Clear Sky Science · sv
Tillämpning av släta OWA-operatörer för klassificering av retinitis pigmentosa
Varför detta spelar roll för synen
Att långsamt förlora synen på grund av en ärftlig ögonsjukdom är en skrämmande utsikt, och tidig diagnos av dessa tillstånd är avgörande för att bevara synen. Denna studie undersöker hur modern artificiell intelligens kan hjälpa läkare att skilja mellan flera sällsynta men allvarliga näthinnesjukdomar, inklusive retinitis pigmentosa, med hjälp av detaljerade fotografier av ögats baksida. Genom att hitta ett smartare sätt att kombinera bedömningarna från många olika datorprogram visar forskarna att datorer kan upptäcka dessa sjukdomar mycket mer tillförlitligt än tidigare, även när endast ett litet antal patientbilder finns tillgängliga.
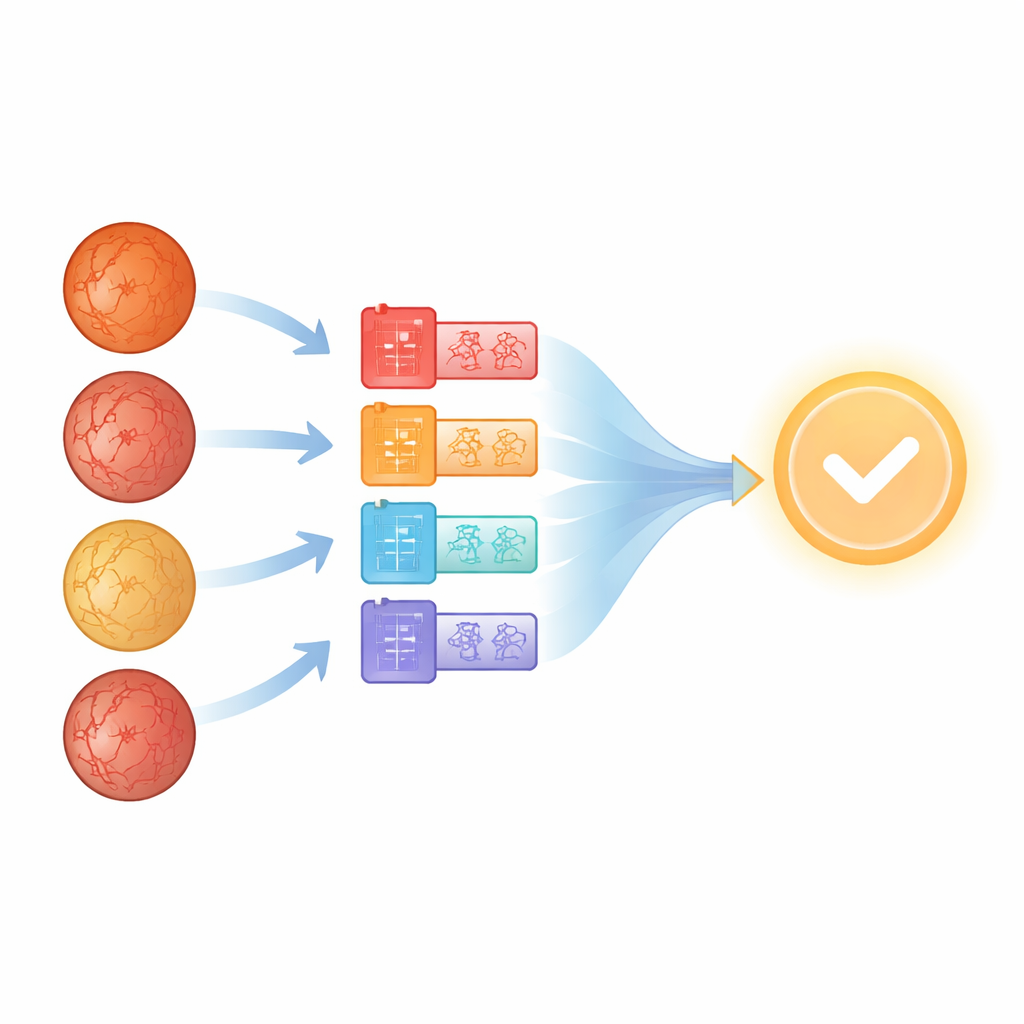
Att se sjukdom i ögonfoton
Retinitis pigmentosa är en grupp genetiska tillstånd som gradvis förstör de ljuskänsliga cellerna i näthinnan. Personer märker ofta först svårigheter att se i mörker, förlorar sedan sidoseendet och vissa blir så småningom blinda. Besläktade störningar, såsom cone-rod-dystrofi och Ushers syndrom, kan se lika ut på ögonbilder och kan dela subtila visuella mönster. I denna studie samlade specialister vid ett medicinskt centrum i Lublin, Polen, ultra-widefield-bilder av näthinnan från 186 patienter med dessa tillstånd, tillsammans med bilder från friska ögon hämtade från en separat databas. Resultatet blev en femvägs-klassificeringsuppgift: två genetiska varianter av retinitis pigmentosa, cone-rod-dystrofi, Ushers syndrom och friska kontroller. Datasetet var litet och obalanserat, vilket speglar verklig sällsynthet—vissa kategorier hade många fler exempel än andra, vilket gjorde uppgiften särskilt utmanande.
