Clear Sky Science · pl
Projekt hybrydowej architektury uczenia maszynowego kwantowego i analiza wpływu szumów kwantowych
Dlaczego dodanie szumu do komputerów kwantowych może pomóc
Dzisiejsze komputery kwantowe są w teorii potężne, ale w praktyce niedoskonałe: ich delikatne kubity są stale zakłócane przez szum, co zwykle pogarsza wydajność. W tym badaniu pojawia się zaskakujące pytanie: czy część tego szumu można faktycznie obrócić na korzyść? Autorzy projektują system hybrydowy, który miesza niewielki obwód kwantowy z konwencjonalną siecią neuronową, i badają, jak realistyczne poziomy szumu wpływają na jego zdolność wykrywania raka piersi na podstawie danych medycznych.
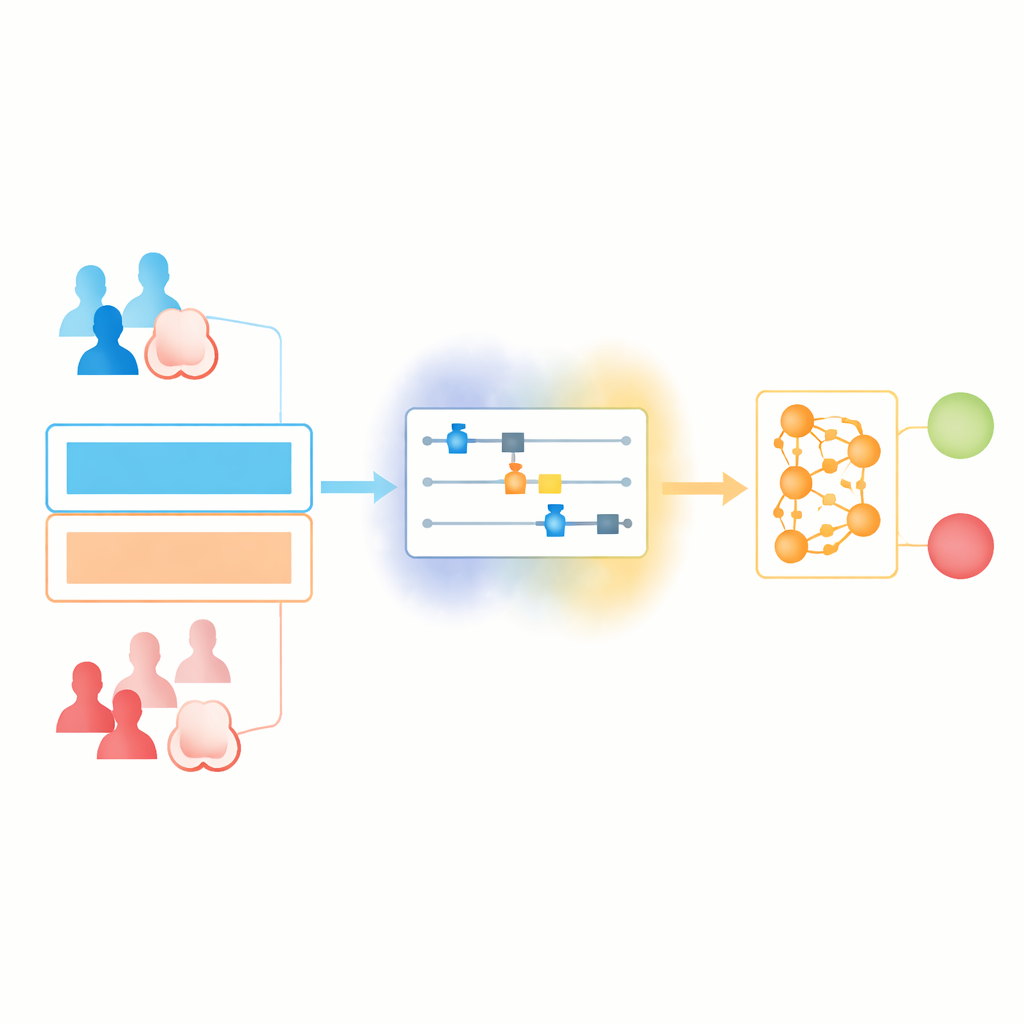
Mieszanie dwóch światów: uczenie kwantowe i klasyczne
Naukowcy budują „hybrydowy” pipeline uczenia, który pozwala częściom kwantowym i klasycznym robić to, co robią najlepiej. Najpierw zwykłe rekordy medyczne są oczyszczane i normalizowane tak, by każda wartość mieściła się w określonym przedziale. Te liczby są następnie podawane do kompaktowego obwodu kwantowego, gdzie każda cecha jest kodowana na zestawie kubitów przy użyciu starannie dobranych rotacji. Kubity są krótko splątane i przetwarzane, a następnie mierzone, aby wygenerować nowy zestaw liczb. Stają się one wejściem do standardowej sieci neuronowej, która wydaje końcową decyzję tak/nie dotyczącą raka.
