Clear Sky Science · sv
Design av en hybrid kvantmaskininlärningsarkitektur och analys av kvantbrusets effekter
Varför det kan hjälpa att lägga till brus i kvantdatorer
Dagens kvantdatorer är i teorin kraftfulla men i praktiken röriga: deras känsliga kvantbitar störs ständigt av brus, vilket vanligtvis försämrar prestanda. Den här studien ställer en överraskande fråga: kan en del av det bruset faktiskt vändas till en fördel? Författarna utformar ett hybridssystem som blandar en liten kvantkrets med ett konventionellt neuralt nätverk och testar hur realistiska nivåer av brus påverkar dess förmåga att upptäcka bröstcancer från medicinska data.
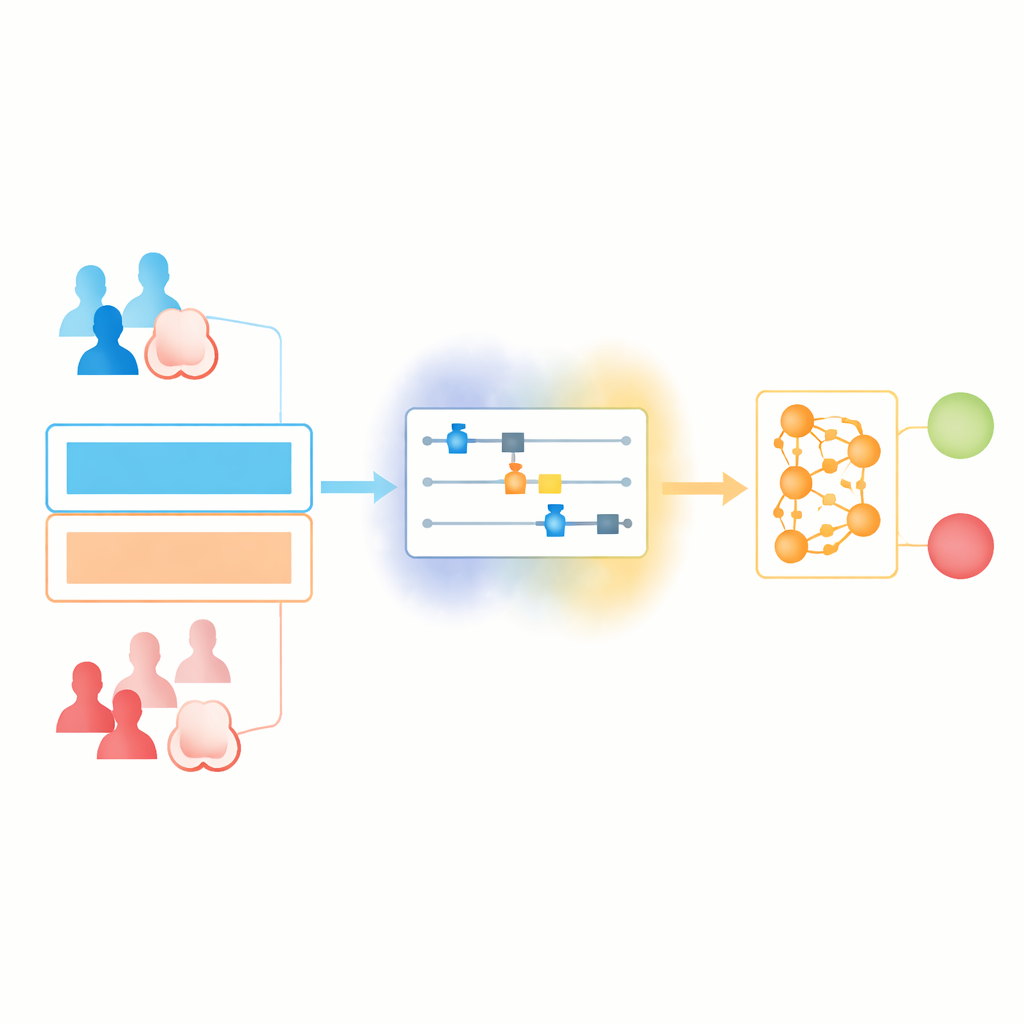
Att blanda två världar: kvant- och klassisk inlärning
Forskarna bygger en ”hybrid” inlärningspipeline som låter kvant- respektive klassiska delar göra det de är bäst på. Först rengörs och normaliseras vanliga journaldata så att varje siffra passar inom ett fast intervall. Dessa värden matas sedan in i en kompakt kvantkrets, där varje funktion kodas på en uppsättning qubits med noggrant valda rotationer. Qubits kopplas kortvarigt samman (entangles) och transformeras, för att sedan mätas och ge upphov till en ny uppsättning värden. Dessa blir indata till ett standardneuronätverk som gör den slutliga ja-eller-nej-bedömningen om cancer.
