Clear Sky Science · sv
Bedömning av idrottsutförande baserat på överförings-nätverkspoängavkoppling i komplexa sportscenarier
Varför smartare sportbedömning spelar roll
Från olympisk simhoppning till breakdance-tävlingar förlitar sig många sporter på mänskliga domare som omvandlar invecklade rörelser till en enda poäng. Men långa framträdanden är ojämna: vissa ögonblick är spektakulära, andra skakiga eller bara utfyllnad. Denna studie undersöker hur artificiell intelligens kan se hela videor av komplexa framträdanden, plocka ut de verkligen viktiga ögonblicken och skapa mer konsekventa, detaljerade poäng som kan stödja domare, tränare, läkare och vardagliga lärande.
Att se hela föreställningen, inte bara höjdpunktsklippen
Traditionella datorsystem som bedömer atletiska prestationer behandlar ofta en hel video som om varje sekund vore lika viktig. Den antagningen fallerar i verkliga tävlingar. I breakdance, till exempel, spelar tidiga steg som följer musiken mindre roll än svåra golvrörelser, freeze eller kraftfulla snurrar längre fram. Befintliga metoder slätar ofta ihop allt, vilket döljer både briljanta rörelser och kritiska misstag. Författarna ser detta som ett generellt problem i långa färdighetsvideor: kvaliteten varierar över tid, och positivt och negativt bevismaterial kan samexistera i samma framträdande. Målet är att bygga ett system som separerar nyckelögonblicken från bakgrundsrörelsen, vilket gör det lättare att jämföra hur bra två personer faktiskt presterade.
Två sätt att betrakta samma framträdande
Den föreslagna modellen betraktar varje video genom två separata linser. En "dynamisk" ström fokuserar på rörelse över tid med korta klipp och fångar rytm, flyt och kontinuitet. Den andra "statiska" strömmen granskar enskilda bildrutor och uppfattar hållning, kroppskontroll och små formfel som kan dyka upp bara för ett ögonblick. Avgörande är att dessa strömmar inte blandas tidigt. Var och en lär sig först sin egen bild av prestationen, vilket hjälper till att förhindra att kortvariga hållningsfel dränks av långa jämna sekvenser eller tvärtom. Först efter att varje ström format sina kvalitetsmedvetna funktioner kombineras de för att uppskatta en totalpoäng.
