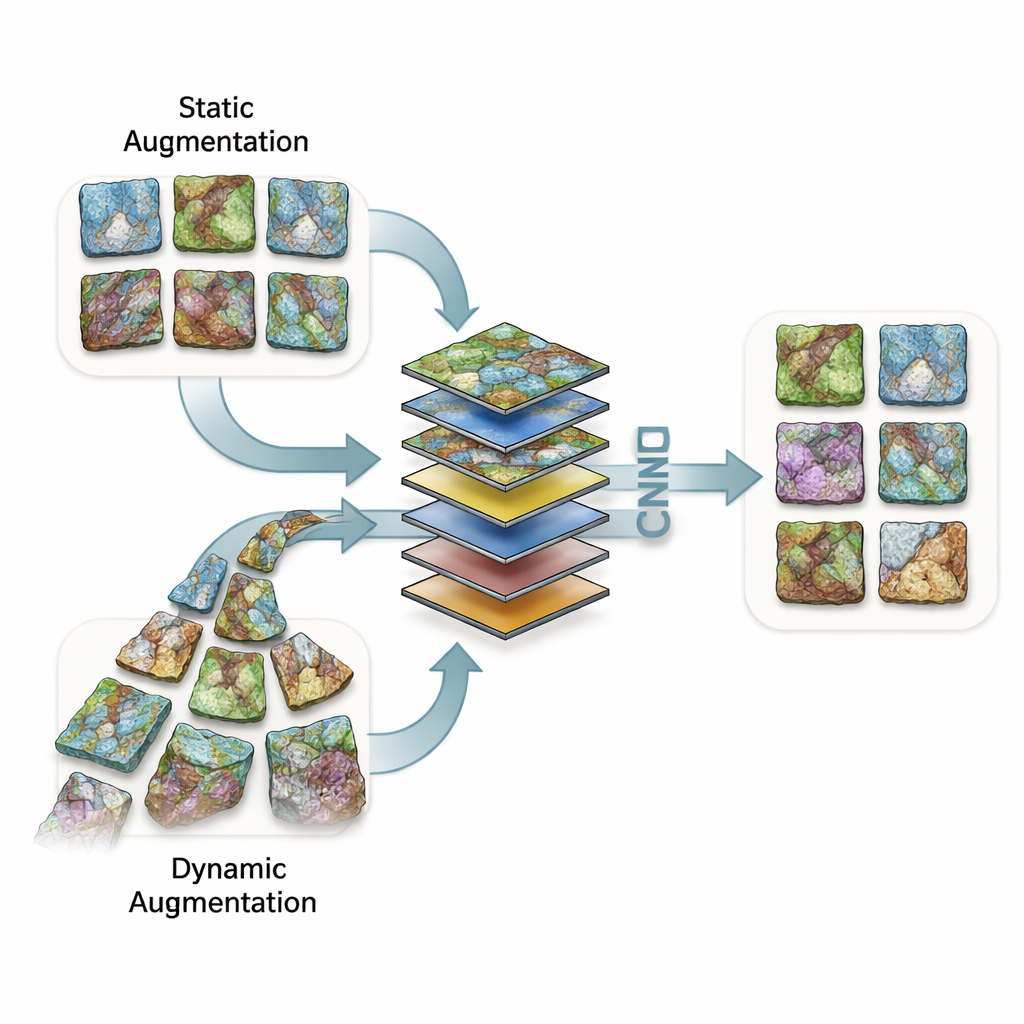
Att lära datorer med begränsade bergfoton
Att träna ett bildigenkänningssystem kräver vanligtvis tusentals exempel. Inom geologi är insamlingen av så många mikroskopbilder långsam och kostsam: prover måste borras, kapas, poleras och fotograferas, och många dataset hålls konfidentiella av företag. Författarna arbetade med en realistisk samling på 34 775 mikroskopbilder av tunnslipade bergskivor, indelade i 36 bergartskategorier såsom sandsten, kalksten och basalt. De definierade också en mindre ”begränsad data”-version med endast 100 träningsbilder och 50 valideringsbilder per klass för att efterlikna den vanliga situationen där data är knappa.
