Clear Sky Science · pt
Avaliação da qualidade de ações de atletas baseada no desacoplamento da pontuação de qualidade de redes neurais de transferência em cenários esportivos complexos
Por que julgamentos esportivos mais inteligentes importam
De saltos olímpicos a batalhas de breakdance, muitos esportes dependem de juízes humanos para transformar movimentos complexos em uma única nota. Mas performances longas são irregulares: alguns momentos são espetaculares, outros são instáveis ou simplesmente preenchimento. Este estudo explora como a inteligência artificial pode assistir a vídeos inteiros de apresentações complexas, selecionar os momentos verdadeiramente importantes e produzir notas mais consistentes e detalhadas que possam apoiar juízes, treinadores, médicos e aprendizes cotidianos.
Assistindo ao espetáculo inteiro, não apenas ao compacto
Sistemas computacionais tradicionais que avaliam desempenho atlético frequentemente tratam um vídeo completo como se cada segundo tivesse igual importância. Essa suposição falha em eventos reais. No breakdance, por exemplo, passos iniciais que acompanham a música importam menos do que movimentos difíceis no chão, freezes ou giros de potência mostrados mais tarde. Métodos existentes frequentemente fundem tudo, o que oculta tanto movimentos brilhantes quanto erros críticos. Os autores enquadram isso como um problema geral em vídeos longos de habilidades: a qualidade varia ao longo do tempo, e evidências positivas e negativas podem coexistir na mesma apresentação. O objetivo é construir um sistema que separe os momentos-chave do movimento de fundo, facilitando a comparação de quão bem duas pessoas realmente performaram.
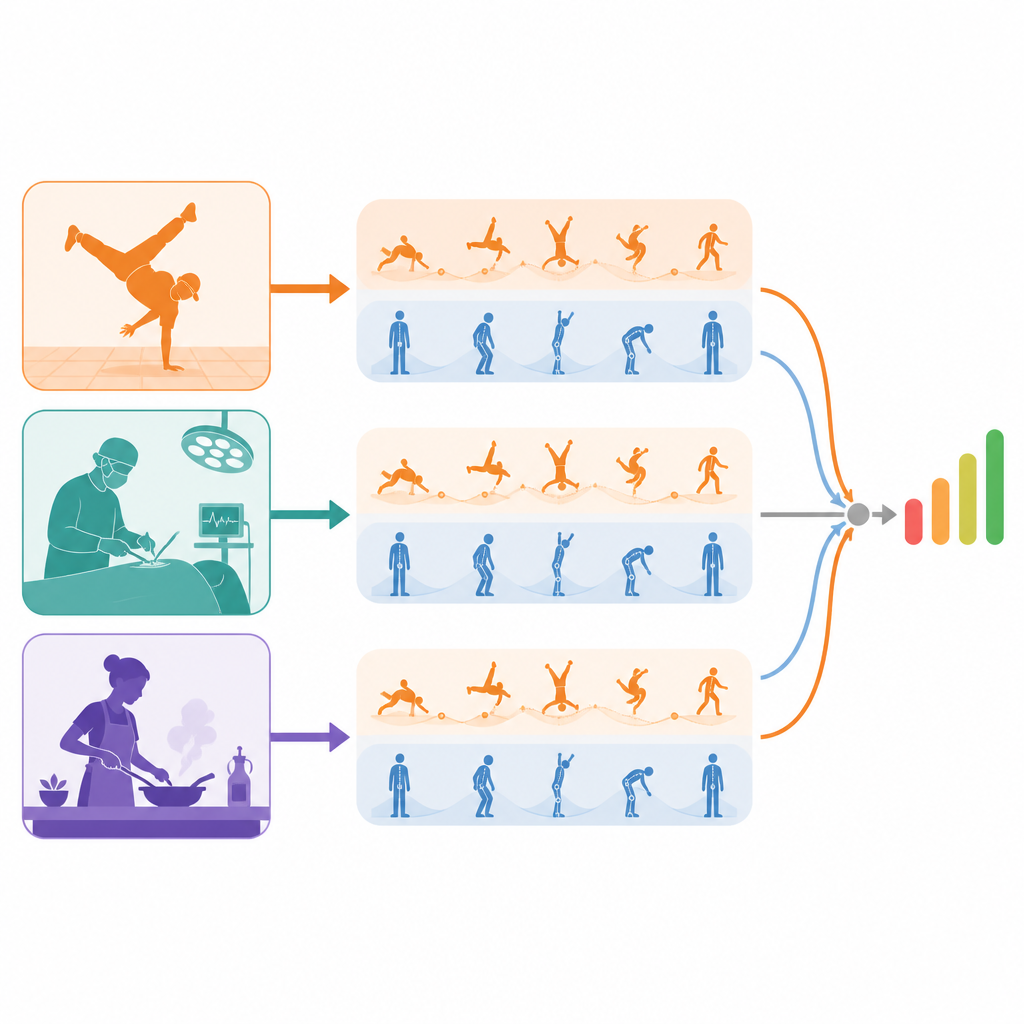
Dupla perspectiva sobre a mesma apresentação
