Clear Sky Science · nl
Een tweefasig kader voor kostenbewuste voorspellende onderhoudsplanning met deep learning, GANs en risicobewuste clustering
Fabrieken soepel draaiende houden
Wanneer een cruciale machine uitvalt op een drukke productielijn, stopt alles: werknemers staan stil, bestellingen lopen vertraging op en reparatiekosten rijzen de pan uit. Dit artikel onderzoekt een slimmer manier om industriële apparatuur te onderhouden, zodat fabrieken kunnen repareren voordat onderdelen falen—zonder geld te verspillen aan onnodige onderhoudsbeurten. Met een casus in een echte waterfleslijn laat de studie zien hoe moderne kunstmatige intelligentie verspreide storingsgegevens kan omzetten in praktische, kostenbesparende onderhoudsplannen.
Waarom faaldata zo moeilijk te verkrijgen zijn
Op het eerste gezicht lijkt het eenvoudig te voorspellen wanneer een machine faalt: kijk naar eerdere storingen. In de praktijk beschikken fabrieken echter vaak over zeer weinig bruikbare data. Veel onderdelen falen slechts een paar keer over meerdere jaren, sommige worden vroegtijdig vervangen uit veiligheidsredenen en registraties kunnen onvolledig zijn. Conventionele voorspellende systemen hebben het in deze situatie moeilijk omdat ze veel voorbeelden van storingen nodig hebben om patronen te leren. De auteur pakt dit datatekort aan door een speciaal type generatief model te gebruiken dat realistische faalgeschiedenissen voor elk onderdeel kan “verbeelden”, waardoor de gaten gevuld worden zonder het gedrag van het echte systeem te vervormen.
Machines leren slijtage te detecteren
De eerste fase van het kader richt zich op het inschatten hoeveel levensduur elk onderdeel nog heeft—een hoeveelheid die informeel bekendstaat als de resterende tijd tot falen. Voor elke machine op de bottellijn bouwt de studie een specifiek deep learning-model dat uur-tot-uur gegevens leest zoals liniesnelheid, flesgrootte en productieverlies. Dit model, ontworpen om sequenties in de tijd te verwerken, leert hoe deze patronen doorgaans evolueren naarmate het onderdeel ouder wordt. Het levert vervolgens een doorlopende schatting van de resterende levensduur voor elk exemplaar. Om deze schattingen stabieler te maken worden de synthetische faalgeschiedenissen van het generatieve model gemengd met de echte data, waardoor de leerder een breder scala aan plausibele slijtage‑scenario’s te zien krijgt.
Voorspellingen omzetten in praktische risicosignalen
Ruwe schattingen van resterende levensduur zijn nog steeds te ruw en onzeker om dure beslissingen op te baseren. Om deze complexiteit te temmen, past de auteur eenvoudige statistische vormen aan op de stroom van voorspelde resterende levensduurwaarden per onderdeel. In plaats van te proberen de exacte faaldag te voorspellen, worden deze vormen gebruikt om een vloeiende index van “gezondheid” versus “risico” te berekenen, geschaald tussen veilig bedrijf en dreigende uitval. Deze gezondheid‑risico-index biedt een consistente manier om zeer verschillende machines met elkaar te vergelijken en in te schatten hoe dicht elk exemplaar bij een gevaarlijke zone staat, zelfs wanneer hun tijdschalen en foutmarges verschillen.
