Clear Sky Science · de
Auswirkungen von Strategien zur Vergrößerung des Datensatzraums auf Modellgenauigkeit und Generalisierung bei der Klassifikation von Dünnschliffen
Warum klügere Gesteinsbilder wichtig sind
Tief unter der Erde bestimmt die Zusammensetzung und Struktur von Gesteinen, wo Wasser, Öl, Gas und sogar Kohlendioxid fließen oder gespeichert werden können. Geologen untersuchen ultradünne Gesteinsschnitte unter dem Mikroskop, um diese verborgene Architektur zu lesen. Zunehmend werden Computer trainiert, Gesteinsarten anhand solcher Bilder zu erkennen. Dieses Papier stellt eine auf den ersten Blick einfache Frage mit großen praktischen Folgen: Wenn wir diese Bildsammlungen künstlich durch „Datenerweiterung“ vergrößern, machen wir den Computer wirklich klüger — oder können wir ihn manchmal verschlechtern?
Computern mit begrenzten Gesteinsfotos beibringen
Das Training eines Bilderkennungsystems erfordert normalerweise Tausende von Beispielen. In der Geologie ist das Sammeln so vieler mikroskopischer Gesteinsaufnahmen langsam und teuer: Proben müssen gebohrt, geschnitten, poliert und photographiert werden, und viele Datensätze werden von Unternehmen vertraulich gehalten. Die Autoren arbeiteten mit einer realistischen Sammlung von 34.775 Mikroskopbildern von Dünnschliffen, aufgeteilt in 36 Gesteinskategorien wie Sandstein, Kalkstein und Basalt. Sie definierten außerdem eine kleinere „begrenzte Daten“-Variante mit nur 100 Trainings- und 50 Validierungsbildern pro Klasse, um die übliche Situation mit knappen Daten zu simulieren.
Die Daten strecken, ohne die Gesteine zu zerstören
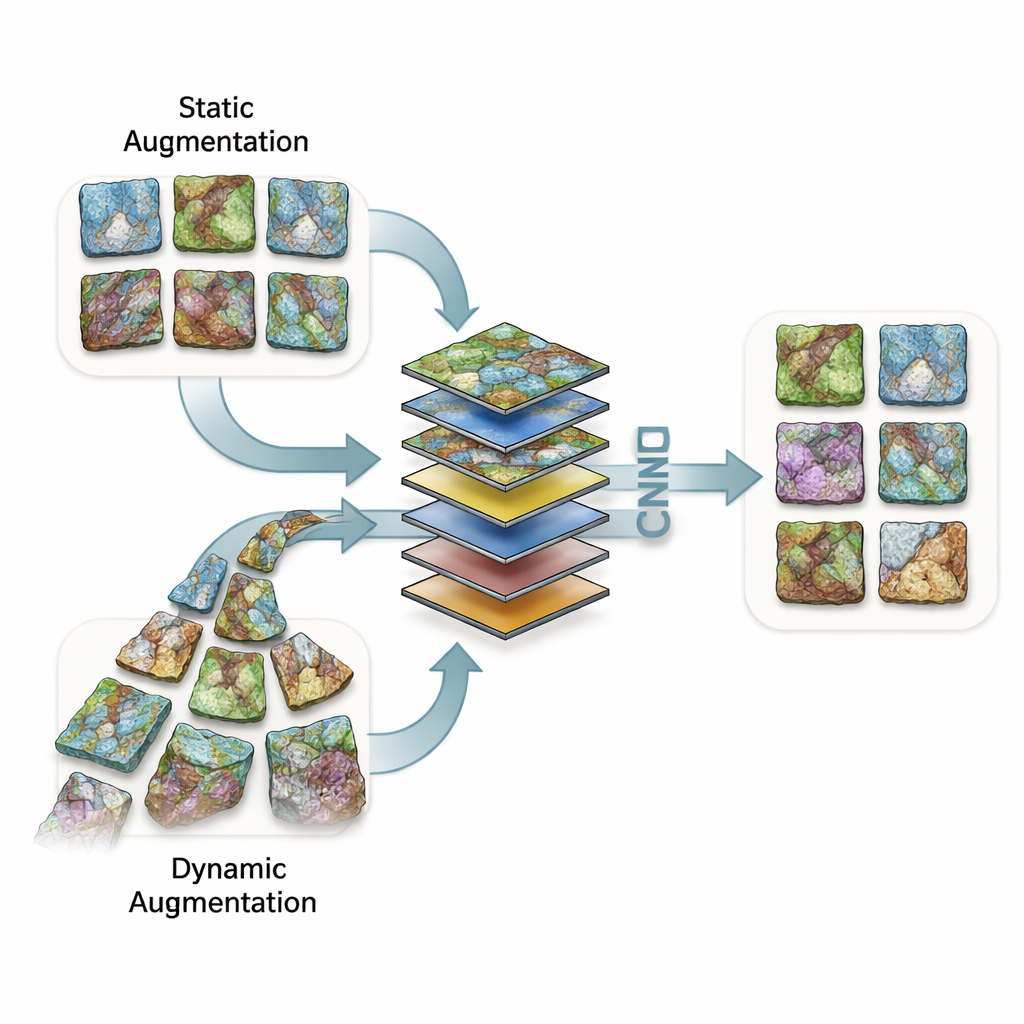
Um begrenzte Bildmengen auszugleichen, erstellen Forscher häufig veränderte Kopien der Originale — Spiegeln, Verschieben, Drehen, Zoomen oder Mischen von Bildern — damit ein Modell lernt, irrelevante Unterschiede zu ignorieren. Diese Studie verglich zwei grundsätzliche Vorgehensweisen. Bei der statischen Augmentation werden zusätzliche Bilder vor dem Training erzeugt und gespeichert, wodurch der Datensatz dauerhaft vergrößert wird. Bei der dynamischen Augmentation erzeugt der Computer während des Trainings zufällige Transformationen „on the fly“, sodass jede Durchlaufphase leicht unterschiedliche Versionen desselben Gesteins sehen kann. Das Team untersuchte 133 detaillierte Transformationskonfigurationen — von sanften Spiegelungen bis zu extremen Zooms und Rotationen sowie fortgeschritteneren „Bildmischungen“, bei denen zwei Gesteine mathematisch miteinander verschmolzen oder zusammengesetzt werden.
