Clear Sky Science · de
Design einer hybriden Quanten‑Machine‑Learning‑Architektur und Analyse der Auswirkungen von Quantenrauschen
Warum das Hinzufügen von Rauschen zu Quantencomputern nützlich sein könnte
Die heutigen Quantencomputer sind theoretisch leistungsfähig, in der Praxis jedoch fehleranfällig: ihre empfindlichen Qubits werden ständig durch Rauschen gestört, was meist die Leistung beeinträchtigt. Diese Studie stellt eine überraschende Frage: Kann sich ein Teil dieses Rauschens tatsächlich als Vorteil nutzen lassen? Die Autoren entwerfen ein hybrides System, das einen kleinen Quantenschaltkreis mit einem herkömmlichen neuronalen Netz kombiniert, und prüfen, wie realistische Rauschpegel seine Fähigkeit beeinflussen, Brustkrebs aus medizinischen Daten zu erkennen.
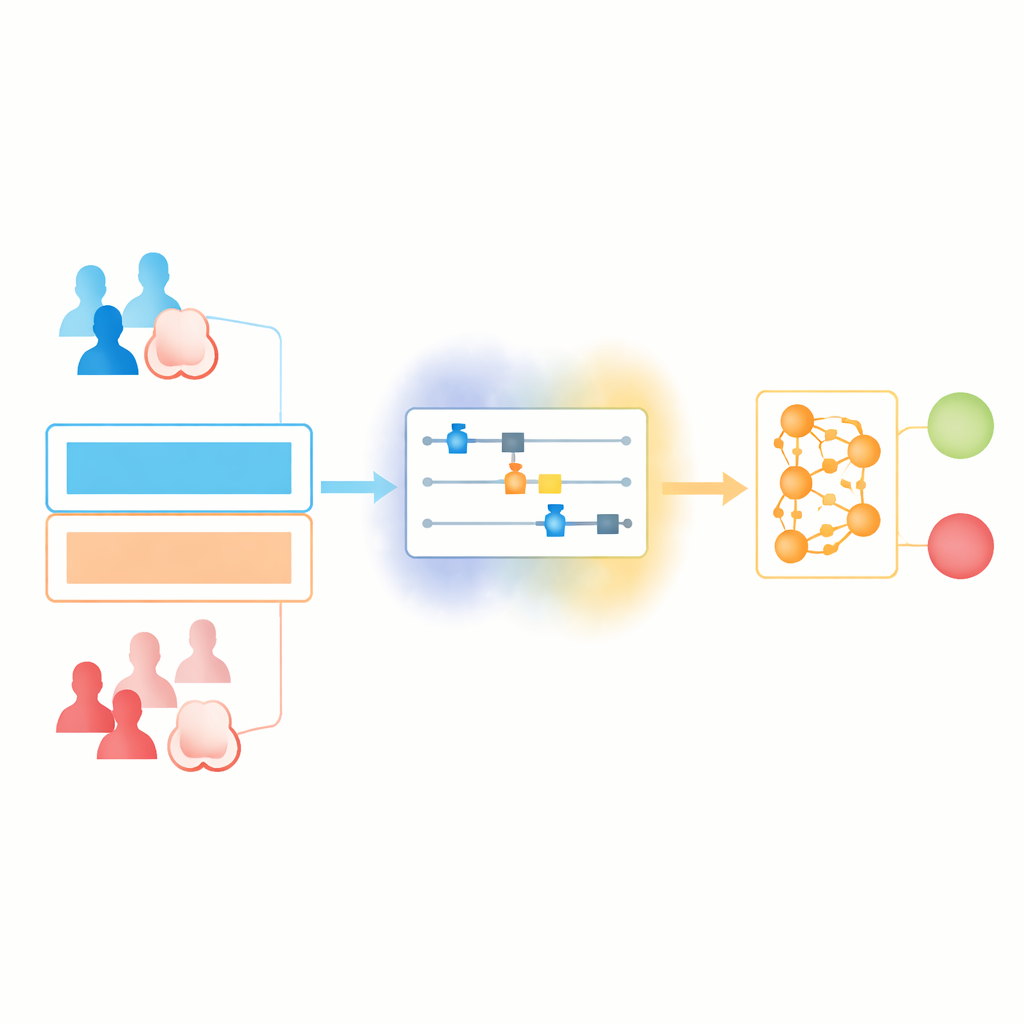
Die Verschmelzung zweier Welten: quanten- und klassisches Lernen
Die Forschenden bauen eine „hybride“ Lern-Pipeline, in der der Quanten‑ und der klassische Teil jeweils das tun, was sie am besten können. Zuerst werden gewöhnliche medizinische Datensätze bereinigt und normalisiert, sodass alle Werte in einem festen Bereich liegen. Diese Zahlen werden dann in einen kompakten Quantenschaltkreis eingespeist, wobei jede Merkmalskomponente auf eine Gruppe von Qubits mittels sorgfältig gewählter Rotationen kodiert wird. Die Qubits werden kurzzeitig verschränkt und transformiert, dann gemessen, um einen neuen Satz von Zahlen zu erzeugen. Diese dienen als Eingabe für ein Standard‑Neuronales Netz, das die endgültige Ja‑/Nein‑Vorhersage bezüglich Krebs trifft.