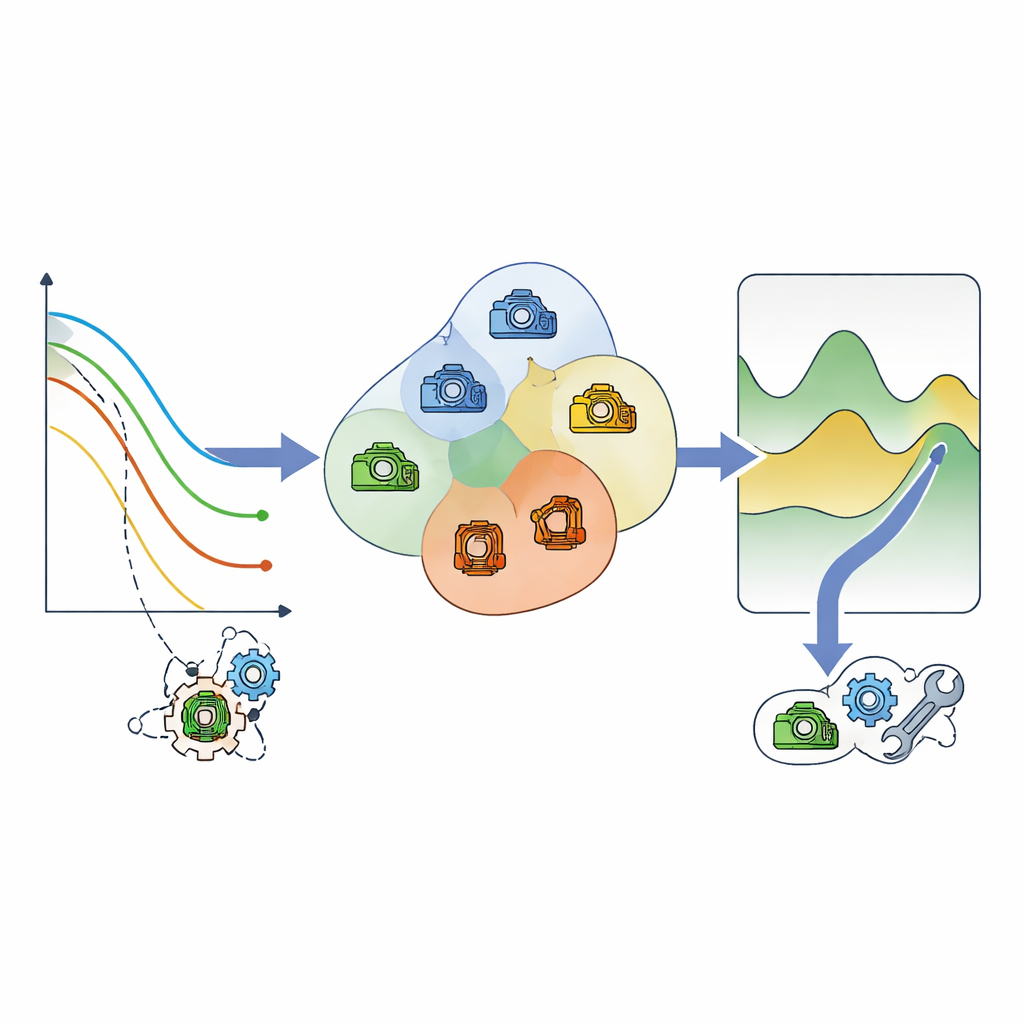
Machines groeperen voor slim onderhoud
In de tweede fase kijkt het kader niet langer naar machines afzonderlijk, maar vraagt welke componenten ongeveer op dezelfde manier verouderen. Met de risicogebaseerde kijk op resterende levensduur worden componenten die waarschijnlijk rond hetzelfde tijdvenster aandacht nodig hebben in kleine clusters samengebracht. Een kostmodel weegt vervolgens drie factoren voor elke cluster: de prijs van gepland onderhoud, de veel hogere kosten van noodreparaties, en het productieverlies wanneer iets misgaat of offline wordt gehaald. Door mogelijke onderhoudstijdstippen te doorlopen, vindt de methode het punt waarop de verwachte totale kosten het laagst zijn, en plant gezamenlijk onderhoud voor alles in die cluster rond dat punt.
Wat dit betekent voor onderhoud in de praktijk
Toegepast op de bottellijn verlaagde het tweefasige kader het aantal onverwachte storingen en verminderde het genormaliseerde onderhoudskosten vergeleken met eenvoudige vuistregels, willekeurige planning of beleid met vaste intervallen. Misschien nog belangrijker toont de studie aan dat zelfs met schaarse en onzekere data fabrieken betrouwbare, kostenbewuste onderhoudskeuzes kunnen maken door data‑augmentatie, risicogebaseerde groepering van componenten en zorgvuldige kostenafweging te combineren. In praktische termen biedt het een manier om de juiste machines op het juiste moment te repareren—voordat ze falen—zonder te veel uit te geven aan onnodige reparaties.
Bronvermelding: Hakami, A. A two-stage framework for cost-sensitive predictive maintenance using deep learning, GANs, and risk-aware clustering. Sci Rep 16, 14442 (2026). https://doi.org/10.1038/s41598-026-42910-4
Trefwoorden: voorspellend onderhoud, industriële AI, apparaatstabiliteit, kostengevoelige planning, data-augmentatie