Clear Sky Science · sv
Ett tvåstegsramverk för kostnadskänsligt prediktivt underhåll med djupinlärning, GANs och riskmedveten klustring
Att hålla fabrikerna igång smidigt
När en nyckelmaskin går sönder på en fullbelagd produktionslinje stannar allt: arbetare blir stående, leveranser försenas och reparationskostnaderna skjuter i höjden. Denna artikel undersöker ett smartare sätt att sköta industriell utrustning så att fabriker kan åtgärda problem innan de inträffar — utan att slösa pengar på onödiga serviceåtgärder. Med fokus på en verklig vattenbuteljeringsanläggning visar studien hur modern artificiell intelligens kan omvandla splittrade felregister till praktiska, kostnadsbesparande underhållsplaner.
Varför feldata är så svåra att få tag på
Vid första anblick kan det verka enkelt att ta reda på när en maskin kommer att gå sönder: titta bara på tidigare haverier. I verkligheten har fabriker ofta väldigt lite användbar data. Många komponenter går sönder bara ett fåtal gånger under flera år, vissa byts ut i förtid av säkerhetsskäl och register kan vara ofullständiga. Konventionella prediktiva system har svårt i en sådan miljö eftersom de behöver många exempel på haverier för att lära sig mönster. Författaren tar sig an den här databristen genom att använda en särskild typ av generativ modell som kan ”föreställa sig” realistiska felhistoriker för varje komponent och därigenom fylla i luckorna samtidigt som systemets verkliga beteende bevaras.
Lära maskiner att känna av slitage
Första steget i ramverket fokuserar på att uppskatta hur mycket liv som återstår i varje komponent — en mängd som informellt kallas "time to go" före fel. För varje maskin på buteljeringslinjen bygger studien en dedikerad djupinlärningsmodell som läser timme‑för‑timme‑data som linjehastighet, flaskstorlek och produktionsbortfall. Denna modell, utformad för att hantera sekvenser över tid, lär sig hur dessa mönster typiskt utvecklas när komponenten åldras. Den levererar sedan en löpande uppskattning av återstående liv för varje enhet. För att göra dessa uppskattningar mer stabila blandas de syntetiska felhistorikerna som genererats av den generativa modellen med de verkliga uppgifterna, vilket hjälper modellen att se ett bredare spektrum av sannolika slitage‑ och fel‑scenarier.
Göra prognoser till praktiska risksignaler
Råa uppskattningar av återstående liv är fortfarande för brusiga och osäkra för att basera kostsamma beslut på. För att tygla denna komplexitet passar författaren enkla statistiska former till varje komponents ström av predicerade återstående livsvärden. Istället för att försöka förutsäga den exakta dagen för ett fel används dessa former för att beräkna ett jämnt index av "hälsa" kontra "risk", skalat mellan säker drift och förestående haveri. Detta hälsa‑riskindex ger ett konsekvent sätt att jämföra mycket olika maskiner och att bedöma hur nära var och en är en farlig zon, även när deras faktiska tidsskalor och felmarginaler skiljer sig åt.