Ein Quantenmodell in einer verrauschten Welt trainieren
Anstatt so zu tun, als sei die Quantenhardware perfekt, bauen die Forschenden Rauschen explizit in den Trainingsprozess ein. Sie verwenden einen hochtreuen Emulator für supraleitende Quantengeräte und injizieren realistische Fehler in drei entscheidenden Phasen: beim Initialisieren der Qubits, beim Anwenden von Quanten‑Gattern und bei den Messungen. Die Rauschstärken stammen aus Kalibrierungsdaten, die aktuelle Geräte, ein ehrgeiziges kurzfristiges Ziel und eine zukünftige „Wunschliste“ mit noch geringeren Fehlerraten repräsentieren. So können sie untersuchen, wie sich dieselbe Lernarchitektur verhält, während sich die Quantentechnologie schrittweise verbessert.
Brustkrebs‑Daten als Testfeld aus der Praxis
Um zu prüfen, ob dieses Setup in der Praxis nützlich ist, testen die Autoren es an drei öffentlichen Brustkrebs‑Datensätzen, die sich in Größe und Schwierigkeit unterscheiden. Einer enthält relativ begrenzte Informationen, ein anderer viele überlappende oder redundante Signale, und der dritte eignet sich gut zum Erlernen klarer Muster. Für jeden Datensatz variieren sie die Anzahl der Qubits und die Rauschstärke und verfolgen, wie sich Genauigkeit und Trainingszeit ändern. Um den Vergleich fair zu halten, beginnen sie mit einem gemeinsamen Basisdesign und passen dann systematisch nur die Quantengröße und klassische Hyperparameter wie Lernrate, Anzahl der Schichten und Aktivierungsfunktionen an.
Wenn weniger Qubits — und mehr Rauschen — ausreichen
Die Ergebnisse widersprechen der Intuition, dass immer mehr Qubits und weniger Rauschen bessere Modelle ergeben. In mehreren Fällen erreichen die besten verrauschten Konfigurationen praktisch dieselbe Genauigkeit wie die idealisierten, rauschfreien Varianten, während sie weniger Qubits verwenden. Beispielsweise wird je nach Datensatz die Spitzenleistung bereits mit nur zwei bis sieben Qubits erreicht, wenn realistisches Rauschen berücksichtigt wird, verglichen mit größeren Quantenschaltkreisen im rauschfreien Fall. Da die Kosten für Simulation und schließlich die reale Ausführung mit jedem zusätzlichen Qubit stark ansteigen, führt diese Reduktion zu erheblichen Einsparungen bei der Trainingszeit — Beschleunigungen von etwa dem 1,6‑fachen bis über dem 4‑fachen, ohne dass die aussagekräftige Vorhersagekraft leidet.
Rauschen als eingebauter Schutz gegen Overfitting
Bei genauerer Betrachtung der Entwicklung von Trainings‑ und Validierungsfehlern stellen die Autoren fest, dass vollständig rauschfreie Quanten‑Schichten dazu neigen zu überanpassen: Sie lernen die Besonderheiten der Trainingsdaten zu genau und können nicht gut generalisieren. Bei moderatem Rauschen erzielen die Modelle oft etwas höhere Validierungsgenauigkeit und stabilere Loss‑Verläufe, vor allem bei optimal abgestimmten Rauschleveln. Effektiv verhalten sich die Quantenfehler wie eine Form der Regularisierung, die aus dem klassischen Deep Learning vertraut ist, etwa Dropout — sie lenken das System von empfindlichen Lösungen weg und hin zu einfacheren, robusteren Architekturen.
Was das für die Zukunft des Quantenlernens bedeutet
Für Nicht‑Spezialisten lautet die Kernbotschaft: Die heutigen unvollkommenen Quantenmaschinen könnten bereits nützliche Partner für klassische KI sein, insbesondere wenn ihre Schwächen als Bestandteil der Entwurfsstrategie betrachtet werden und nicht als Störfaktor, den man ignorieren muss. Diese Arbeit zeigt, dass ein sorgfältig gestaltetes hybrides Modell die medizinische Vorhersagegenauigkeit nahezu unverändert halten kann, während es weniger Quantenressourcen nutzt und unter realistischem Rauschen deutlich schneller trainiert. Anstatt auf perfekt ruhige Quantenhardware zu warten, könnten Forschende moderates Rauschen als hilfreiche Zutat nutzen, um schlankere Modelle zu lenken, die leichter zu trainieren und in realen Anwendungen einzusetzen sind.
Zitation: Bravo-Montes, J.A., Martín-Toledano, A., Velasco-Gallego, C. et al. Design of a hybrid quantum machine learning architecture and analysis of quantum noise effects. Sci Rep 16, 13496 (2026). https://doi.org/10.1038/s41598-026-42216-5
Schlüsselwörter: Quanten‑Machine‑Learning, hybride neuronale Netze, Quantenrauschen, Brustkrebs‑Erkennung, noisy intermediate‑scale quantum