Clear Sky Science · ru
Двухэтапная схема для чувствительного к стоимости прогнозного обслуживания с использованием глубокого обучения, GAN и кластеризации с учётом риска
Сохраняя плавную работу заводов
Когда ключевая машина ломается на загруженной производственной линии, останавливается всё: рабочие остаются без дела, сроки срываются, а счета за ремонт растут. В этой статье рассматривается более умный подход к обслуживанию промышленного оборудования, который позволяет ремонтировать его до отказа — не тратя деньги на лишние настройки. На примере реального завода по розливу воды исследование показывает, как современные методы искусственного интеллекта могут превратить разрозненные записи об отказах в практичные и экономящие средства планы обслуживания.
Почему данные об отказах так сложно получить
На первый взгляд может показаться, что спрогнозировать поломку машины просто: достаточно посмотреть прошлые поломки. На практике же на заводах часто очень мало полезных данных. Многие детали выходят из строя всего несколько раз за несколько лет, некоторые заменяют преждевременно из соображений безопасности, а записи могут быть неполными. Традиционные прогнозные системы затрудняются в таких условиях, потому что им требуется множество примеров отказов для обучения. Автор решает проблему нехватки данных с помощью специального типа генеративной модели, которая «представляет» правдоподобные истории отказов для каждой детали, фактически заполняя пробелы при сохранении поведения реальной системы.
Обучение моделей чувствовать износ
Первый этап схемы направлен на оценку оставшегося ресурса каждой детали — величины, неформально называемой «время до отказа». Для каждой машины на линии розлива в исследовании строят отдельную модель глубокого обучения, которая анализирует покадровые (по часам) записи — скорость линии, размер бутылки, потери в производстве и т. п. Эта модель, спроектированная для работы с временными последовательностями, учится тому, как такие показатели обычно изменяются по мере старения детали. В результате она выдаёт текущую оценку оставшегося ресурса для каждого узла. Чтобы сделать эти оценки более устойчивыми, синтетические истории отказов, сгенерированные генеративной моделью, смешиваются с реальными данными, что помогает модели увидеть более широкий спектр правдоподобных сценариев износа.
Преобразование прогнозов в практические сигналы риска
Сырые оценки оставшегося ресурса всё ещё слишком шумны и неопределённы, чтобы на их основе принимать дорогостоящие решения. Чтобы упростить эту сложность, автор подбирает простые статистические формы к каждому потоку предсказанных значений оставшегося ресурса. Вместо попытки предсказать точный день отказа эти формы используются для вычисления сглаженного индекса «здоровья» против «риска», нормированного между безопасной эксплуатацией и неминуемым выходом из строя. Этот индекс здоровья‑риска даёт последовательный способ сравнивать очень разные машины и оценивать, насколько близка каждая из них к опасной зоне, даже если их временные шкалы и погрешности различаются.
