Clear Sky Science · it
Valutazione della qualità dell’azione degli atleti basata sulla decoupling del punteggio tramite reti neurali transfer in scenari sportivi complessi
Perché è importante giudicare lo sport in modo più intelligente
Dai tuffi olimpici alle battle di breakdance, molti sport si affidano a giudici umani che trasformano movimenti complessi in un punteggio unico. Ma le performance lunghe sono disomogenee: alcuni momenti sono spettacolari, altri sono incerti o semplicemente riempitivi. Questo studio esplora come l’intelligenza artificiale possa analizzare interi video di performance complesse, selezionare i momenti davvero importanti e produrre punteggi più coerenti e dettagliati che possano supportare giudici, allenatori, medici e praticanti.
Guardare l’intero spettacolo, non solo i momenti clou
I sistemi tradizionali che valutano le prestazioni atletiche spesso trattano un video completo come se ogni secondo avesse lo stesso peso. Questa assunzione fallisce negli eventi reali. Nella breakdance, ad esempio, i passi iniziali in sintonia con la musica contano meno rispetto a movimenti complessi a terra, freeze o power spin che arrivano dopo. I metodi esistenti tendono a omogeneizzare tutto, nascondendo sia mosse brillanti sia errori critici. Gli autori inquadrano questo come un problema generale nei video lunghi di abilità: la qualità varia nel tempo e evidenze positive e negative possono coesistere nella stessa performance. L’obiettivo è costruire un sistema che separi i momenti chiave dal movimento di fondo, facilitando il confronto reale di quanto bene due persone abbiano eseguito.
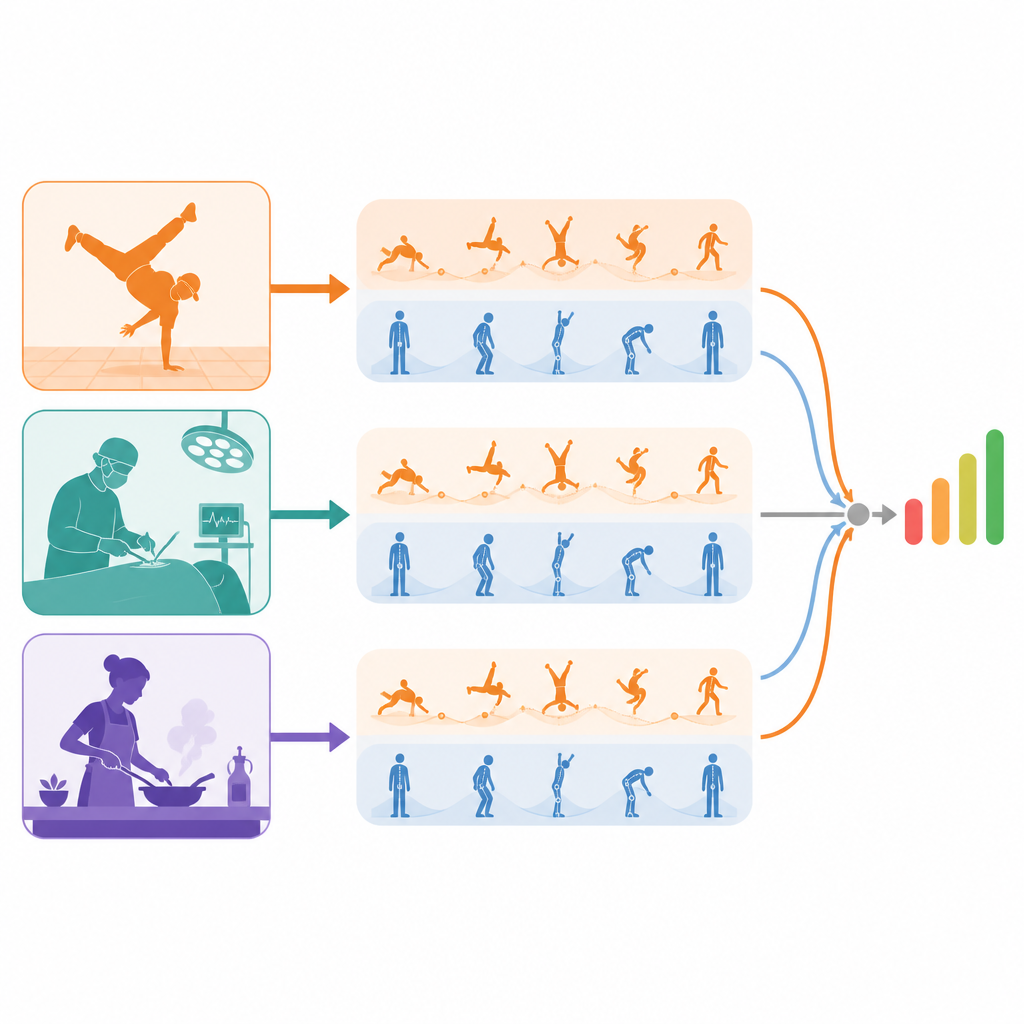
Due modi di osservare la stessa performance
