Clear Sky Science · de
Bewertung der Aktionsqualität von Athleten basierend auf der Entkopplung von Qualitätsbewertungen in Transfer-Neuronalen Netzen in komplexen Sportszenarien
Warum intelligentere Sportwertung wichtig ist
Von olympischem Turmspringen bis zu Breakdance-Battles: Viele Sportarten sind darauf angewiesen, dass menschliche Wertende komplexe Bewegungsabläufe in eine einzige Note überführen. Lange Performances sind jedoch uneinheitlich: manche Momente sind spektakulär, andere wackelig oder bloß Füllmaterial. Diese Studie untersucht, wie künstliche Intelligenz komplette Videos komplexer Darbietungen analysieren kann, die wirklich relevanten Momente auswählt und konsistentere, feinere Bewertungen erzeugt, die Richter, Trainer, Ärzte und Lernende unterstützen können.
Die ganze Show sehen, nicht nur die Highlights
Traditionelle Computersysteme zur Bewertung sportlicher Leistungen behandeln ein gesamtes Video oft so, als wäre jede Sekunde gleich wichtig. Diese Annahme versagt bei realen Auftritten. Beim Breakdance etwa sind frühe Schritte, die zur Musik passen, weniger entscheidend als schwierige Bodenelemente, Freezes oder Power-Spins später in der Darbietung. Bestehende Methoden glätten häufig alles zusammen, wodurch sowohl brillante Moves als auch kritische Fehler verdeckt werden. Die Autoren sehen darin ein allgemeines Problem bei langen Skill-Videos: Qualität schwankt über die Zeit, und positive und negative Hinweise können innerhalb derselben Performance koexistieren. Ihr Ziel ist ein System, das Schlüsselpassagen vom Hintergrund trennt, sodass sich Leistungsvergleiche zwischen zwei Personen leichter und genauer anstellen lassen.
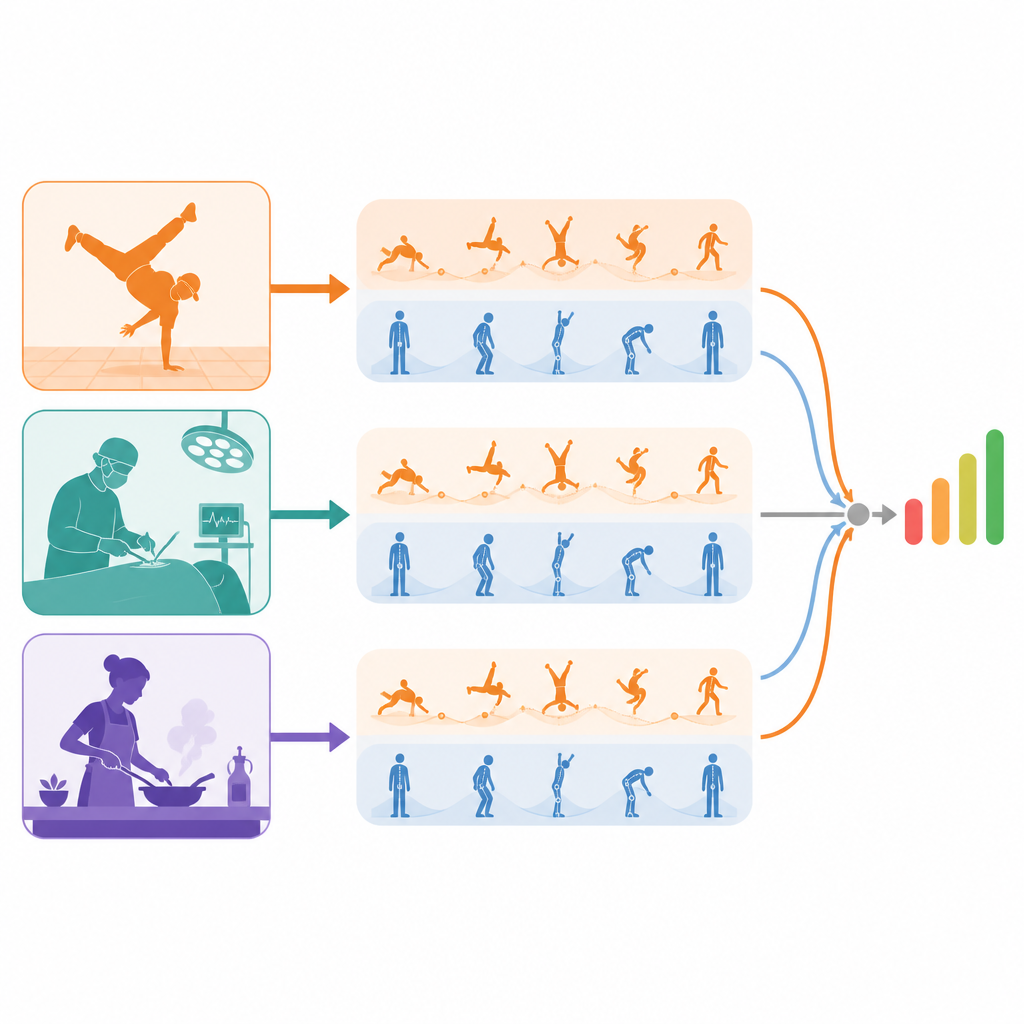
Zwei Blickwinkel auf dieselbe Performance