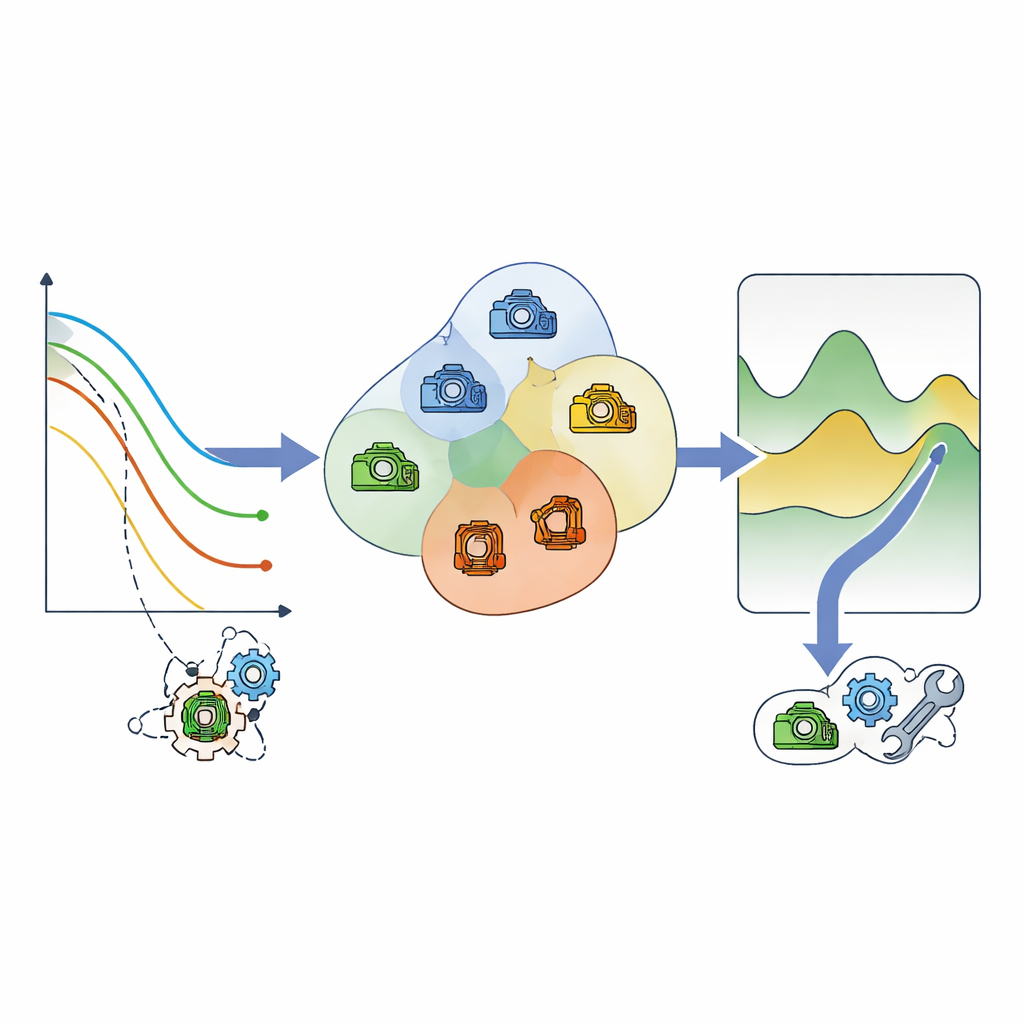
Группировка машин для умного обслуживания
На втором этапе схема перестаёт рассматривать машины по отдельности и спрашивает, какие компоненты стареют примерно одинаково. Используя видение оставшегося ресурса на основе риска, компоненты, которым, скорее всего, потребуется внимание в близкие сроки, группируются в небольшие кластеры. Модель затрат затем взвешивает три фактора для каждого кластера: стоимость планового обслуживания, значительно более высокую стоимость аварийного ремонта и потери производства, когда что‑то ломается или отключается. Просматривая возможные моменты обслуживания, метод находит точку, в которой ожидаемые совокупные затраты минимальны, и планирует совместное обслуживание всех элементов кластера вблизи этой точки.
Что это даёт для реального обслуживания
Применённая на заводе по розливу, двухэтапная схема сократила количество неожиданных поломок и снизила нормированные затраты на обслуживание по сравнению с простыми эвристиками, случайным планированием или политиками с фиксированным интервалом. Возможно, что важнее всего — исследование показывает, что даже при скудных и неопределённых данных заводы всё ещё могут принимать надёжные, ориентированные на затраты решения по обслуживанию, сочетая увеличение данных, группировку компонентов по риску и тщательное взвешивание затрат. Проще говоря, это способ ремонтировать нужные машины в нужное время — до того, как они сломаются — без лишних расходов на ненужные ремонты.
Цитирование: Hakami, A. A two-stage framework for cost-sensitive predictive maintenance using deep learning, GANs, and risk-aware clustering. Sci Rep 16, 14442 (2026). https://doi.org/10.1038/s41598-026-42910-4
Ключевые слова: прогнозное обслуживание, промышленный ИИ, надёжность оборудования, планирование с учётом затрат, увеличение данных