Att lära maskiner läsa näthinnan
För att tolka dessa bilder använde författarna kraftfulla bildigenkänningssystem som ursprungligen utvecklats för vardagsfotografier: konvolutionella neurala nätverk och nyare transformerbaserade modeller. De testade flera arkitekturer, inklusive EfficientNet, ResNet, VGG, Inception och två versioner av Vision Transformer. Varje nätverk tränades först på en stor allmän bilddatabas och finjusterades sedan på näthinnebilderna, en strategi känd som transfer learning. Standardmetoder för dataaugmentation, som att vända, rotera och lätt förvränga bilderna, hjälpte modellerna att hantera skillnader i avbildningsenheter och patientanatomi. Även med dessa avancerade tekniker klassificerade den bästa enskilda modellen bara omkring två tredjedelar av testfallen korrekt, och prestandan var märkbart sämre för de mest sällsynta sjukdomskategorierna.
Låta många modeller rösta tillsammans
I stället för att lita på ett enda nätverk frågade forskarna nästa: vad händer om vi behandlar varje modell som en expert i en panel och kombinerar deras åsikter? Denna idé, kallad aggregering eller ensemblelärande, är vanlig inom maskininlärning men implementeras ofta med enkel omröstning eller medelvärdesbildning. Här använde teamet en mer flexibel verktygsfamilj känd som Ordered Weighted Averaging (OWA)-operatorer. För varje möjlig diagnos tar OWA de sannolikheter som producerats av alla nätverk, sorterar dem från högst till lägst och blandar dem sedan med en noga utvald uppsättning vikter. I praktiken ger det mer inflytande åt modeller som är mer säkra, samtidigt som resten fortfarande beaktas. Denna aggregering ensam gav ett dramatiskt hopp i total noggrannhet, från ungefär 68 % för den bästa individuella modellen till över 93 % när nätverkens utdata kombinerades med en grundläggande OWA-schem.
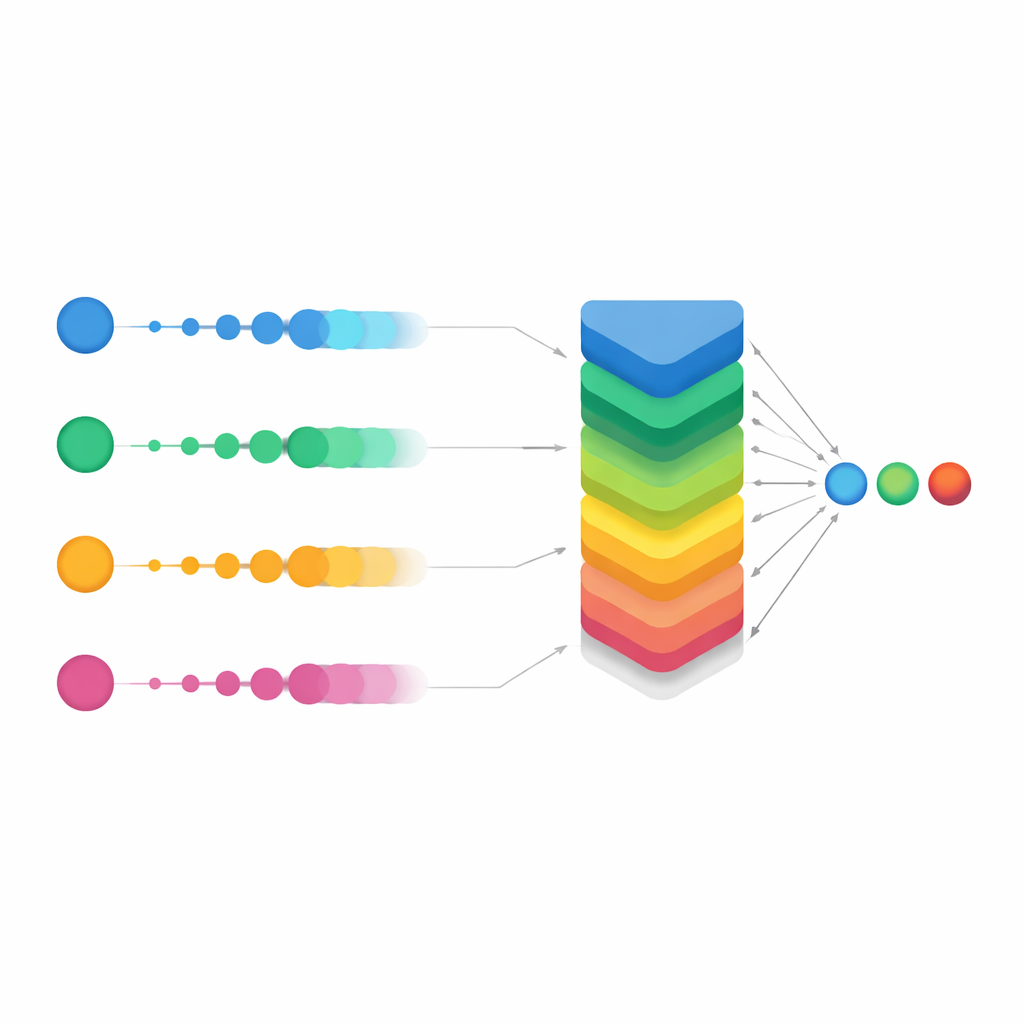
Att jämna ut omröstningen för svåra fall