Das vorgeschlagene Modell betrachtet jedes Video durch zwei getrennte Linsen. Ein „dynamischer" Stream fokussiert sich auf Bewegung über die Zeit mittels kurzer Clips und erfasst Rhythmus, Fluss und Kontinuität. Der andere „statische" Stream untersucht einzelne Frames und erkennt Haltung, Körperkontrolle und kleine Formfehler, die nur für einen Moment sichtbar sind. Entscheidend ist, dass diese Streams nicht frühzeitig vermischt werden. Jeder entwickelt zunächst seine eigene Sicht auf die Darbietung, was verhindert, dass kurze Haltungsfehler in langen flüssigen Sequenzen untergehen oder umgekehrt. Erst nachdem jeder Stream qualitätsbewusste Merkmale gebildet hat, werden sie kombiniert, um eine Gesamtnote zu schätzen.
Starke Moves von schwachen trennen
Kern des Systems ist ein „Score-Decoupling"-Modul, das Videoabschnitte explizit in solche aufteilt, die als starke Hinweise für Fertigkeit gelten, und solche, die auf schwächere oder fehlerhafte Ausführung hindeuten. Inspiriert von modernen auf Attention basierenden Netzen lernt das Modell zwei interne „Prototypen": einen, der hochwertige Momente sucht, und einen anderen, der sich auf minderwertige konzentriert. Während das Video verarbeitet wird, gewichtet jeder Prototyp unterschiedliche Segmente und erzeugt zwei komplementäre Zusammenfassungen: eine aus den bestaussehenden Clips und eine aus den schlechtesten oder am wenigsten hilfreichen Clips. Zusätzlich wird ein einfacher zeitlicher Durchschnitt als neutrale Basis beibehalten. Spezielle Trainingsregeln zwingen die Hoch- und Niedrigqualitätssichten dazu, sich in nützlicher Weise zu unterscheiden und auf unterschiedliche Teile des Videos zu fokussieren, statt auf dieselben offensichtlichen Frames zusammenzufallen.
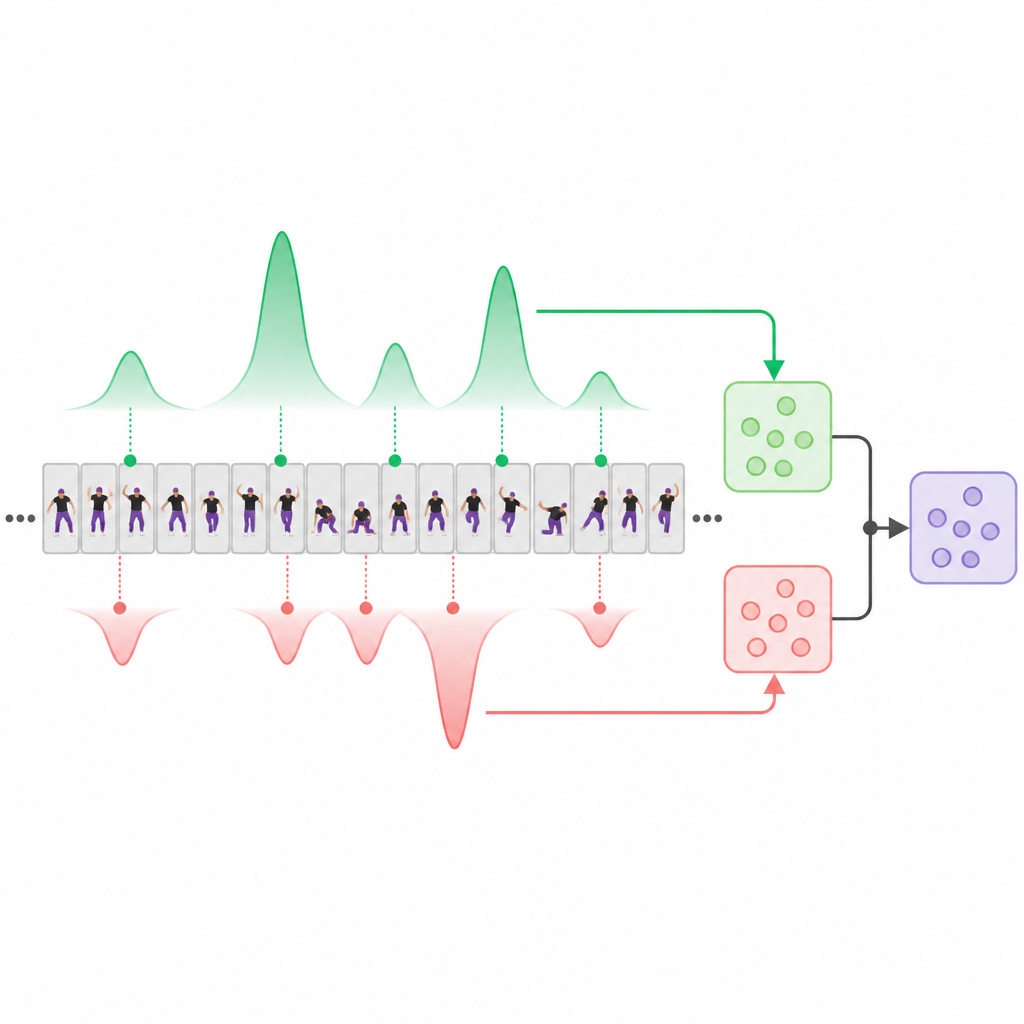
Lehren, Leistungen paarweise zu ordnen
Anstatt sich auf präzise numerische Bewertungen von menschlichen Expertinnen und Experten zu stützen, wird das System hauptsächlich mit paarweisen Vergleichen trainiert: Gegeben zwei Videos, welcher Performer zeigte insgesamt mehr Können? Für jedes Paar sagt das Modell Werte für seine Hochqualitäts-, Niedrigqualitäts- und