Il modello proposto analizza ogni video attraverso due lenti separate. Un flusso “dinamico” si concentra sul movimento nel tempo usando clip brevi, catturando ritmo, flusso e continuità. L’altro flusso “statico” esamina singoli fotogrammi, rilevando postura, controllo del corpo ed errori di forma che possono apparire per un istante. Cruciale è che questi flussi non vengano mescolati precocemente. Ognuno impara prima la propria visione della performance, il che aiuta a evitare che brevi errori posturali vengano sommersi da lunghe sequenze fluide, o viceversa. Solo dopo che ogni flusso ha formato caratteristiche sensibili alla qualità vengono combinati per stimare un punteggio complessivo.
Separare le mosse forti da quelle deboli
Al centro del sistema c’è un modulo di “decoupling del punteggio” che separa esplicitamente i segmenti video che appaiono come forte evidenza di abilità da quelli che suggeriscono esecuzioni più deboli o imperfette. Ispirato dalle moderne reti basate sull’attenzione, il modello impara due “prototipi” interni: uno che cerca momenti di alta qualità e un altro che si concentra su quelli di bassa qualità. Durante l’elaborazione del video, ogni prototipo assegna pesi diversi ai segmenti, producendo due sommari complementari: uno costruito dai clip più validi e uno dai clip peggiori o meno informativi. Viene anche mantenuta una semplice media temporale come baseline neutra. Regole di addestramento speciali spingono le viste di alta e bassa qualità a discostarsi in modi utili e a focalizzarsi su differenti parti del video, invece di convergere sugli stessi pochi fotogrammi ovvi.
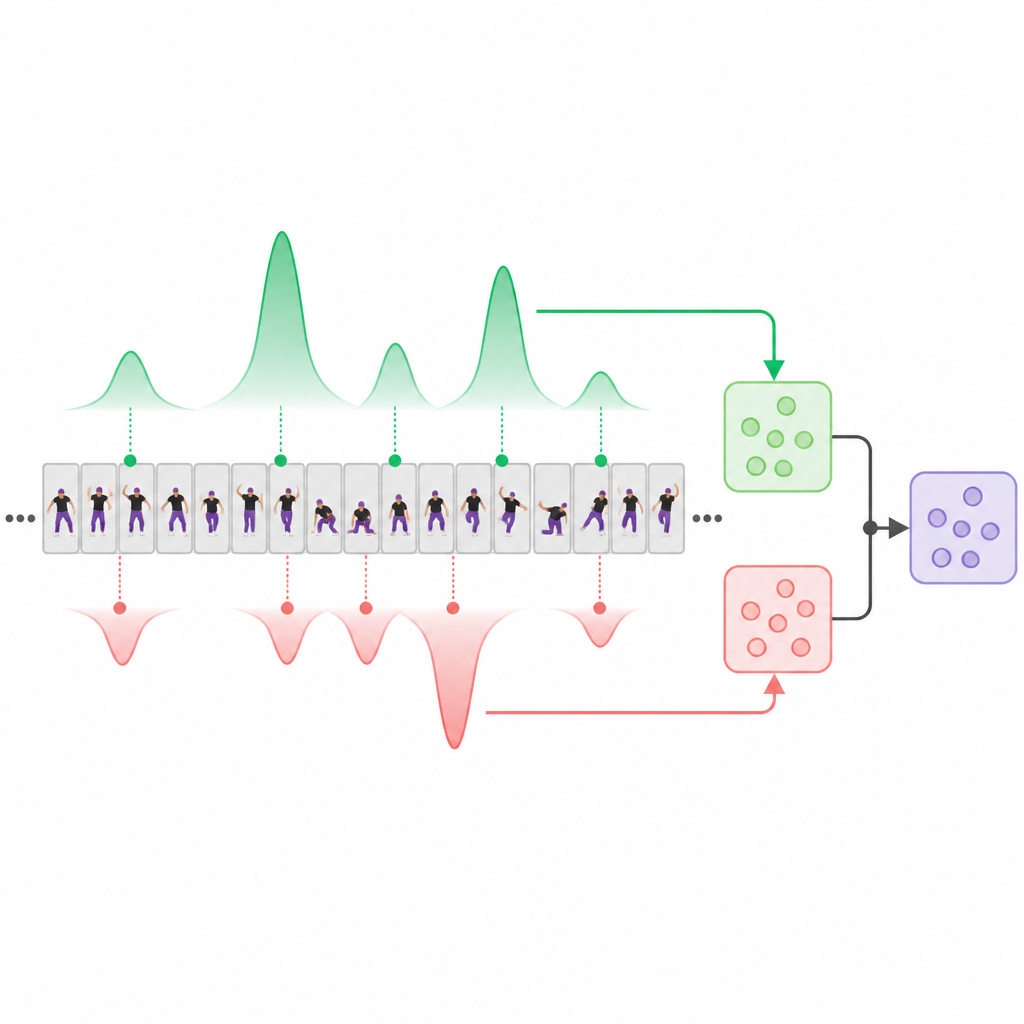
Imparare a classificare le performance osservando coppie
Piuttosto che affidarsi a punteggi numerici precisi assegnati da esperti umani, il sistema viene addestrato principalmente su confronti a coppie: dato due video, quale dei due performer ha mostrato complessivamente maggiore abilità? Per ogni coppia, il modello predice punteggi per i rami di alta qualità, bassa qualità e per la media, e viene penalizzato se sbaglia