Clear Sky Science · ru
Оценка качества действий спортсмена на основе декуплинга оценки качества в передающей нейросети в сложных спортивных сценариях
Почему важно умнее судить спортивные выступления
От олимпийских прыжков в воду до баттлов по брейкдансу — во многих видах спорта человеческим судьям приходится сводить сложные движения к одной оценке. Но длинные выступления неравномерны: одни моменты блистательны, другие неточны или служат заполнением. В этой работе исследуется, как искусственный интеллект может просматривать целые видеозаписи сложных выступлений, отбирать действительно значимые эпизоды и выдавать более последовательные, тонко градуированные оценки, которые могут помочь судьям, тренерам, врачам и обычным обучающимся.
Смотреть всё выступление, а не только хайлайты
Традиционные компьютерные системы, оценивающие спортивное мастерство, часто рассматривают весь видеоролик так, будто каждая секунда одинаково важна. Это предположение рушится в реальных соревнованиях. В брейкдансе, например, начальные шаги, синхронизированные с музыкой, важны меньше, чем сложные элементы на полу, фризы или мощные вращения позже. Существующие методы часто усредняют всё вместе, что скрывает как блестящие приёмы, так и критические ошибки. Авторы рассматривают это как общую проблему длинных обучающих видео: качество меняется со временем, и положительные и отрицательные свидетельства могут сосуществовать в одном выступлении. Их цель — построить систему, которая отделяет ключевые моменты от фоновой активности, что облегчает сравнение реального уровня выполнения у разных исполнителей.
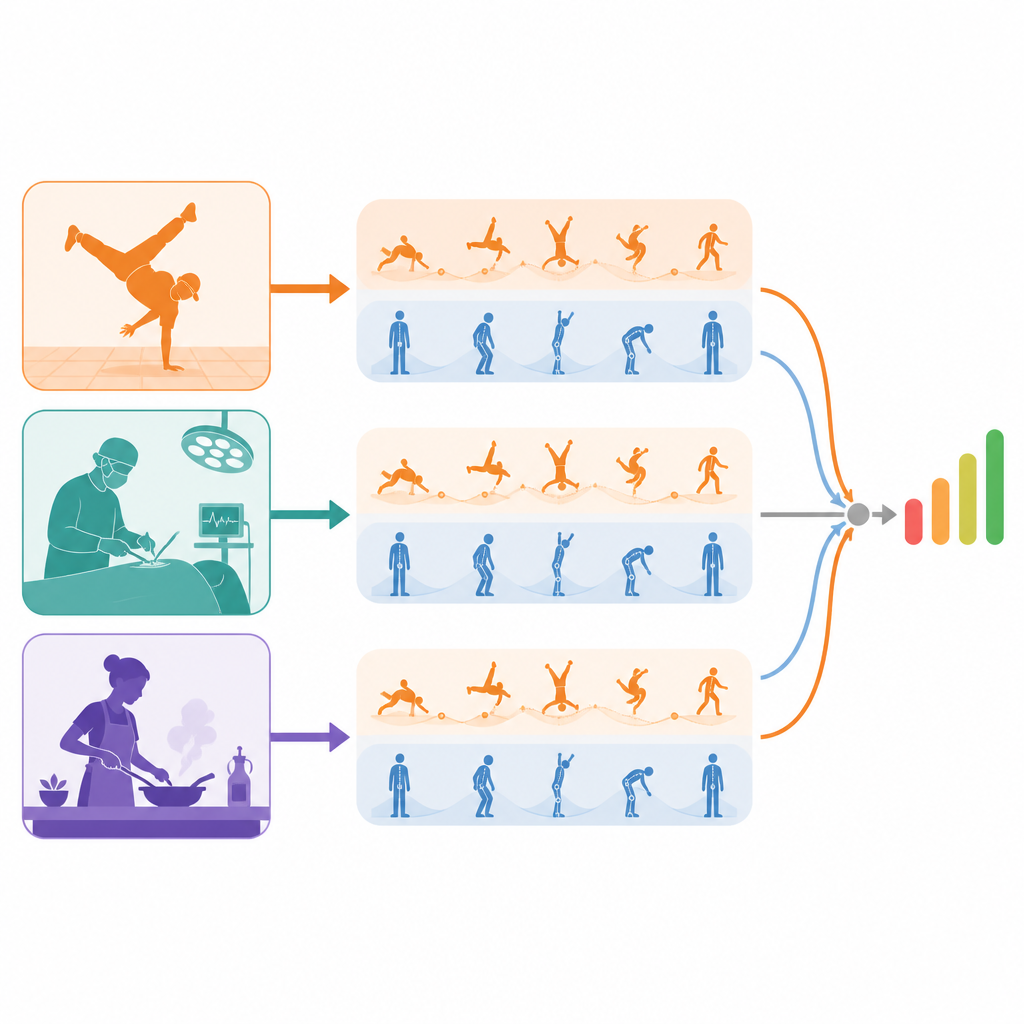
Два взгляда на одно и то же выступление
