Clear Sky Science · es
Un marco de dos etapas para el mantenimiento predictivo sensible al coste mediante aprendizaje profundo, GANs y agrupamiento consciente del riesgo
Mantener las fábricas funcionando sin contratiempos
Cuando una máquina clave se avería en una línea de producción ocupada, todo se detiene: los operarios quedan inactivos, los pedidos se retrasan y las facturas de reparación se disparan. Este artículo explora una forma más inteligente de cuidar el equipo industrial para que las fábricas puedan reparar las cosas antes de que fallen, sin malgastar dinero en ajustes innecesarios. Centrándose en una planta embotelladora real, el estudio muestra cómo la inteligencia artificial moderna puede convertir registros dispersos de fallos en planes de mantenimiento prácticos que ahorran dinero.
Por qué los datos de fallos son tan difíciles de obtener
A primera vista, podría parecer fácil aprender cuándo se romperá una máquina: basta con mirar las averías pasadas. En realidad, las fábricas a menudo tienen muy pocos datos útiles. Muchas piezas fallan solo unas pocas veces en varios años, algunas se sustituyen de forma preventiva por seguridad y los registros pueden ser incompletos. Los sistemas predictivos convencionales tienen dificultades en este escenario porque necesitan muchos ejemplos de averías para aprender patrones. El autor aborda esta escasez de datos utilizando un tipo especial de modelo generativo que puede “imaginar” historiales de fallos realistas para cada componente, llenando así las lagunas mientras conserva el comportamiento del sistema real.
Enseñar a las máquinas a detectar el desgaste
La primera etapa del marco se centra en estimar cuánto vida le queda a cada componente —una cantidad conocida informalmente como “tiempo restante” antes de la falla. Para cada máquina de la línea de embotellado, el estudio construye un modelo de aprendizaje profundo dedicado que lee registros hora por hora, como la velocidad de la línea, el tamaño de la botella y la pérdida de producción. Este modelo, diseñado para manejar secuencias temporales, aprende cómo evolucionan normalmente estos patrones a medida que el componente envejece. Luego produce una estimación continua de la vida restante para cada unidad. Para hacer estas estimaciones más estables, los historiales de fallos sintéticos generados por el modelo generativo se mezclan con los datos reales, lo que ayuda al aprendiz a ver una mayor variedad de escenarios plausibles de desgaste.
Convertir las predicciones en señales de riesgo prácticas
Las estimaciones sin procesar de la vida restante siguen siendo demasiado ruidosas e inciertas para tomar decisiones costosas. Para domar esta complejidad, el autor ajusta formas estadísticas simples a la serie de valores predichos de vida restante de cada componente. En lugar de intentar pronosticar el día exacto de la falla, estas formas se utilizan para calcular un índice suave de “salud” frente a “riesgo”, escalado entre operación segura e inminente avería. Este índice salud‑riesgo proporciona una forma consistente de comparar máquinas muy distintas y de evaluar qué tan cerca está cada una de una zona peligrosa, incluso cuando sus escalas temporales y márgenes de error difieren.