O modelo proposto olha cada vídeo por meio de duas lentes separadas. Um fluxo “dinâmico” foca no movimento ao longo do tempo usando clipes curtos, capturando ritmo, fluxo e continuidade. O outro fluxo “estático” examina quadros individuais, identificando postura, controle corporal e pequenos erros de forma que podem aparecer apenas por um instante. Crucialmente, esses fluxos não são misturados cedo. Cada um primeiro aprende sua própria visão da performance, o que ajuda a evitar que breves erros de postura sejam afogados por sequências longas e suaves, ou o contrário. Só depois que cada fluxo forma suas características sensíveis à qualidade é que eles são combinados para estimar uma pontuação geral.
Separando movimentos fortes dos fracos
No cerne do sistema está um módulo de “desacoplamento de pontuação” que separa explicitamente segmentos de vídeo que parecem evidências fortes de habilidade daqueles que sugerem execução mais fraca ou com falhas. Inspirado em redes modernas baseadas em atenção, o modelo aprende dois “protótipos” internos: um que procura por momentos de alta qualidade e outro que se concentra nos de baixa qualidade. À medida que o vídeo é processado, cada protótipo atribui pesos diferentes a segmentos distintos, produzindo dois resumos complementares: um construído a partir dos clipes de melhor aparência e outro a partir dos piores ou menos informativos. Também se mantém uma média simples ao longo do tempo como linha de base neutra. Regras de treinamento especiais incentivam as visões de alta e baixa qualidade a discordarem de maneiras úteis e a focarem em partes diferentes do vídeo, em vez de colapsarem nas mesmas poucas frames óbvias.
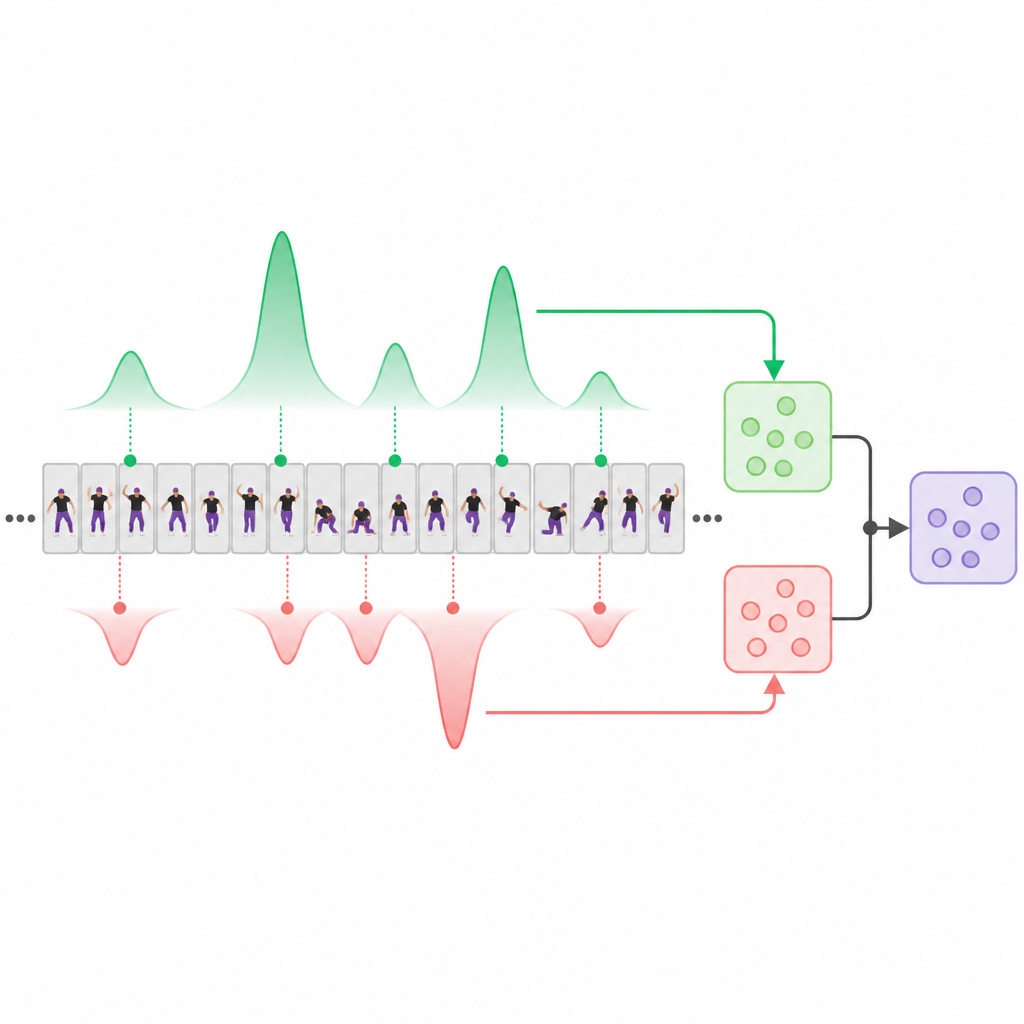
Aprendendo a rankear performances observando pares