Att lära en kvantmodell i en bullrig värld
I stället för att låtsas att kvanthårdvaran är perfekt, bygger teamet uttryckligen in brus i träningsprocessen. De använder en högfidelitetsemulator för supraledande kvantenheter och injicerar realistiska fel vid tre nyckelsteg: när qubits initieras, när kvantgrindar appliceras och när mätningar utförs. Brusets styrkor hämtas från kalibreringsdata som representerar nuvarande enheter, ett ambitiöst nära‑framtidsmål och en framtida ”önskelista” med ännu lägre felnivåer. Detta låter dem utforska hur samma inlärningsarkitektur beter sig i takt med att kvanttekniken gradvis förbättras.
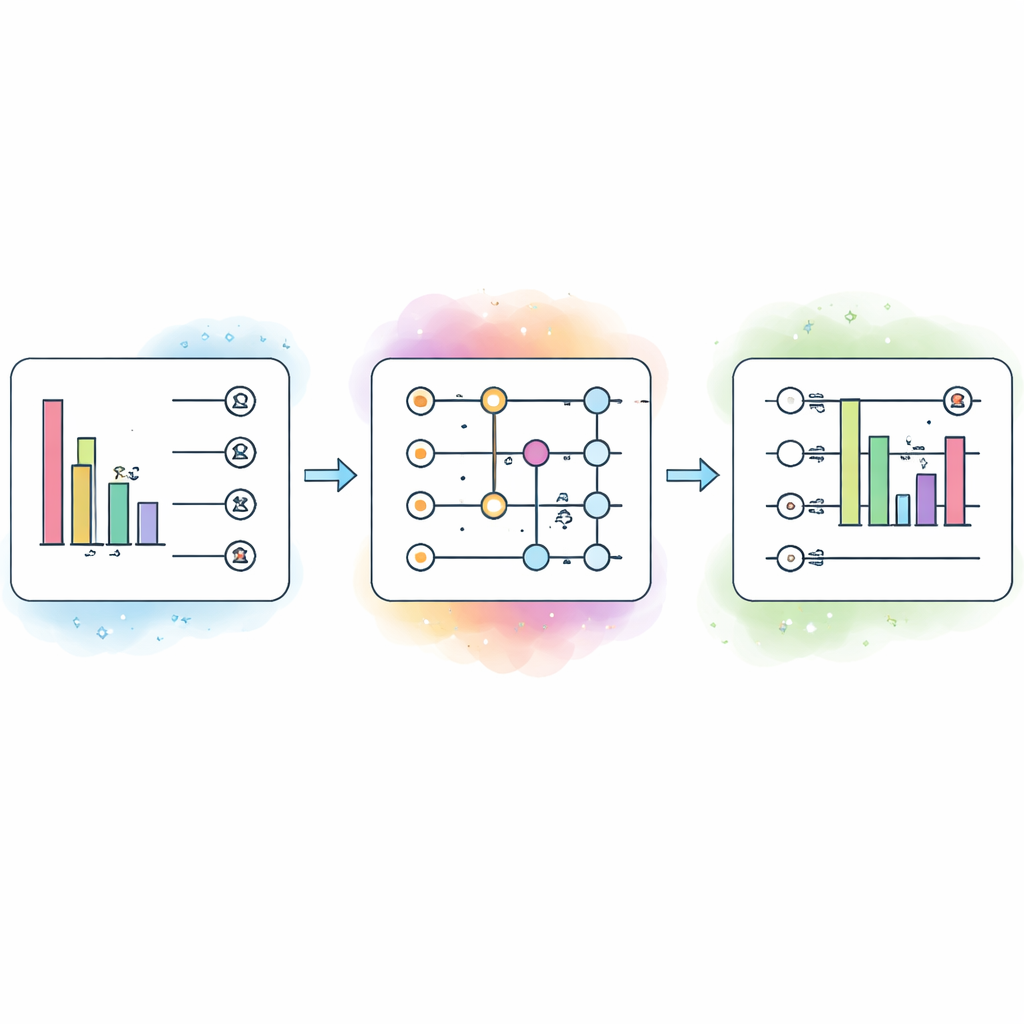
Bröstcancerdata som ett verkligt testfält
För att se om denna uppsättning är användbar i praktiken testar författarna den på tre öppna bröstcancer‑dataset som skiljer sig åt i storlek och svårighetsgrad. Ett innehåller relativt begränsad information, ett annat innehåller många överlappande eller redundanta signaler och det tredje är väl lämpat för att lära tydliga mönster. För varje dataset varierar de antalet qubits och mängden brus, och följer hur noggrannhet och träningstid förändras. För att hålla jämförelsen rättvis utgår de från en gemensam basdesign och justerar sedan systematiskt endast kvantstorleken och klassiska hyperparametrar som inlärningshastighet, antal lager och aktiveringsfunktioner.
När färre qubits — och mer brus — räcker
Resultaten utmanar intuitionen att fler qubits och mindre brus alltid ger bättre modeller. I flera fall når de bästa bullriga konfigurationerna i princip samma noggrannhet som de idealiserade, brusfria versionerna samtidigt som de använder färre qubits. Till exempel, beroende på dataset, nås topprestanda med så få som två till sju qubits när realistiskt brus inkluderas, jämfört med större kvantkretsar i det brusfria fallet. Eftersom kostnaden för simulering och, så småningom, faktisk körning växer snabbt med varje extra qubit, översätts denna reducering till stora besparingar i träningstid — hastighetsökningar från cirka 1,6 gånger upp till över 4 gånger — utan att offra meningsfull prediktiv kraft.
