Clear Sky Science · ru
Влияние стратегии увеличения пространства данных на точность модели и обобщающую способность при классификации тонких срезов пород
Почему важны более «умные» снимки пород
Глубоко под землёй строение пород определяет, где могут перемещаться или запасаться вода, нефть, газ и даже диоксид углерода. Геологи изучают ультратонкие срезы пород под микроскопом, чтобы прочитать эту скрытую архитектуру. Всё чаще компьютеры обучают распознавать типы пород по таким изображениям. В статье поставлен на первый взгляд простой, но важный практический вопрос: когда мы искусственно расширяем эти коллекции изображений с помощью «увеличения данных», действительно ли мы делаем компьютер умнее — или иногда можем его ухудшить?
Обучение компьютеров при ограниченном количестве фотографий пород
Для обучения систем распознавания изображений обычно требуется тысячи примеров. В геологии собрать такое количество микроскопических снимков медленно и дорого: образцы нужно пробурить, распилить, отполировать и сфотографировать, причём многие наборы данных остаются конфиденциальными у компаний. Авторы работали с реалистичной коллекцией из 34 775 микроскопических изображений тонких срезов, разделённых на 36 категорий пород, таких как песчаник, известняк и базальт. Они также сформировали уменьшенную «ограниченную» версию данных с 100 обучающими и 50 валидационными изображениями на класс, чтобы смоделировать распространённую ситуацию нехватки данных.
Растягивание данных, не ломая породы
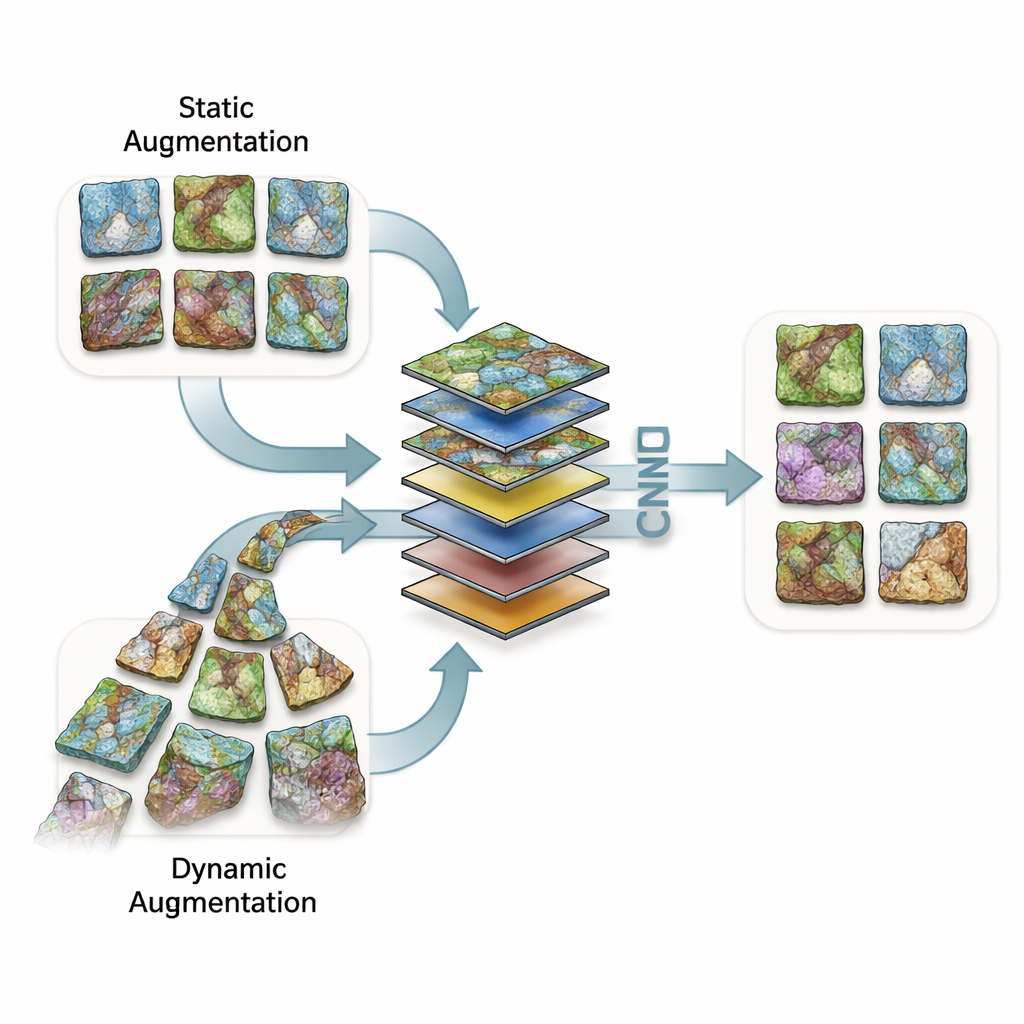
Чтобы компенсировать недостаток изображений, исследователи часто создают модифицированные копии оригиналов — отражают, сдвигают, поворачивают, масштабируют или смешивают снимки — чтобы помочь модели научиться игнорировать нерелевантные отличия. В этом исследовании сравнивались два широких подхода. При статическом увеличении дополнительные изображения создаются и сохраняются до обучения, постоянно расширяя набор данных. При динамическом увеличении компьютер генерирует случайные преобразования «на лету» во время обучения, так что при каждом проходе модель видит слегка изменённую версию одного и того же среза. Команда исследовала 133 подробных конфигурации преобразований — от деликатных зеркальных отражений до экстремальных зумов и вращений, а также более сложных приёмов «смешивания изображений», где два снимка математически смешиваются или склеиваются.