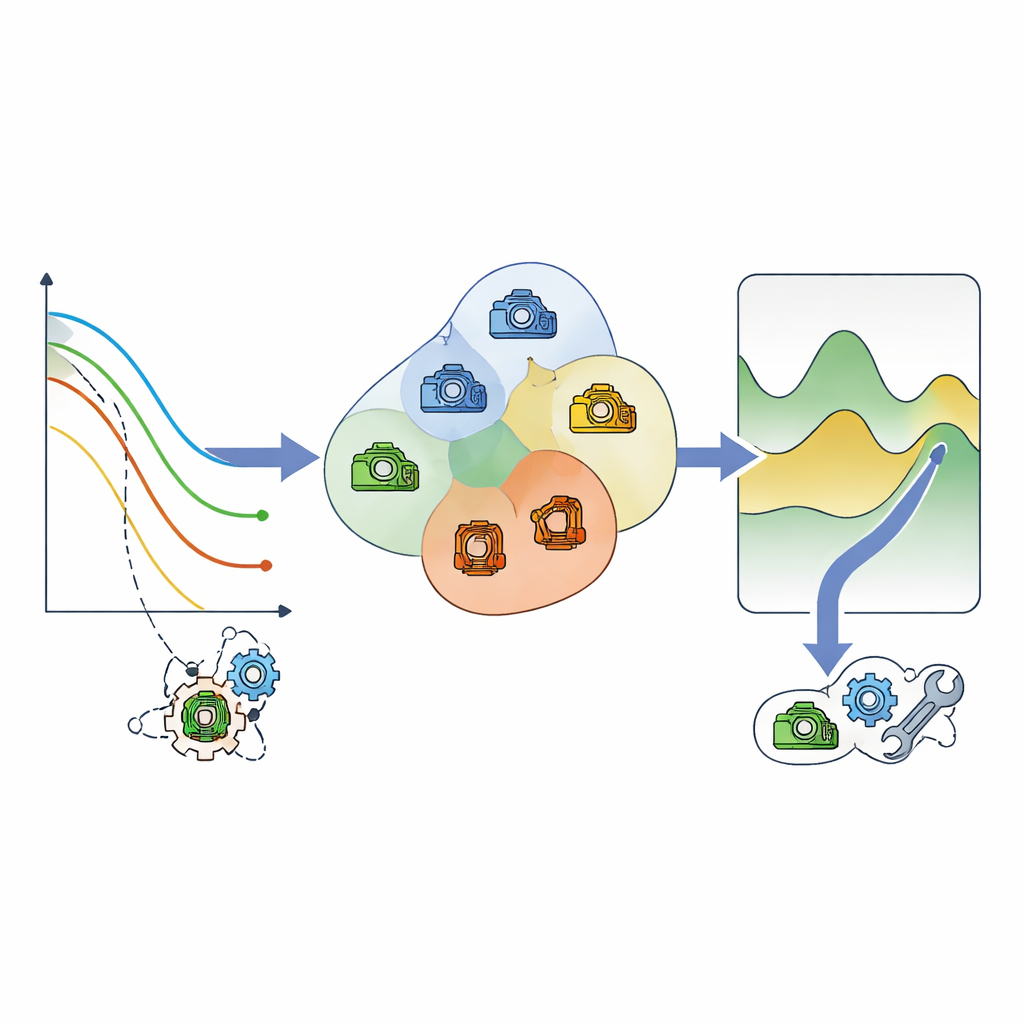
Agrupar máquinas para un servicio inteligente
En la segunda etapa, el marco deja de mirar las máquinas aisladamente y en su lugar pregunta qué componentes envejecen de manera aproximadamente similar. Utilizando la visión basada en riesgo de la vida restante, se agrupan en pequeños clústeres los componentes que probablemente necesitarán atención en una ventana temporal similar. Un modelo de costes pondera entonces tres factores por cada clúster: el precio del servicio planificado, el coste mucho mayor de las reparaciones de emergencia y la pérdida de producción cuando algo falla o se toma fuera de servicio. Al explorar posibles momentos de servicio, el método encuentra el punto en el que el coste esperado total es más bajo y programa el mantenimiento conjunto de todo lo que hay en ese clúster alrededor de ese punto.
Qué significa esto para el mantenimiento en el mundo real
Aplicado a la planta embotelladora, el marco de dos etapas redujo el número de averías inesperadas y disminuyó los costes de mantenimiento normalizados en comparación con reglas empíricas simples, programación aleatoria o políticas de tiempo fijo. Quizá lo más importante, el estudio muestra que incluso con datos escasos e inciertos, las fábricas aún pueden tomar decisiones de mantenimiento fiables y conscientes de los costes combinando aumento de datos, agrupamiento de componentes basado en riesgo y un cuidadoso equilibrio de costes. En términos cotidianos, ofrece una forma de reparar las máquinas adecuadas en el momento adecuado —antes de que fallen— sin gastar de más en reparaciones innecesarias.
Cita: Hakami, A. A two-stage framework for cost-sensitive predictive maintenance using deep learning, GANs, and risk-aware clustering. Sci Rep 16, 14442 (2026). https://doi.org/10.1038/s41598-026-42910-4
Palabras clave: mantenimiento predictivo, IA industrial, fiabilidad de equipos, planificación con conciencia de costes, aumento de datos