Clear Sky Science · ja
薄片岩類分類におけるデータ空間拡張戦略がモデル精度と一般化に与える影響
なぜより賢い岩石画像が重要なのか
地下深部では、岩石の構造が水や石油、天然ガス、さらには二酸化炭素の流れや貯留場所を決定します。地質学者は、顕微鏡下の極薄の岩片を調べてその隠れた構造を読み取ります。近年、こうした画像から岩石種類を識別するようコンピュータを訓練する取り組みが進んでいます。本論文は一見単純だが実務上大きな意味を持つ問いを投げかけます:画像コレクションを「データ拡張」によって人工的に増やしたとき、本当にコンピュータは賢くなるのか——あるいは時に悪化させてしまうことはないのか?
限られた岩石写真でコンピュータを教える
画像認識システムの訓練には通常数千点の例が必要です。地質学ではその数の顕微鏡写真を集めるのは時間と費用がかかります:試料を掘削し、切断し、研磨して撮影する必要があり、多くのデータセットは企業によって機密扱いされています。著者らは、砂岩、石灰岩、玄武岩など36の岩種に分類された34,775枚の実用的な薄片顕微鏡画像コレクションを用いて作業しました。さらに、データが不足する一般的な状況を模倣するため、クラスごとに訓練100枚・検証50枚だけの小さな「限定データ」版も定義しました。
岩石を壊さずにデータを引き伸ばす
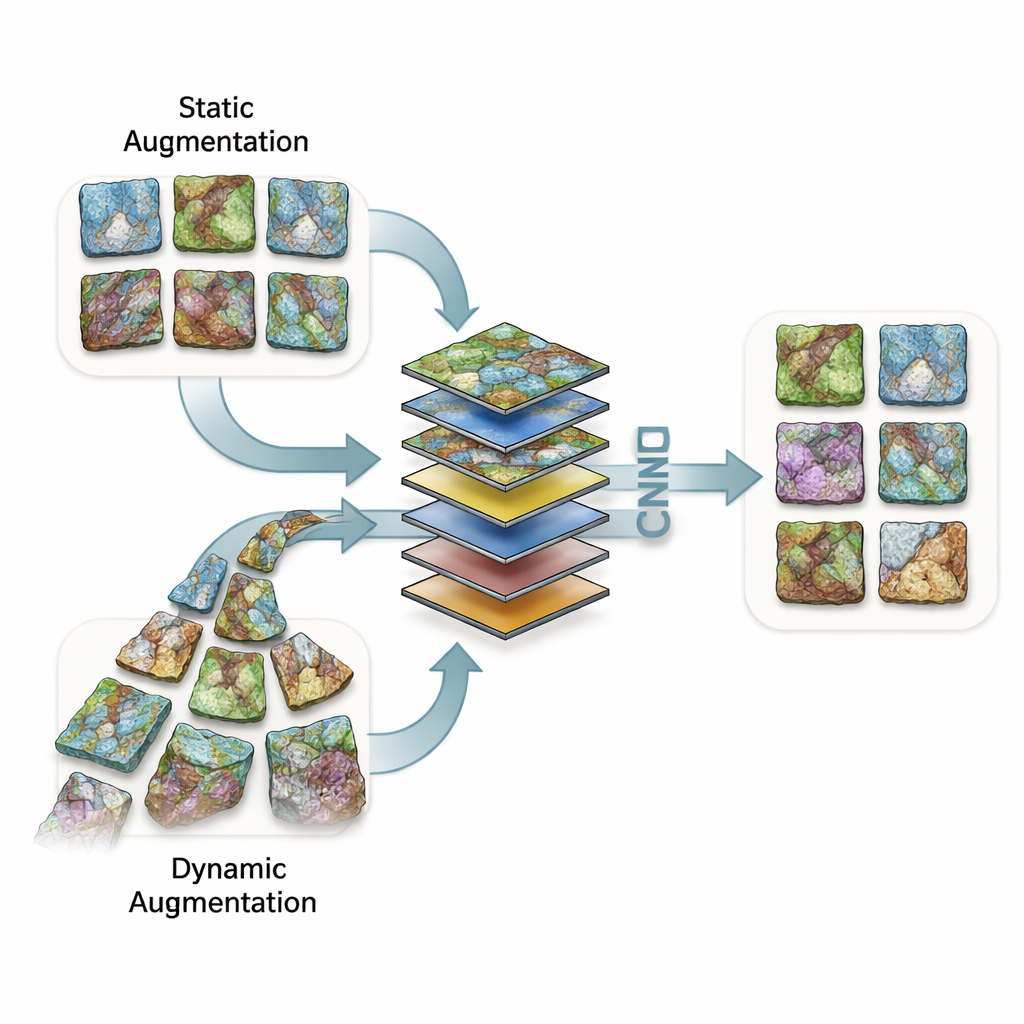
画像点数が限られる場合、研究者は元画像の修正版を作成することがよくあります——反転、平行移動、回転、ズーム、あるいは画像同士を混ぜるなどして、モデルが無関係な差異を無視できるように学習させます。本研究ではこうした手法を大きく二通りに分けて比較しました。静的拡張では、追加画像を訓練前に生成して保存し、データセットを恒久的に増やします。動的拡張では、訓練中にランダムな変換を都度生成し、同じ岩片でも各エポックでわずかに異なるバージョンを見せます。研究チームは、穏やかな鏡像反転から極端なズームや回転、さらには二つの岩石画像を数学的に混ぜたり切り貼りしたりする高度な「画像混合」まで、133種類の詳細な変換設定を検討しました。
五つのモデルで試す
研究者らは5種類の畳み込みニューラルネットワークを訓練しました:日常写真で事前学習されたよく知られたアーキテクチャが3つ、そしてスクラッチから構築したより単純なモデルが2つです。691の個別実験を通じて、各モデルがさまざまな拡張戦略のもとで検証画像をどれだけ正しく分類できたかを測定しました。拡張を行わず大量のデータがある場合、最良の事前学習ネットワークは既に約98〜99%の精度に達していました。より小さな訓練セットでは精度が低下し、拡張が有用になり得る一方で、すべての追加データが有益とは限らないことが結果から示されました。