Fünf Gehirne auf die Probe stellen
Die Forschenden trainierten fünf verschiedene convolutional neural networks: drei bekannte Architekturen, die auf Alltagsfotos vortrainiert waren, und zwei einfachere Modelle, die von Grund auf neu aufgebaut wurden. In 691 einzelnen Experimenten maßen sie, wie oft jedes Modell Validierungsbilder nach Anwendung unterschiedlicher Augmentationsstrategien korrekt klassifizierte. Ohne jegliche Augmentation und bei reichlich Daten erreichte das beste vortrainierte Netzwerk bereits etwa 98–99 % Genauigkeit. Mit dem kleineren Trainingssatz sank die Genauigkeit, sodass Augmentation potenziell wertvoll erschien — doch die Ergebnisse zeigten, dass nicht alle zusätzlichen Daten hilfreich sind.
Wenn mehr Vielfalt schadet statt nutzt
Die auffälligste Erkenntnis ist, dass Augmentation ein zweischneidiges Schwert ist. Viele gängige geometrische Tricks, insbesondere starke Zooms und große Rotationen, verringerten die Genauigkeit, teils erheblich, wenn sie dynamisch während des Trainings angewendet wurden. Solche Operationen können die winzigen Mineralgefüge und Texturen, die wesentliche geologische Informationen tragen, dehnen oder verwischen und dem Modell damit beibringen, auf Muster zu achten, die in realen Proben nicht existieren. Statische Augmentation, bei der die transformierten Bilder fest sind und konsistent wiederverwendet werden, führte im Allgemeinen zu stabileren und manchmal besseren Ergebnissen. Einfache Spiegelungen und kleine Verschiebungen erwiesen sich als ungefährlich, aggressive Transformationen waren jedoch riskant, sofern sie nicht sorgfältig kontrolliert wurden.
Bilder mischen, um die Generalisierung zu verbessern
Am vielversprechendsten waren lineare und nichtlineare Bildmischverfahren, die zwei Gesteinsbilder kombinieren, um ein neues Trainingsbeispiel zu erzeugen. Varianten, die Bilder pixelweise mitteln, kacheln oder zusammenführen, bewahrten oder verbesserten die Genauigkeit konsistent, insbesondere für den kleineren Datensatz. Ein mit solchen statisch gemischten Bildern trainiertes Modell generalisierte besser auf zuvor ungesehene Daten, einschließlich synthetischer Gesteinsbilder, die von einem anderen KI‑System erzeugt worden waren, und realer Steine, die auf ungewohnte Weise verarbeitet worden waren, etwa mit entfernten Hintergründen oder komplexen Verzerrungen. Bemerkenswerterweise übertraf dieses augmentierte Modell, das mit weit weniger Originalbildern trainiert wurde, mitunter ein deutlich größeres Modell, das auf dem vollständigen, nicht augmentierten Datensatz trainiert worden war.
Was das für die zukünftige geologische KI bedeutet
Für Nicht‑Spezialisten ist die Kernbotschaft: „Mehr Daten“, die durch einfache Bildtricks erzeugt werden, machen ein KI‑System nicht automatisch zuverlässiger. In den feinen Texturen mikroskopischer Gesteine können bestimmte Verzerrungen genau die Merkmale löschen, die Geologen wichtig sind. Die Studie zeigt, dass sorgfältig ausgewählte statische Augmentation und durchdachtes Bildmischen teilweise für knappe Daten kompensieren und die Fähigkeit von Modellen verbessern können, mit neuen, ungewohnten Bildern umzugehen. Gleichzeitig kann unkritischer Einsatz aggressiver, dynamischer Transformationen die Genauigkeit heimlich untergraben. Anders gesagt: Für die automatisierte Gesteinsklassifikation — und wahrscheinlich für viele wissenschaftliche Bildgebungsaufgaben — ist die Art und Weise, wie wir neue Trainingsbilder erzeugen, ebenso wichtig wie ihre Anzahl.
Zitation: Habrat, M., Młynarczuk, M. Impact of data space augmentation strategy on model accuracy and generalization in thin-section rock classification. Sci Rep 16, 13927 (2026). https://doi.org/10.1038/s41598-026-44320-y
Schlüsselwörter: Gesteinsmikroskopie, Datenerweiterung, Geologie KI, Bildklassifikation, Dünnschliffe