Предлагаемая модель рассматривает каждое видео через две отдельные призмы. Один «динамический» поток фокусируется на движении во времени, используя короткие клипы, фиксируя ритм, плавность и непрерывность. Другой «статический» поток анализирует отдельные кадры, улавливая позу, контроль тела и мелкие ошибки формы, появляющиеся мгновенно. Важно, что эти потоки не смешиваются на ранних этапах. Каждый из них сначала вырабатывает собственное представление о выступлении, что помогает не допустить, чтобы кратковременные ошибки позы заглушались длительными плавными эпизодами, или наоборот. Только после того, как каждый поток сформировал признаки, чувствительные к качеству, они объединяются для оценки итоговой оценки.
Отделение сильных приёмов от слабых
В основе системы лежит модуль «декуплинга оценок», который явно разделяет сегменты видео, являющиеся сильными свидетельствами мастерства, и те, что указывают на слабое или ошибочное выполнение. Вдохновлённая современными сетями с механизмом внимания, модель обучает два внутренних «прототипа»: один ищет высококачественные моменты, другой фокусируется на низкокачественных. По мере обработки видео каждый прототип присваивает разный вес разным сегментам, формируя два дополняющих друг друга сводных представления: одно — из лучших клипов, другое — из худших или наименее полезных. Также сохраняется простое усреднение по времени в качестве нейтральной базовой линии. Специальные правила обучения побуждают «хороший» и «плохой» представления расходиться в полезных аспектах и фокусироваться на разных частях видео, а не сходиться на одних и тех же очевидных кадрах.
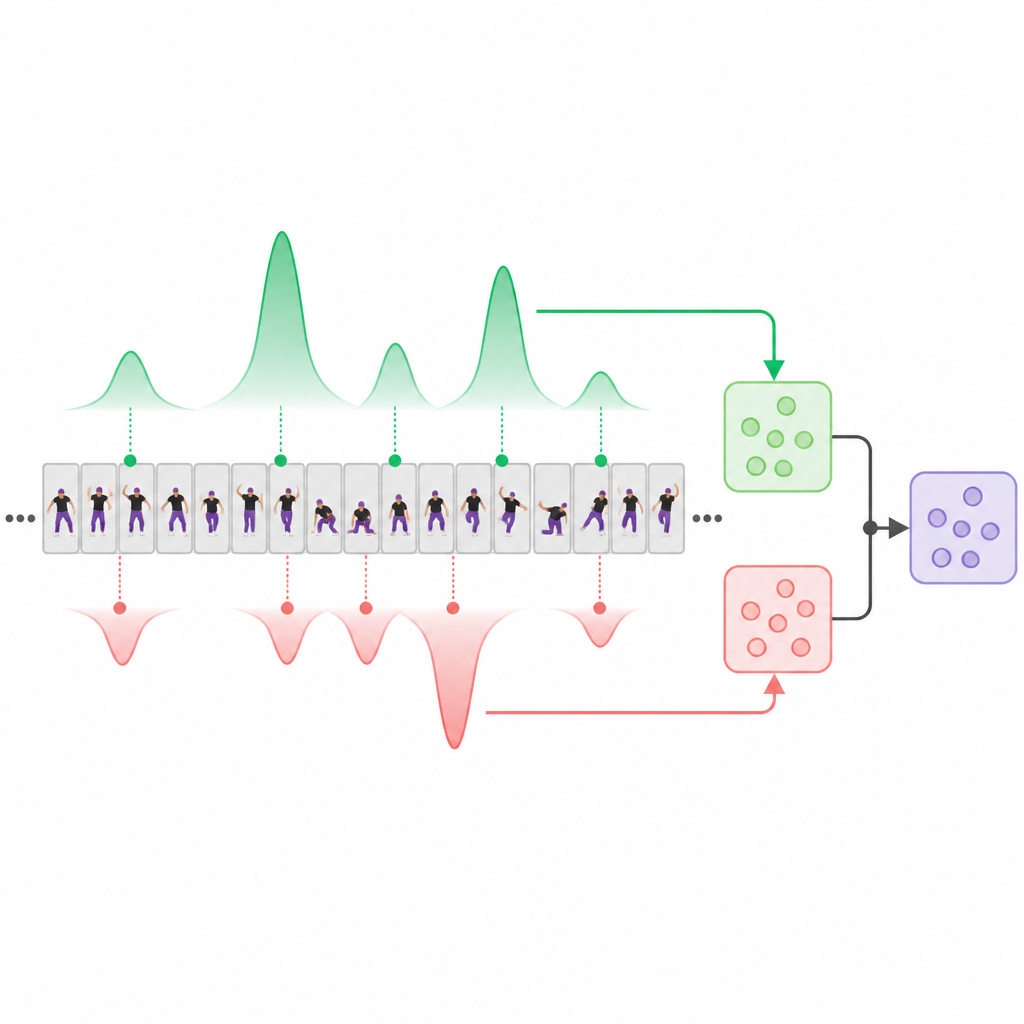
Обучение ранжированию выступлений по парам