Uczenie modelu kwantowego w zaszumionym świecie
Zamiast udawać, że sprzęt kwantowy jest doskonały, zespół jawnie wprowadza szum do procesu trenowania. Używają emulatora wysokiej wierności urządzeń nadprzewodzących i wstrzykują realistyczne błędy na trzech kluczowych etapach: przy inicjalizacji kubitów, przy stosowaniu bramek kwantowych oraz przy pomiarach. Natężenia szumu pochodzą z danych kalibracyjnych reprezentujących obecne urządzenia, ambitnego celu bliskiej przyszłości oraz przyszłej „listy życzeń” z jeszcze niższymi współczynnikami błędów. Pozwala to zbadać, jak ta sama architektura uczenia zachowuje się w miarę stopniowej poprawy technologii kwantowej.
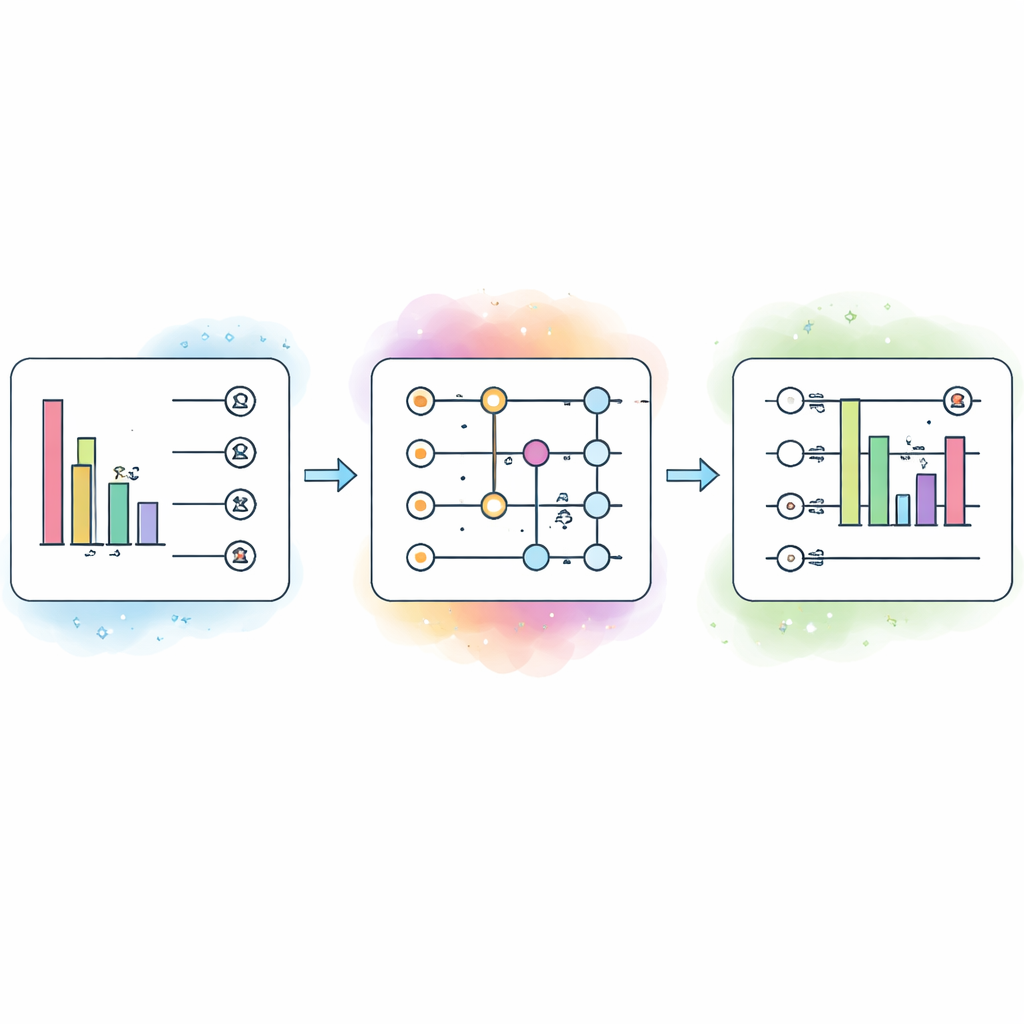
Dane o raku piersi jako test w warunkach rzeczywistych
Aby sprawdzić, czy to rozwiązanie jest praktyczne, autorzy testują je na trzech publicznych zbiorach danych o raku piersi, które różnią się wielkością i trudnością. Jeden zawiera stosunkowo ograniczone informacje, inny obejmuje wiele nakładających się lub redundantnych sygnałów, a trzeci jest dobrze dopasowany do wykrywania wyraźnych wzorców. Dla każdego zbioru danych zmieniają liczbę kubitów i poziom szumu, a następnie śledzą, jak zmieniają się dokładność i czas treningu. Aby porównanie było uczciwe, zaczynają od wspólnej konstrukcji bazowej, a następnie systematycznie regulują tylko rozmiar kwantowy i klasyczne hiperparametry, takie jak współczynnik uczenia, liczba warstw i funkcje aktywacyjne.
