Clear Sky Science · en
Impact of data space augmentation strategy on model accuracy and generalization in thin-section rock classification
Why smarter rock pictures matter
Deep underground, the way rocks are put together controls where water, oil, gas, and even carbon dioxide can flow or be stored. Geologists study ultra‑thin rock slices under a microscope to read this hidden architecture. Increasingly, computers are being trained to recognize rock types from such images. This paper asks a deceptively simple question with big practical consequences: when we artificially enlarge these image collections through “data augmentation,” do we really make the computer smarter—or can we sometimes make it worse?
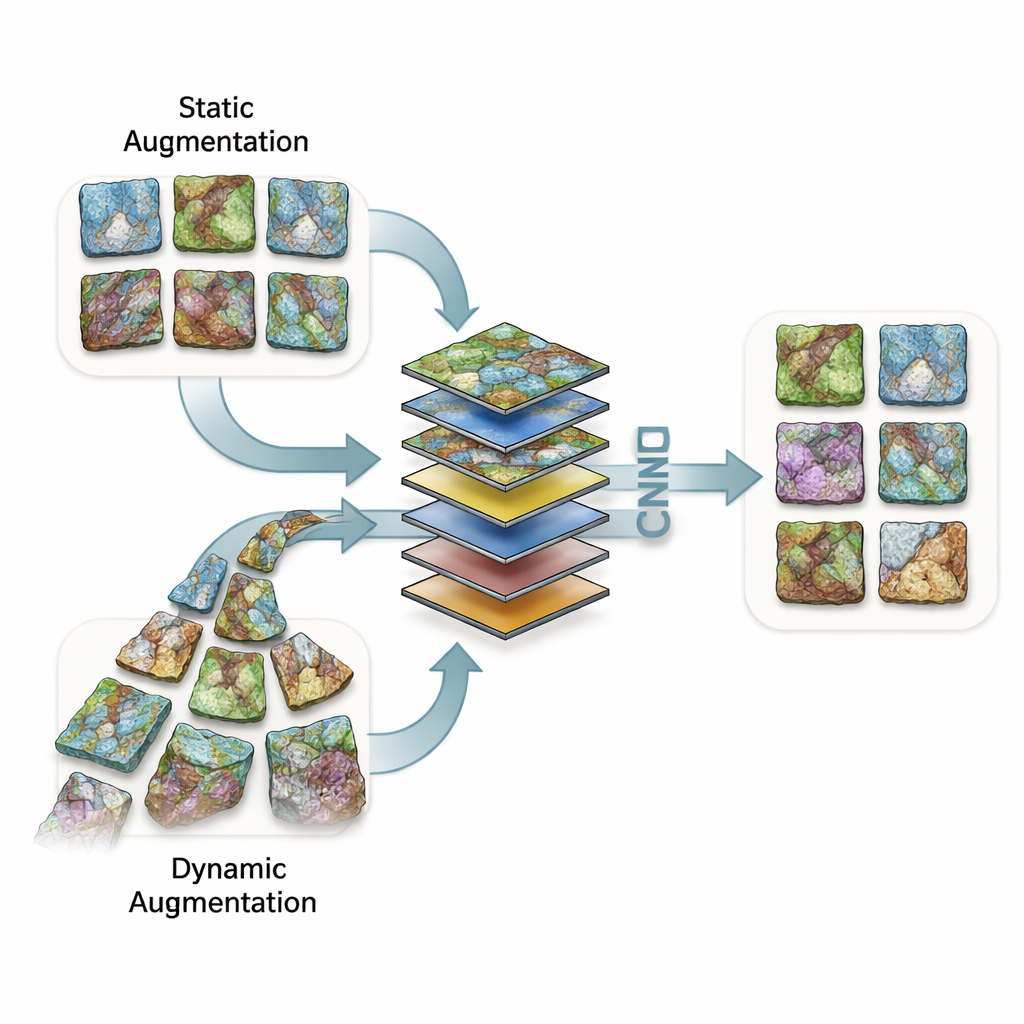
Teaching computers with limited rock photos
Training an image‑recognition system usually requires thousands of examples. In geology, collecting that many microscopic rock images is slow and expensive: samples must be drilled, cut, polished, and photographed, and many datasets are kept confidential by companies. The authors worked with a realistic collection of 34,775 microscope images of thin rock slices, divided into 36 rock categories such as sandstone, limestone, and basalt. They also defined a smaller “limited data” version with only 100 training and 50 validation images per class to mimic the common situation where data are scarce.
Stretching the data without breaking the rocks
To compensate for limited images, researchers often create modified copies of the originals—flipping, shifting, rotating, zooming, or mixing pictures together—to help a model learn to ignore irrelevant differences. This study compared two broad ways of doing this. In static augmentation, extra images are created and saved before training, permanently enlarging the dataset. In dynamic augmentation, the computer generates random transformations on the fly during training, so each pass may see a slightly different version of the same rock. The team explored 133 detailed transformation setups—ranging from gentle mirror flips to extreme zooms and rotations, as well as more advanced “image mixing” where two rocks are mathematically blended or spliced together.
Putting five brains to the test
The researchers trained five different convolutional neural networks: three well‑known architectures pre‑trained on everyday photographs, and two simpler models built from scratch. Across 691 separate experiments, they measured how often each model correctly classified validation images after using different augmentation strategies. Without any augmentation and given plenty of data, the best pre‑trained network already reached about 98–99% accuracy. With the smaller training set, accuracy dropped, making augmentation potentially valuable—but the results showed that not all extra data are helpful.
When more variety hurts instead of helps
The most striking finding is that augmentation is a double‑edged sword. Many commonly used geometric tricks, especially strong zooms and large rotations, actually reduced accuracy, sometimes dramatically, when applied dynamically during training. These operations can stretch or blur the tiny mineral grains and textures that carry essential geological information, effectively teaching the model to pay attention to patterns that do not exist in real samples. Static augmentation, where the transformed images are fixed and consistently reused, generally led to more stable and sometimes better results. Simple flips and small shifts tended to be safe, but aggressive transformations were risky unless carefully controlled.
Blending images to boost generalization
The most promising methods were linear and nonlinear image‑mixing techniques, which combine two rock images to create a new training example. Variants that averaged, tiled, or merged images pixel‑by‑pixel consistently preserved or improved accuracy, especially for the smaller dataset. A model trained with such static mixed images generalized better to previously unseen data, including synthetic rock pictures generated by another AI system and real rocks that had been processed in unfamiliar ways, such as with the background removed or with complex distortions. Remarkably, this augmented model, trained on far fewer original images, sometimes outperformed a much larger model trained on the full, unaugmented dataset.
What this means for future geological AI
For non‑specialists, the key message is that “more data” created by simple image tricks does not automatically make an AI system more reliable. In the delicate textures of microscopic rocks, certain distortions can erase exactly the features geologists care about. This study shows that carefully chosen static augmentation and thoughtful image mixing can partly compensate for limited data and improve how well models handle new, unfamiliar images. At the same time, uncritical use of aggressive, dynamic transformations can quietly erode accuracy. In other words, for automated rock classification—and likely for many scientific imaging tasks—the way we invent new training images matters just as much as how many we have.
Citation: Habrat, M., Młynarczuk, M. Impact of data space augmentation strategy on model accuracy and generalization in thin-section rock classification. Sci Rep 16, 13927 (2026). https://doi.org/10.1038/s41598-026-44320-y
Keywords: rock microscopy, data augmentation, geology AI, image classification, thin sections