Att sträcka datamängden utan att förstöra bergarterna
För att kompensera för få bilder skapar forskare ofta modifierade kopior av originalen — spegling, förskjutning, rotation, zoom eller att blanda bilder — för att hjälpa en modell att lära sig att ignorera irrelevanta skillnader. Denna studie jämförde två breda sätt att göra detta på. Vid statisk augmentation skapas och sparas extra bilder före träning och datasetet förstoras permanent. Vid dynamisk augmentation genererar datorn slumpmässiga transformationer i farten under träningen, så varje genomgång kan se en något annorlunda version av samma prov. Teamet utforskade 133 detaljerade transformationsupplägg — allt från milda speglingar till extrema zoomar och rotationer, samt mer avancerad ”bildblandning” där två bergbilder matematiskt blandas eller fogas samman.
Att sätta fem nätverk på prov
Forskarna tränade fem olika konvolutionella neurala nätverk: tre välkända arkitekturer förtränade på vardagsfotografier, och två enklare modeller byggda från grunden. I 691 separata experiment mätte de hur ofta varje modell korrekt klassificerade valideringsbilder efter att ha använt olika augmentationsstrategier. Utan någon augmentation och med gott om data nådde det bästa förtränade nätverket redan cirka 98–99 % noggrannhet. Med det mindre träningssetet sjönk noggrannheten, vilket gjorde augmentation potentiellt värdefullt — men resultaten visade att inte all extra data är hjälpsam.
När mer variation skadar istället för hjälper
Den mest slående upptäckten är att augmentation är ett tveeggat svärd. Många vanligt använda geometriska knep, särskilt kraftiga zoomar och stora rotationer, minskade faktiskt noggrannheten, ibland dramatiskt, när de applicerades dynamiskt under träningen. Dessa operationer kan sträcka ut eller sudda ut de små mineralgrynen och texturerna som bär väsentlig geologisk information och i praktiken lära modellen att fästa uppmärksamhet vid mönster som inte finns i verkliga prover. Statisk augmentation, där de transformerade bilderna är fasta och konsekvent återanvänds, ledde i allmänhet till mer stabila och ibland bättre resultat. Enkla speglingar och små förskjutningar tenderade att vara säkra, men aggressiva transformationer var riskfyllda om de inte kontrollerades noggrant.
Att blanda bilder för bättre generalisering
De mest lovande metoderna var linjära och olinjära bildblandningstekniker som kombinerar två bergbilder för att skapa ett nytt träningsexempel. Varianter som genomsnittade, kaklade eller slog ihop bilder pixel för pixel bevarade eller förbättrade konsekvent noggrannheten, särskilt för det mindre datasetet. En modell tränad med sådana statiskt blandade bilder generaliserade bättre till tidigare osedda data, inklusive syntetiska bergbilder genererade av ett annat AI-system och riktiga berg som behandlats på ovanliga sätt, till exempel med bakgrunden borttagen eller med komplexa förvrängningar. Anmärkningsvärt nog överträffade denna augmenterade modell, tränad på betydligt färre ursprungliga bilder, ibland en mycket större modell tränad på hela, oaugmenterade datasetet.
Vad detta betyder för framtida geologisk AI
För icke‑specialister är huvudbudskapet att ”mer data” skapade av enkla bildknep inte automatiskt gör ett AI‑system mer tillförlitligt. I de känsliga texturerna hos mikroskopiska bergarter kan vissa förvrängningar radera precis de egenskaper geologer bryr sig om. Denna studie visar att noggrant utvald statisk augmentation och genomtänkt bildblandning delvis kan kompensera för begränsade data och förbättra hur väl modeller hanterar nya, okända bilder. Samtidigt kan okritisk användning av aggressiva, dynamiska transformationer tyst försämra noggrannheten. Med andra ord, för automatisk bergartsklassificering — och sannolikt för många vetenskapliga bilduppgifter — spelar sättet vi skapar nya träningsbilder lika stor roll som hur många vi har.
Citering: Habrat, M., Młynarczuk, M. Impact of data space augmentation strategy on model accuracy and generalization in thin-section rock classification. Sci Rep 16, 13927 (2026). https://doi.org/10.1038/s41598-026-44320-y
Nyckelord: bergmikroskopi, dataaugmentation, geologi AI, bildklassificering, tunnslip