Gdy wystarcza mniej kubitów — i więcej szumu
Wyniki podważają intuicję, że więcej kubitów i mniej szumu zawsze prowadzą do lepszych modeli. W kilku przypadkach najlepsze konfiguracje z szumem osiągają w zasadzie taką samą dokładność jak wersje idealizowane, wolne od szumu, przy użyciu mniejszej liczby kubitów. Na przykład, w zależności od zbioru danych, szczytowa wydajność jest osiągana przy zaledwie dwóch do siedmiu kubitów, gdy uwzględniony jest realistyczny szum, w porównaniu z większymi obwodami kwantowymi w przypadku braku szumu. Ponieważ koszt symulacji, a ostatecznie rzeczywistego wykonania, rośnie szybko z każdym dodatkowym kubitem, to zmniejszenie przekłada się na duże oszczędności w czasie trenowania — przyspieszenia od około 1,6‑krotnego do ponad 4‑krotnego, bez poświęcania istotnej mocy predykcyjnej.
Szum jako wbudowane zabezpieczenie przed przeuczeniem
Analizując uważniej ewolucję błędów treningowych i walidacyjnych, autorzy stwierdzają, że całkowicie bezszumowe warstwy kwantowe mają tendencję do przeuczania się: zbyt dobrze uczą się osobliwości danych treningowych i nie potrafią uogólniać. Gdy występuje umiarkowany szum, modele często osiągają nieco wyższą dokładność na walidacji i bardziej stabilne krzywe strat, zwłaszcza przy najlepiej dobranych poziomach szumu. W efekcie błędy kwantowe zachowują się jak forma regularizacji znana z klasycznego deep learningu, taka jak dropout, odciągając system od kruchego dopasowania na rzecz prostszych, bardziej odpornych architektur.
Co to oznacza dla przyszłości uczenia kwantowego
Dla osoby niebędącej specjalistą główne przesłanie jest takie, że niedoskonałe dzisiejsze maszyny kwantowe mogą już być użytecznymi partnerami dla klasycznego AI, szczególnie jeśli ich wady traktuje się jako część projektu, a nie jako uciążliwość, którą należy zignorować. Praca ta pokazuje, że starannie skonstruowany model hybrydowy może utrzymać dokładność predykcji medycznej niemal niezmienioną, używając przy tym mniejszej liczby zasobów kwantowych i trenując znacznie szybciej w realistycznych warunkach szumowych. Zamiast czekać na idealnie ciche układy kwantowe, badacze mogą być w stanie wykorzystać umiarkowany szum jako pomocny składnik, prowadząc do smuklejszych modeli, łatwiejszych do trenowania i wdrożenia w zastosowaniach rzeczywistych.
Cytowanie: Bravo-Montes, J.A., Martín-Toledano, A., Velasco-Gallego, C. et al. Design of a hybrid quantum machine learning architecture and analysis of quantum noise effects. Sci Rep 16, 13496 (2026). https://doi.org/10.1038/s41598-026-42216-5
Słowa kluczowe: kwantowe uczenie maszynowe, hybrydowe sieci neuronowe, szum kwantowy, wykrywanie raka piersi, noisy intermediate-scale quantum