Em vez de depender de pontuações numéricas precisas de especialistas humanos, o sistema é treinado principalmente em comparações pares: dado dois vídeos, qual intérprete mostrou melhor habilidade no geral? Para cada par, o modelo prevê pontuações para seus ramos de alta qualidade, baixa qualidade e média, e é penalizado se errar a ordenação ou se os ramos separados não forem mais discriminativos que a média simples. Termos adicionais de treinamento incentivam as visões “boas” e “ruins” a enfatizarem segmentos temporais diferentes. Após o treinamento, o sistema pode assistir a um novo vídeo isolado e produzir uma pontuação de qualidade estável, sem precisar de um vídeo de referência ao lado.
De batalhas de breakdance a cirurgia e habilidades do dia a dia
Para testar a abordagem, os autores construíram um novo conjunto de dados de batalhas de breakdance de nível mundial e também avaliaram o método em duas coleções existentes de vídeos longos de habilidades: tarefas cotidianas como desenhar, cozinhar e dar nó em gravata, e atividades cirúrgicas e de motricidade fina. Nesses cenários diversos, seu modelo tipicamente igualou ou superou a precisão de métodos líderes ao decidir qual de dois vídeos demonstra maior habilidade. Visualizações dos mapas de atenção internos mostram que os ramos de alta qualidade tendem a acender ao redor de movimentos bem controlados e tecnicamente exigentes, enquanto os ramos de baixa qualidade enfatizam transições estranhas ou ações incompletas. Para um leitor leigo, a conclusão é que este sistema ensina computadores não apenas a reconhecer qual ação está ocorrendo, mas quão bem ela é executada, separando cuidadosamente as melhores e piores partes de uma performance antes de combiná‑las em uma pontuação final e interpretável.
Citação: Gao, L., Ma, Y., Bi, S. et al. Athlete action quality assessment based on transfer neural network quality score decoupling in complex sports scenarios. Sci Rep 16, 15795 (2026). https://doi.org/10.1038/s41598-026-43987-7
Palavras-chave: avaliação da qualidade de ações, análise de vídeo esportivo, breakdance, modelos baseados em atenção, avaliação de habilidade