Clear Sky Science · it
Progettazione di un’architettura ibrida di quantum machine learning e analisi degli effetti del rumore quantistico
Perché aggiungere rumore ai computer quantistici potrebbe aiutare
I computer quantistici odierni sono potenti in teoria ma disordinati in pratica: i loro delicati bit quantistici sono continuamente disturbati dal rumore, che di solito peggiora le prestazioni. Questo studio pone una domanda sorprendente: parte di quel rumore può essere trasformata in un vantaggio? Gli autori progettano un sistema ibrido che fonde un piccolo circuito quantistico con una rete neurale convenzionale e testano come livelli realistici di rumore influenzino la sua capacità di rilevare il cancro al seno a partire da dati medici.
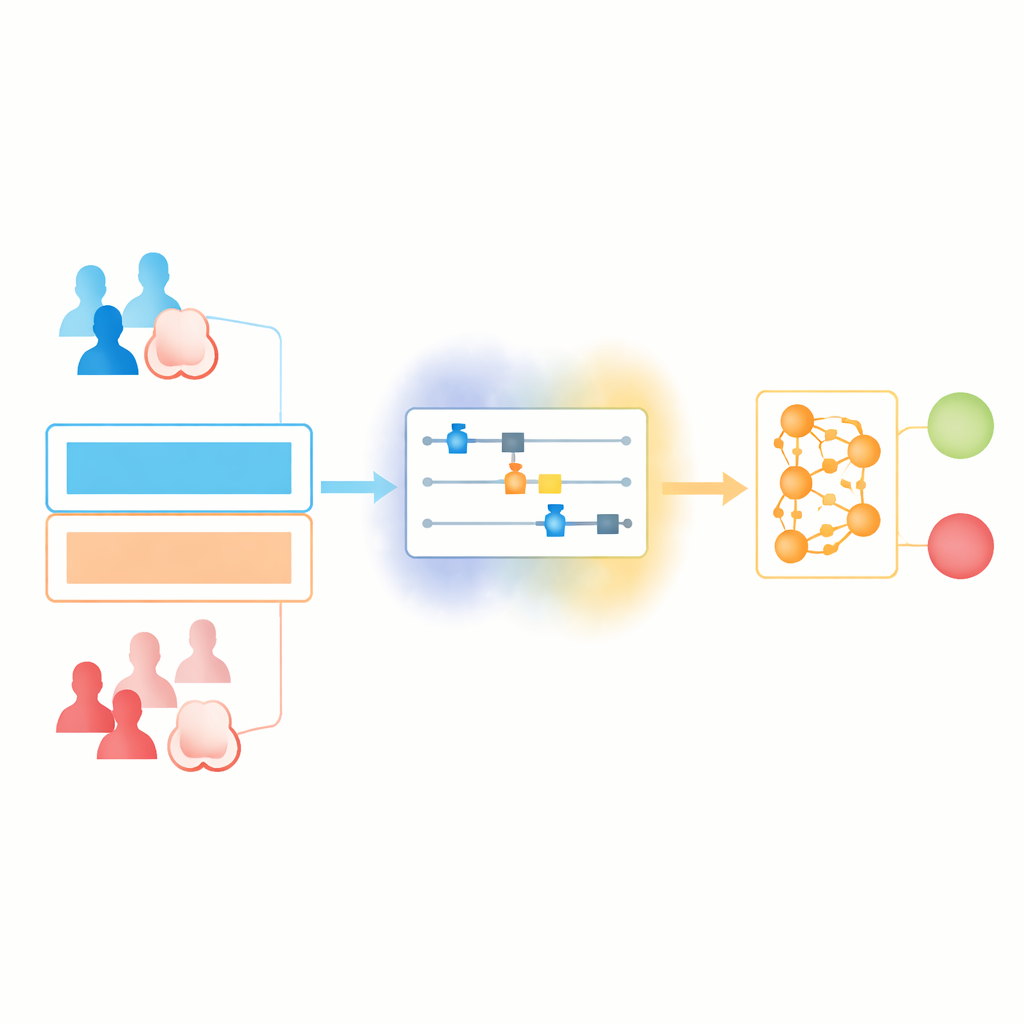
Fondere due mondi: apprendimento quantistico e classico
I ricercatori costruiscono una pipeline di apprendimento “ibrida” che consente alle parti quantistiche e classiche di fare ciascuna ciò che sanno fare meglio. Innanzitutto, i normali referti medici vengono puliti e normalizzati in modo che ogni numero rientri in un intervallo fisso. Questi valori vengono poi inseriti in un compatto circuito quantistico, dove ogni caratteristica viene codificata su un insieme di qubit mediante rotazioni scelte con cura. I qubit vengono brevemente intrecciati e trasformati, quindi misurati per produrre un nuovo insieme di numeri. Questi diventano l’input di una rete neurale standard, che fornisce la predizione finale sì/no sulla presenza di cancro.