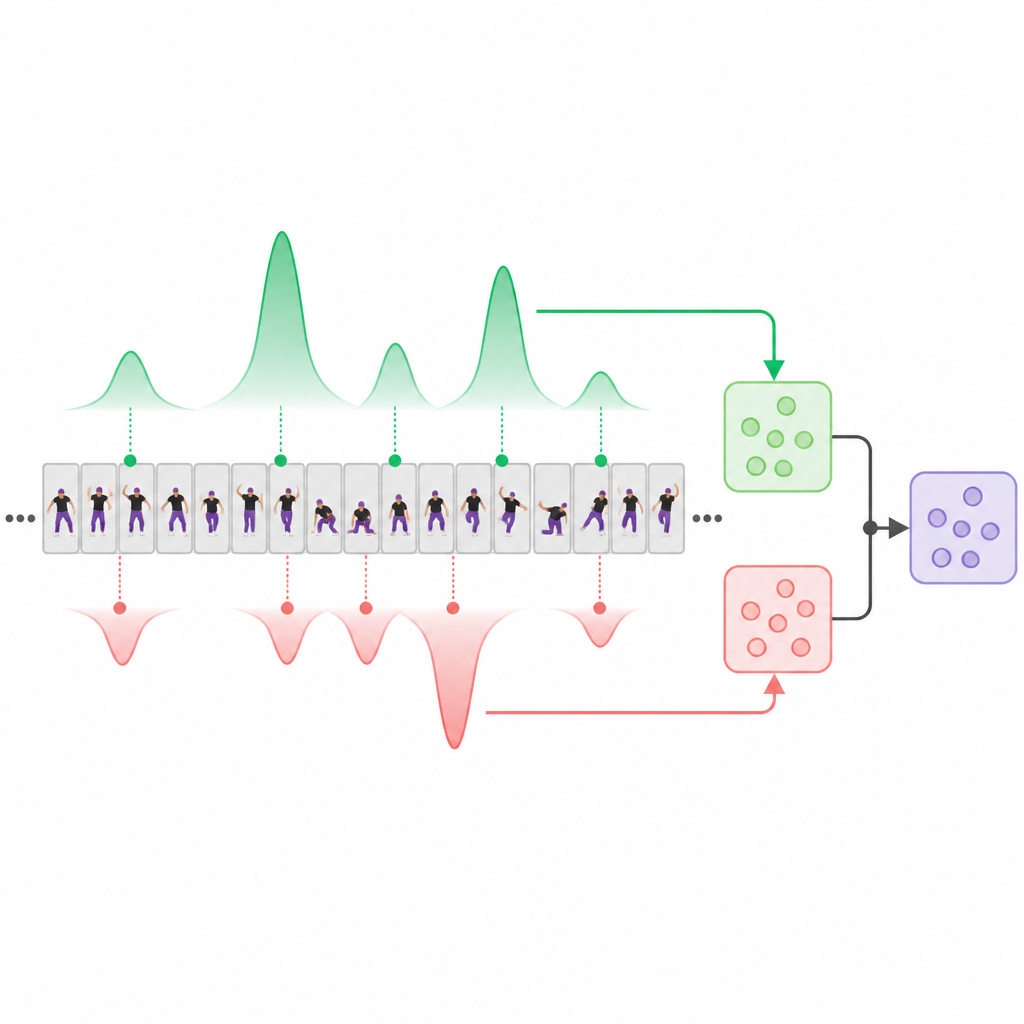
Att separera starka rörelser från svaga
I systemets kärna finns en "poängavkopplings"-modul som explicit separerar videosegment som ser ut att vara starka bevis på skicklighet från dem som tyder på svagare eller bristfällig utförande. Inspirerad av moderna uppmärksamhetsbaserade nätverk lär sig modellen två interna "prototyper": en som söker upp högkvalitativa ögonblick och en annan som fokuserar på lågkvalitativa. När videon bearbetas tilldelar varje prototyp olika vikter till olika segment och producerar två kompletterande sammanfattningar: en byggd från de bäst utseende klippen och en från de sämsta eller minst hjälpsamma klippen. Ett enkelt tidsmedelvärde behålls också som en neutral referens. Särskilda träningsregler driver de hög- och lågkvalitativa vyerna att skilja sig på användbara sätt och att fokusera på olika delar av videon, istället för att kollapsa till samma få uppenbara rutor.
Lära sig rangordna prestationer genom att jämföra par
I stället för att förlita sig på exakta numeriska poäng från mänskliga experter tränas systemet huvudsakligen på parvisa jämförelser: givet två videor, vilken utövare visade bättre skicklighet totalt sett? För varje par förutsäger modellen poäng för deras högkvalitativa, lågkvalitativa och genomsnittliga grenar och straffas om den får ordningen fel eller om de separerade grenarna inte är mer diskriminerande än det enkla genomsnittet. Ytterligare träningsvillkor uppmuntrar "bra" och "dåliga" vyer att lyfta fram olika tidssegment. När träningen är klar kan systemet titta på en enda ny video och ge en stabil kvalitetspoäng, utan att behöva en referensvideo bredvid sig.