Studien huvudsakliga innovation var en förfinad version kallad Smooth OWA. I stället för att betrakta varje modells sannolikhet isolerat, "jämnar" Smooth OWA varsamt varje värde med hjälp av dess grannar innan den viktade blandningen tillämpas. Utjämningsreglerna är lånade från klassiska numeriska integrationsformler, kända som Newton–Cotes-kvadraturer, som normalt används för precisa areaberäkningar. Översatt till detta sammanhang hjälper de att jämna ut instabila eller gränsfalliga prediktioner över modellerna. Medan den extra förbättringen jämfört med standard-OWA var måttlig—i storleksordningen en halv procentenhet i noggrannhet—var den konsekvent över upprepade tester och pressade prestandan till omkring 94 %. Avgörande var att förväxlingsmatriserna visade att felklassificeringar sjönk kraftigt över alla fem klasser, särskilt för de sällsyntaste sjukdomarna. I vissa grupper steg korrektigenkänningsgraderna från runt två tredjedelar med den bästa enskilda modellen till långt över 90 % med Smooth OWA.
Vad detta betyder för patienter och läkare
För en icke-specialist är huvudbudskapet att ingen enskild artificiell intelligensmodell behöver vara perfekt för att vara kliniskt användbar. Genom att noggrant kombinera flera bra men ofullständiga modeller och varsamt stabilisera deras utdata förvandlade forskarna en uppsättning "ganska bra" verktyg till ett mycket starkt beslutsstöd. Deras Smooth OWA-ansats hanterade ett litet, obalanserat dataset och uppnådde ändå prestandanivåer som annars vore svåra att nå. Även om arbetet fortfarande befinner sig i forskningsstadiet och behöver valideras i större, multicenterstudier innan det kan styra verklig patientvård, pekar det på en tydlig väg framåt: framtida diagnostiska system för sällsynta ögonsjukdomar kan förlita sig inte på en enskild algoritm, utan på ett koordinerat "råd" av algoritmer vars kollektiva omdöme är både mer exakt och mer pålitligt.
Citering: Rachwał, A., Rachwał, A., Powroźnik, P. et al. Application of smooth OWA operators to classification of retinitis pigmentosa. Sci Rep 16, 11995 (2026). https://doi.org/10.1038/s41598-026-41840-5
Nyckelord: retinitis pigmentosa, djupinlärning, retinal avbildning, ensemblemetoder, AI för medicinsk diagnostik