Brus som en inbyggd skyddsräls mot överanpassning
När författarna studerar hur tränings‑ och valideringsfel utvecklas finner de att helt brusfria kvantlager tenderar att överanpassa: de lär sig träningsdatans egenheter alltför väl och generaliserar dåligt. När måttligt brus är närvarande uppnår modellerna ofta något högre valideringsnoggrannhet och mer stabila förlustkurvor, särskilt för de bäst avstämda brusnivåerna. I praktiken beter sig kvantfelen som en form av regularisering som är välkänd inom klassisk djupinlärning, som dropout, och styr systemet bort från spröda lösningar mot enklare, mer robusta arkitekturer.
Vad detta betyder för kvantinlärningens framtid
För en icke‑specialist är huvudbudskapet att dagens ofullkomliga kvantmaskiner kanske redan kan vara användbara partner åt klassisk AI, särskilt när deras brister behandlas som en del av designen snarare än som något besvärligt att ignorera. Det här arbetet visar att en omsorgsfullt framtagen hybridmodell kan behålla medicinsk prediktionsnoggrannhet nästan oförändrad samtidigt som den använder färre kvantresurser och tränar mycket snabbare under realistiskt brus. Istället för att vänta på perfekta, tysta kvanthårdvaror kan forskare kanske utnyttja måttligt brus som en nyttig ingrediens, som guidar mot slankare modeller som är lättare att träna och distribuera i verkliga tillämpningar.
Citering: Bravo-Montes, J.A., Martín-Toledano, A., Velasco-Gallego, C. et al. Design of a hybrid quantum machine learning architecture and analysis of quantum noise effects. Sci Rep 16, 13496 (2026). https://doi.org/10.1038/s41598-026-42216-5
Nyckelord: kvantmaskininlärning, hybrida neurala nätverk, kvantbrus, bröstcancerdetektion, noisy intermediate-scale quantum