Durchschnittszweige voraus und wird bestraft, wenn die Rangfolge falsch ist oder wenn die separierten Zweige nicht diskriminierender sind als der einfache Durchschnitt. Zusätzliche Trainingsbegriffe ermutigen die „guten" und „schlechten" Sichten, unterschiedliche Zeitsegmente zu betonen. Nach dem Training kann das System ein einzelnes neues Video anschauen und eine stabile Qualitätsnote ausgeben, ohne ein Referenzvideo daneben zu benötigen.
Von Breakdance-Battles bis zu Chirurgie und Alltagsfähigkeiten
Zur Evaluation bauten die Autoren ein neues Datenset mit Weltklasse-Breakdance-Battles auf und testeten die Methode außerdem an zwei bestehenden Sammlungen langer Skill-Videos: alltägliche Aufgaben wie Zeichnen, Kochen und Krawattenbinden sowie chirurgische und feinmotorische Aktivitäten. In diesen unterschiedlichen Settings erreichte ihr Modell meist die Genauigkeit führender Methoden oder übertraf sie bei der Entscheidung, welches von zwei Videos höhere Fertigkeit zeigt. Visualisierungen der internen Attention-Maps zeigen, dass Hochqualitätszweige tendenziell bei gut kontrollierten, technisch anspruchsvollen Moves aufleuchten, während Niedrigqualitätszweige unbeholfene Übergänge oder unvollendete Aktionen hervorheben. Für die interessierte Öffentlichkeit lautet die Quintessenz: Dieses System bringt Computern bei, nicht nur die Art einer Aktion zu erkennen, sondern wie gut sie ausgeführt wird, indem es sorgfältig die besten und schlechtesten Teile einer Darbietung trennt, bevor es sie zu einer finalen, interpretierbaren Bewertung zusammenführt.
Zitation: Gao, L., Ma, Y., Bi, S. et al. Athlete action quality assessment based on transfer neural network quality score decoupling in complex sports scenarios. Sci Rep 16, 15795 (2026). https://doi.org/10.1038/s41598-026-43987-7
Schlüsselwörter: Bewertung der Aktionsqualität, Analyse von Sportvideos, Breakdance, aufmerksamkeitbasierte Modelle, Fertigkeitsevaluation