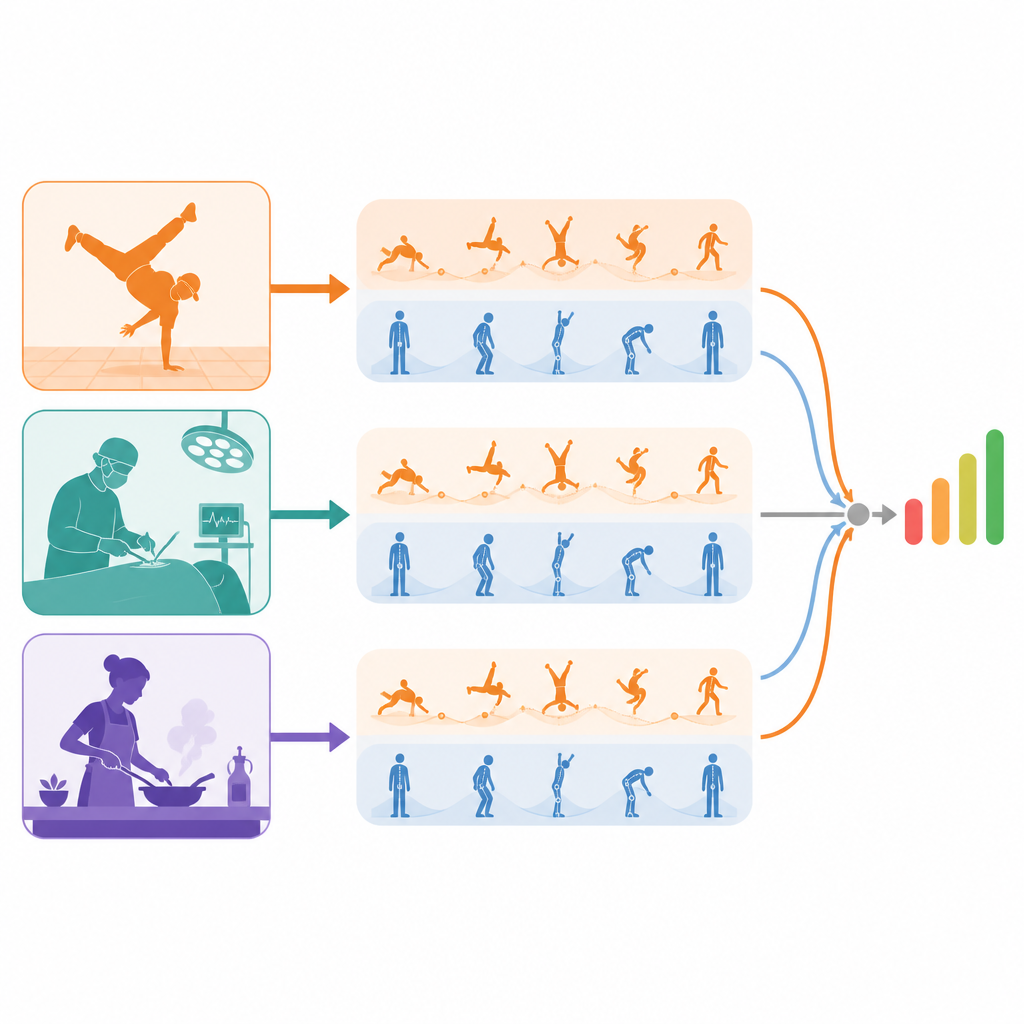
Från breakdance-tävlingar till kirurgi och vardagliga färdigheter
För att testa sitt tillvägagångssätt byggde författarna en ny datamängd med världsklassiga breakdance-tävlingar och utvärderade även metoden på två befintliga samlingar av långa färdighetsvideor: vardagliga uppgifter som teckning, matlagning och att knyta slips, samt kirurgiska och finmotoriska aktiviteter. I dessa olika sammanhang matchade eller överträffade deras modell vanligtvis noggrannheten hos ledande metoder när det gällde att avgöra vilken av två videor som visar högre skicklighet. Visualiseringar av modellens interna uppmärksamhetskartor visar att högkvalitativa grenar tenderar att markera välkontrollerade, tekniskt krävande rörelser, medan lågkvalitativa grenar betonar klumpiga övergångar eller ofullständiga handlingar. För en allmän läsare är slutsatsen att detta system lär datorer att inte bara känna igen vilken handling som sker, utan hur väl den utförs, genom att noggrant separera de bästa och sämsta delarna av en prestation innan de kombineras till en slutgiltig, tolkbar poäng.
Citering: Gao, L., Ma, Y., Bi, S. et al. Athlete action quality assessment based on transfer neural network quality score decoupling in complex sports scenarios. Sci Rep 16, 15795 (2026). https://doi.org/10.1038/s41598-026-43987-7
Nyckelord: bedömning av handlingars kvalitet, analys av sportvideor, breakdance, uppmärksamhetsbaserade modeller, färdighetsutvärdering