多様性が役に立たない場合
もっとも印象的な発見は、拡張が刃の両面を持つことです。特に強いズームや大きな回転といった多くの一般的な幾何学的操作は、訓練中に動的に適用すると精度を低下させ、時には著しく悪化させました。こうした操作は、重要な地質情報を担う極めて細かい鉱物粒やテクスチャを伸ばしたりぼかしたりし、実際の試料に存在しないパターンにモデルが注意を払うように教えてしまう可能性があります。変換後の画像を固定して一貫して再利用する静的拡張は、一般により安定し、時により良い結果をもたらしました。単純な反転や小さな平行移動は安全な傾向がありましたが、攻撃的な変換は慎重に制御しない限りリスクが高いことが示されました。
画像を混ぜて一般化を高める
最も有望だったのは、二つの岩石画像を組み合わせて新たな訓練例を作る線形および非線形の画像混合手法でした。画素ごとに平均化、タイル化、またはマージするバリアントは、一貫して精度を維持または向上させ、とくに小規模データセットで効果的でした。こうした静的な混合画像で訓練したモデルは、別のAIで生成された合成岩画像や、背景が除去されたり複雑な歪みが入ったりして従来とは異なる処理を受けた実物の岩など、未見のデータに対してより良く一般化しました。注目すべきことに、元画像がはるかに少ない状態で訓練されたこの拡張モデルは、フルサイズの未拡張データで訓練されたはるかに大きなモデルを上回ることさえありました。
将来の地質学的AIへの含意
専門外の方への要点は、単純な画像処理で「より多くのデータ」を作っても、AIシステムが自動的に信頼できるようになるわけではないということです。顕微鏡レベルの繊細なテクスチャでは、特定の歪みが地質学者が重要視する特徴を消してしまう恐れがあります。本研究は、慎重に選ばれた静的拡張と考え抜かれた画像混合がデータ不足を部分的に補い、新しい未知の画像に対するモデルの応答を改善し得ることを示しています。一方で、吟味せずに攻撃的な動的変換を用いると、知らぬ間に精度を損なう可能性があります。言い換えれば、自動化された岩石分類——そして多くの科学的画像処理の課題においても——どのようにして新しい訓練画像を作るかが、単に数を増やすことと同じくらい重要なのです。
引用: Habrat, M., Młynarczuk, M. Impact of data space augmentation strategy on model accuracy and generalization in thin-section rock classification. Sci Rep 16, 13927 (2026). https://doi.org/10.1038/s41598-026-44320-y
キーワード: 岩石顕微鏡観察, データ拡張, 地質学AI, 画像分類, 薄片