Вместо того чтобы опираться на точные числовые оценки экспертов, система в основном обучается на парных сравнениях: из двух видео — чьё выступление в целом лучше? Для каждой пары модель предсказывает оценки для ветвей высокого качества, низкого качества и усреднённой ветви и получает штраф, если неправильно восстанавливает порядок или если разделённые ветви оказываются менее различимыми, чем простое усреднение. Дополнительные термы обучения поощряют «хороший» и «плохой» виды уделять внимание разным временным сегментам. После завершения обучения система может просмотреть одиночное новое видео и выдать одну стабильную оценку качества, без необходимости сравнивать его с эталонным роликом.
От брейкданс-баттлов до хирургии и повседневных навыков
Для проверки подхода авторы собрали новый датасет с мирового уровня баттлов по брейкдансу и также оценили метод на двух существующих коллекциях длинных обучающих видео: повседневных задачах (рисование, готовка, завязывание галстука) и хирургических и тонко-двигательных действиях. В этих разных условиях их модель, как правило, соответствовала или превосходила по точности ведущие методы при выборе того, какое из двух видео демонстрирует более высокий уровень мастерства. Визуализации внутренних карт внимания показывают, что ветви высокого качества обычно активируются вокруг хорошо контролируемых, технически сложных приёмов, тогда как ветви низкого качества выделяют неуклюжие переходы или незавершённые действия. Для неспециалиста ключевой вывод таков: эта система учит компьютеры не просто распознавать, какое действие выполняется, но и насколько хорошо оно выполнено, аккуратно отделяя лучшие и худшие части выступления перед их объединением в финальную, интерпретируемую оценку.
Цитирование: Gao, L., Ma, Y., Bi, S. et al. Athlete action quality assessment based on transfer neural network quality score decoupling in complex sports scenarios. Sci Rep 16, 15795 (2026). https://doi.org/10.1038/s41598-026-43987-7
Ключевые слова: оценка качества действий, анализ спортивных видео, брейкданс, модели на основе внимания, оценка навыков