l’ordinamento o se i rami separati non risultano più discriminanti della semplice media. Termini di addestramento aggiuntivi incoraggiano le viste “buone” e “cattive” a enfatizzare segmenti temporali diversi. Una volta completato l’addestramento, il sistema può analizzare un singolo video nuovo e fornire un punteggio di qualità stabile, senza la necessità di vedere un video di riferimento affiancato.
Dalle battle di breakdance alla chirurgia e alle abilità quotidiane
Per testare l’approccio, gli autori hanno costruito un nuovo dataset di battle di breakdance di livello mondiale e hanno anche valutato il metodo su due raccolte esistenti di video lunghi di abilità: compiti quotidiani come disegnare, cucinare e annodare una cravatta, e attività chirurgiche e di motricità fine. In questi diversi contesti, il loro modello ha in genere eguagliato o superato l’accuratezza dei metodi di punta nel decidere quale dei due video mostra maggiore abilità. Le visualizzazioni delle mappe di attenzione interne mostrano che i rami di alta qualità tendono ad attivarsi attorno a mosse ben controllate e tecnicamente impegnative, mentre i rami di bassa qualità enfatizzano transizioni goffe o azioni incomplete. In termini chiari per un lettore non tecnico, il risultato principale è che questo sistema insegna ai computer non solo a riconoscere quale azione sta avvenendo, ma quanto bene viene eseguita, separando con cura le parti migliori e peggiori di una performance prima di combinarle in un punteggio finale interpretabile.
Citazione: Gao, L., Ma, Y., Bi, S. et al. Athlete action quality assessment based on transfer neural network quality score decoupling in complex sports scenarios. Sci Rep 16, 15795 (2026). https://doi.org/10.1038/s41598-026-43987-7
Parole chiave: valutazione della qualità dell’azione, analisi di video sportivi, breakdance, modelli basati sull’attenzione, valutazione delle abilità