Addestrare un modello quantistico in un mondo rumoroso
Invece di fingere che l’hardware quantistico sia perfetto, il team integra esplicitamente il rumore nel processo di addestramento. Usano un emulatore ad alta fedeltà di dispositivi quantistici superconduttori e iniettano errori realistici in tre fasi chiave: quando i qubit vengono inizializzati, quando vengono applicate le porte quantistiche e quando vengono effettuate le misurazioni. Le intensità del rumore sono prese da dati di calibrazione che rappresentano dispositivi attuali, un ambizioso obiettivo a breve termine e una “wish list” futura con tassi di errore ancora più bassi. Questo permette di esplorare come la stessa architettura di apprendimento si comporti man mano che la tecnologia quantistica migliora gradualmente.
I dati sul cancro al seno come banco di prova reale
Per valutare se questa impostazione è utile in pratica, gli autori la testano su tre dataset pubblici sul cancro al seno che differiscono per dimensione e difficoltà. Uno contiene informazioni relativamente limitate, un altro presenta molti segnali sovrapposti o ridondanti e il terzo è ben adatto per apprendere pattern chiari. Per ogni dataset variano il numero di qubit e la quantità di rumore, poi monitorano come cambiano accuratezza e tempo di addestramento. Per mantenere il confronto equo, partono da un design di base comune e poi regolano sistematicamente solo la dimensione quantistica e gli iperparametri classici come learning rate, numero di layer e funzioni di attivazione.
Quando pochi qubit — e più rumore — bastano
I risultati sfidano l’intuizione secondo cui più qubit e meno rumore portano sempre a modelli migliori. In diversi casi, le migliori configurazioni con rumore raggiungono essenzialmente la stessa accuratezza delle versioni idealizzate senza rumore pur usando meno qubit. Per esempio, a seconda del dataset, la performance di picco viene raggiunta con appena due‑sette qubit quando è incluso il rumore realistico, rispetto a circuiti quantistici più grandi nel caso senza rumore. Poiché il costo di simulazione e, in futuro, dell’esecuzione reale cresce rapidamente con ogni qubit aggiuntivo, questa riduzione si traduce in grandi risparmi nei tempi di addestramento — accelerazioni che vanno circa da 1,6× a oltre 4× — senza sacrificare una reale capacità predittiva.
Il rumore come paracadute integrato contro l’overfitting
Esaminando più da vicino l’evoluzione degli errori di addestramento e validazione, gli autori rilevano che gli strati quantistici completamente privi di rumore tendono a overfittare: apprendono troppo i difetti del set di addestramento e non generalizzano. Quando è presente un rumore moderato, i modelli spesso raggiungono una accuratezza di validazione leggermente più alta e curve di perdita più stabili, specialmente per i livelli di rumore meglio tarati. Di fatto, gli errori quantistici si comportano come una forma di regolarizzazione nota dal deep learning classico, come il dropout, spingendo il sistema lontano da soluzioni fragili e verso architetture più semplici e robuste.
Cosa significa per il futuro dell’apprendimento quantistico
Per un non specialista, il messaggio principale è che le macchine quantistiche imperfette di oggi potrebbero già essere partner utili per l’IA classica, soprattutto quando i loro difetti sono trattati come parte del progetto anziché come un fastidio da ignorare. Questo lavoro mostra che un modello ibrido accuratamente progettato può mantenere pressoché invariata l’accuratezza delle predizioni mediche pur utilizzando meno risorse quantistiche e addestrando molto più rapidamente in presenza di rumore realistico. Invece di aspettare hardware quantistico perfettamente silenzioso, i ricercatori potrebbero riuscire a sfruttare un rumore moderato come ingrediente utile, guidando modelli più snelli che sono più facili da addestrare e distribuire in applicazioni reali.
Citazione: Bravo-Montes, J.A., Martín-Toledano, A., Velasco-Gallego, C. et al. Design of a hybrid quantum machine learning architecture and analysis of quantum noise effects. Sci Rep 16, 13496 (2026). https://doi.org/10.1038/s41598-026-42216-5
Parole chiave: quantum machine learning, reti neurali ibride, rumore quantistico, rilevazione del cancro al seno, quantistico di scala intermedia rumoroso