Пять «мозгов» на испытании
Исследователи обучили пять различных сверточных нейронных сетей: три широко известные архитектуры, предварительно обученные на бытовых фотографиях, и две более простые модели, созданные с нуля. В 691 отдельном эксперименте они измеряли, как часто каждая модель правильно классифицировала валидационные изображения при разных стратегиях увеличения данных. Без увеличения и при большом объёме данных лучшая предварительно обученная сеть уже достигала примерно 98–99% точности. При уменьшенном наборе обучающих данных точность падала, и увеличение данных могло казаться полезным — но результаты показали, что не все дополнительные изображения помогают.
Когда больше разнообразия вредит вместо пользы
Самый заметный вывод: увеличение данных — палка о двух концах. Многие широко используемые геометрические приёмы, особенно сильный зум и большие углы поворота, на самом деле снижали точность, порой значительно, когда применялись динамически во время обучения. Эти операции могут растянуть или размыть крошечные зерна минералов и текстуры, которые несут ключевую геологическую информацию, фактически обучая модель обращать внимание на паттерны, не встречающиеся в реальных пробах. Статическое увеличение, при котором преобразованные изображения фиксированы и используются повторно, в целом давало более стабильные и иногда лучшие результаты. Простые отражения и небольшие сдвиги оказались безопасными, но агрессивные преобразования были рискованны без тщательного контроля.
Смешивание изображений для лучшей обобщающей способности
Наиболее перспективными оказались линейные и нелинейные техники смешивания изображений, которые комбинируют два снимка породы, создавая новый обучающий пример. Варианты, усредняющие, тайлинговые или поэлементно объединяющие изображения, последовательно сохраняли или улучшали точность, особенно для уменьшенного набора данных. Модель, обученная на таких статически смешанных изображениях, лучше обобщала на ранее невидимые данные, включая синтетические изображения пород, сгенерированные другой системой ИИ, и реальные образцы, обработанные нетипичными способами — например с удалённым фоном или со сложными искажениями. Примечательно, что эта дополненная модель, обученная на гораздо меньшем количестве исходных снимков, иногда превосходила значительно большую модель, обученную на полном, неувеличенном наборе данных.
Что это значит для будущего геологического ИИ
Для неспециалистов ключевой вывод в том, что «больше данных», созданных простыми приёмами с изображениями, не делает систему ИИ автоматически более надёжной. В тонких текстурах микроскопических пород некоторые искажения могут стереть именно те признаки, которые важны геологам. Исследование показывает, что тщательно подобранное статическое увеличение и продуманное смешивание изображений могут частично компенсировать нехватку данных и улучшить способность моделей работать с новыми, нетипичными изображениями. В то же время некритичное применение агрессивных динамических преобразований может незаметно подорвать точность. Другими словами, для автоматической классификации пород — и, вероятно, для многих научных задач в области анализа изображений — способ генерации новых обучающих изображений важен не меньше, чем их количество.
Цитирование: Habrat, M., Młynarczuk, M. Impact of data space augmentation strategy on model accuracy and generalization in thin-section rock classification. Sci Rep 16, 13927 (2026). https://doi.org/10.1038/s41598-026-44320-y
Ключевые слова: микроскопия горных пород, увеличение данных, геология ИИ, классификация изображений, тонкие срезы