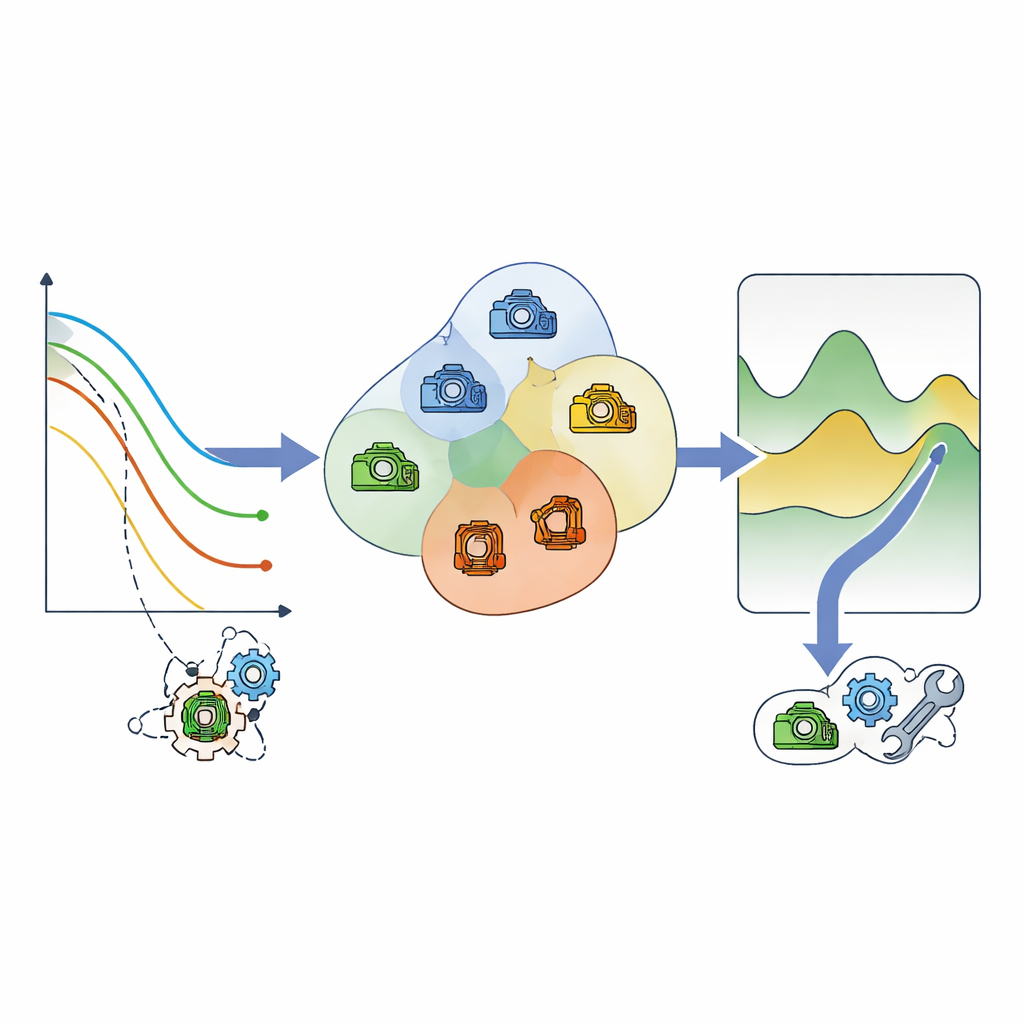
Gruppera maskiner för smart service
I det andra steget slutar ramverket att betrakta maskiner isolerat och frågar istället vilka komponenter som åldras på ungefär samma sätt. Med en riskbaserad syn på återstående liv grupperas komponenter som sannolikt behöver uppmärksamhet inom ett liknande tidsfönster i små kluster. En kostnadsmodell väger därefter tre faktorer för varje kluster: kostnaden för planerat underhåll, den mycket högre kostnaden för akutreparationer och produktionsbortfallet när saker går fel eller tas ur drift. Genom att skanna över möjliga servicetidpunkter hittar metoden den punkt där den förväntade totalkostnaden är lägst och planerar gemensamt underhåll för allt i det klustret kring den tidpunkten.
Vad detta betyder för verkligt underhåll
Tillämpat på buteljeringsanläggningen minskade tvåstegsramverket antalet överraskande haverier och sänkte normaliserade underhållskostnader jämfört med enkla tumregler, slumpmässig schemaläggning eller fasta tidsintervaller. Kanske viktigast visar studien att även med knapp och osäker data kan fabriker fortfarande fatta pålitliga, kostnadsmedvetna underhållsbeslut genom att kombinera dataaugmentering, riskbaserad gruppering av komponenter och noggrant kostnadsavvägande. I vardagliga termer erbjuder det ett sätt att laga rätt maskiner vid rätt tidpunkt — innan de går sönder — utan att spendera för mycket på onödiga reparationer.
Citering: Hakami, A. A two-stage framework for cost-sensitive predictive maintenance using deep learning, GANs, and risk-aware clustering. Sci Rep 16, 14442 (2026). https://doi.org/10.1038/s41598-026-42910-4
Nyckelord: prediktivt underhåll, industriell AI, utrustningspålitlighet, kostnadsmedveten planering, dataaugmentering